







0. 引言
论文提出三个要点:
(1). 大型公共数据集的建立:
- 这个数据集在人数上是现有数据集MS1M(MegaFace 1 Million)的20倍。
- 图像数量是MegaFace2数据集的10倍,MegaFace2是一个广泛认可的大规模人脸识别基准数据集。
(2). 新的评估协议:
- 提出了一个新的评估标准,这个标准特别考虑了推理时间。
- 在实际应用中,人脸识别系统的推理时间是一个关键因素,因为它影响用户体验和系统响应能力。
(3). 性能表现:
- 在IJB-C(Independent Test of the IARPA Janus Benchmark C)中取得了较高的最新技术水平(SOTA,State of the Art)成绩。
- 在NIST-FRVT(National Institute of Standards and Technology Face Recognition Vendor Test)中获得了第三名。
论文地址:https://arxiv.org/pdf/2103.04098.pdf
1.概述
到目前为止,在人脸识别领域,和其他领域一样,研究网络和损失以提高准确率是主流。然而,另一方面,缺乏大规模的数据集。尤其是缺乏公共数据集。
一些拥有私人大规模数据的公司可以利用大规模数据进行研究,而没有数据的学者目前则利用有限的公共数据进行研发。
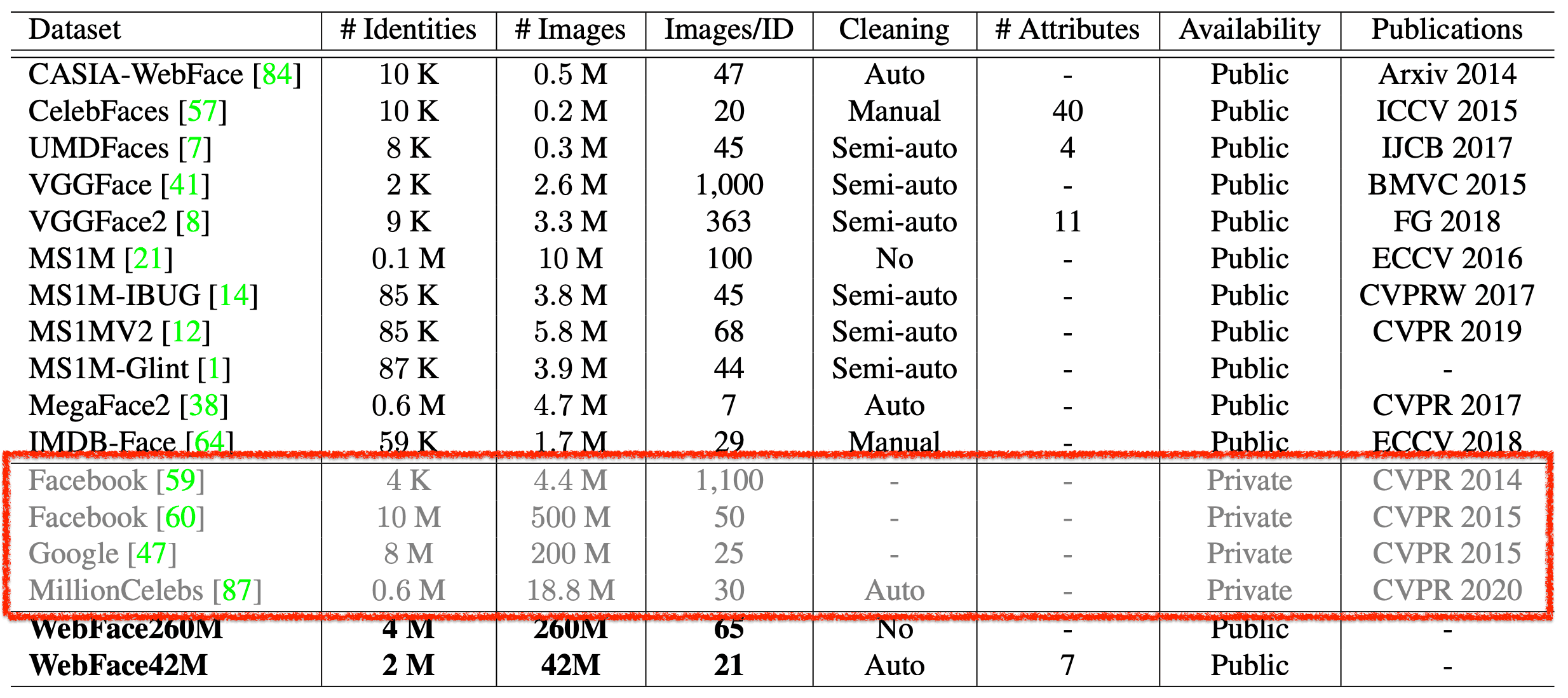
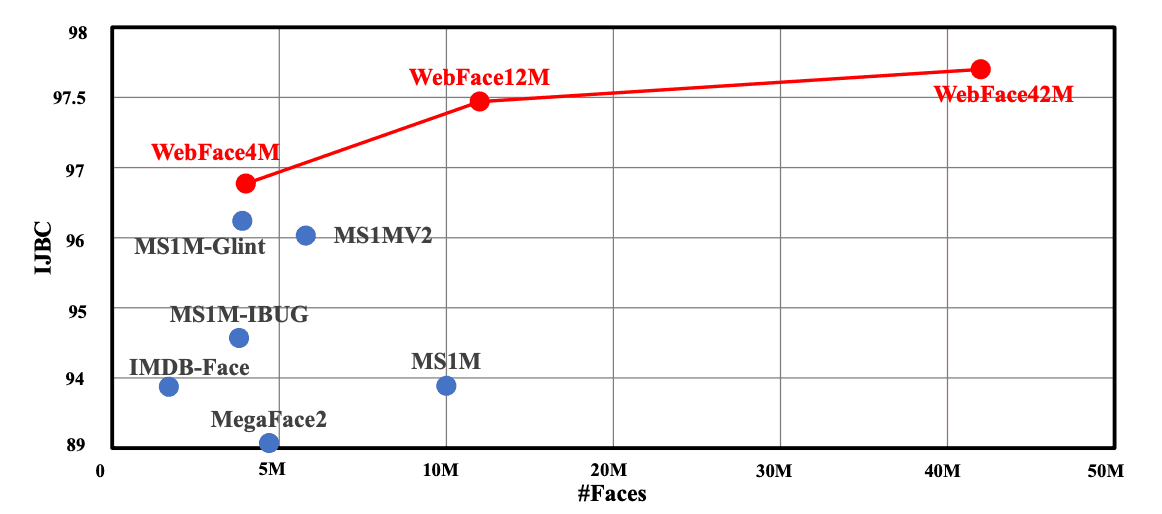
自然,人脸识别模型的训练数据越多,其性能就越高,但由于公共数据较少,模型的精度就会饱和。因此,在本文中,我们提供了两个新的大型Public数据集"WebFace260M"和"WebFace42M"。
,这些数据集与之前主流的大数据集MS1M和MegaFace2相比,在人数上增加了20倍,在图像数量上增加了10倍。
此外,在准备一个庞大的数据集时,不仅收集被试的难度大,而且随着数据量的增加,数据的清洗也很困难。因此,在本文中在本文中,我们提出了一种使用名为CAST的管道来实现自动数据清洗的方法。
另外,以往的数据集大多注重准确率的提升,但对于人脸识别来说,识别速度对于实际使用也是非常重要的。因此,在这个数据集中,我们还提出了一个名为FRUITS的协议,它将速度考虑在内。
在WebFace上训练的模型在IJB-C数据集上实现了SOTA,错误率降低了40%,在NIST-FRVT的430个模型中排名第三。这一结果消除了学术界和私人部门之间的数据差距,而且这两个越来越多。我们相信,这将是推进人脸识别研究的良好契机。
2.WebFace 260M/42M超大数据集
本项目提供的两个大型数据集是WebFace260M和WebFace42M。WebFace260M是通过大规模的WebFace与网络上收集的噪声生成的,然后通过一个名为CAST的管道自动清洗得到WebFace42M。
为了构建WebFace260M,我们首先从MS1M(由Freebase组成)和IMDB中获得4M人的名单。然后,我们使用谷歌图像搜索来检索图像。在图像检索时,10%的目标人物每人获得200张图像,20%的目标人物每人获得100张图像,30%的目标人物每人获得50张图像,40%的目标人物每人获得25张图像,共获取260M图像。
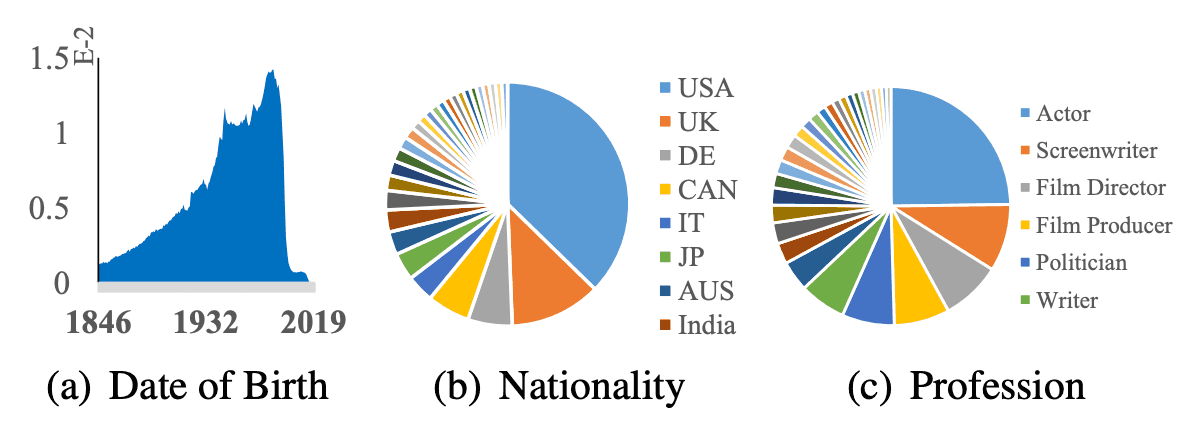
数据集的属性数据统计如下图所示。数据集由1846年后出生的200多个不同国家/地区的500多种不同职业组成,保证了数据集作为训练数据的多样性。
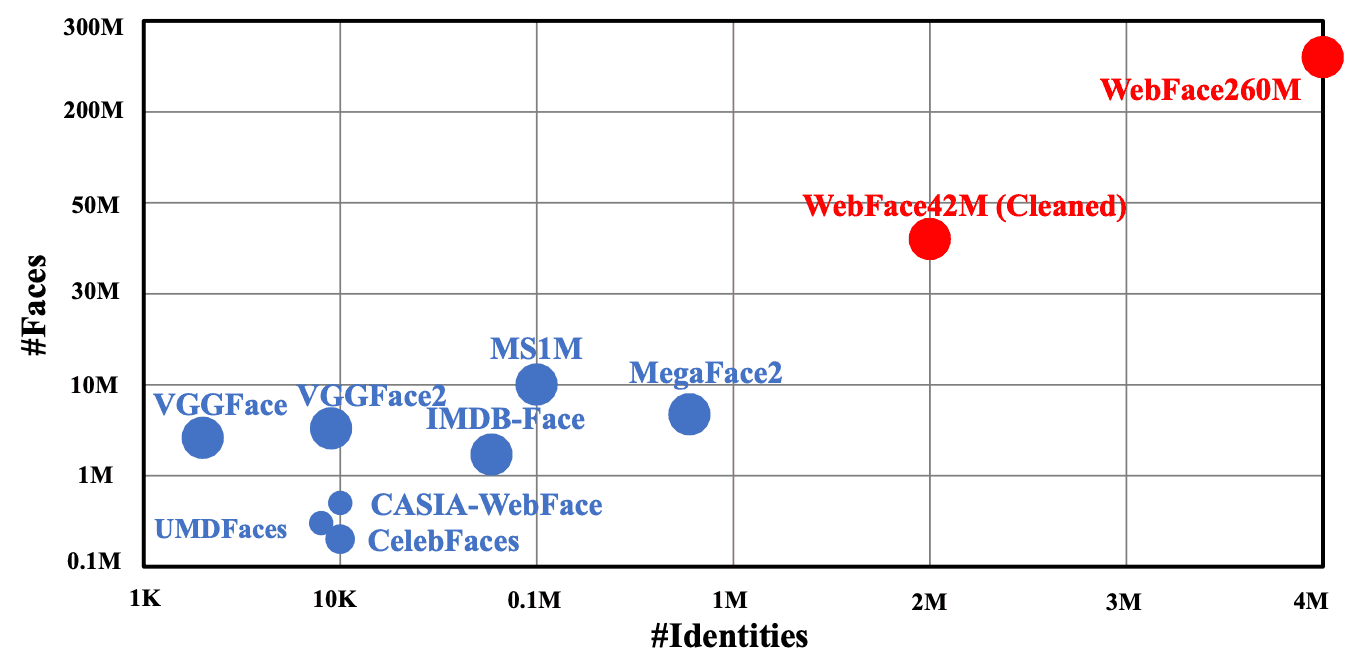
接下来,我们使用下面介绍的CAST来自动去除噪音。由此产生的WebFace42M是由2M人和42M图像构建而成。这个数据集包含每个人至少3张图片,平均21张图片。
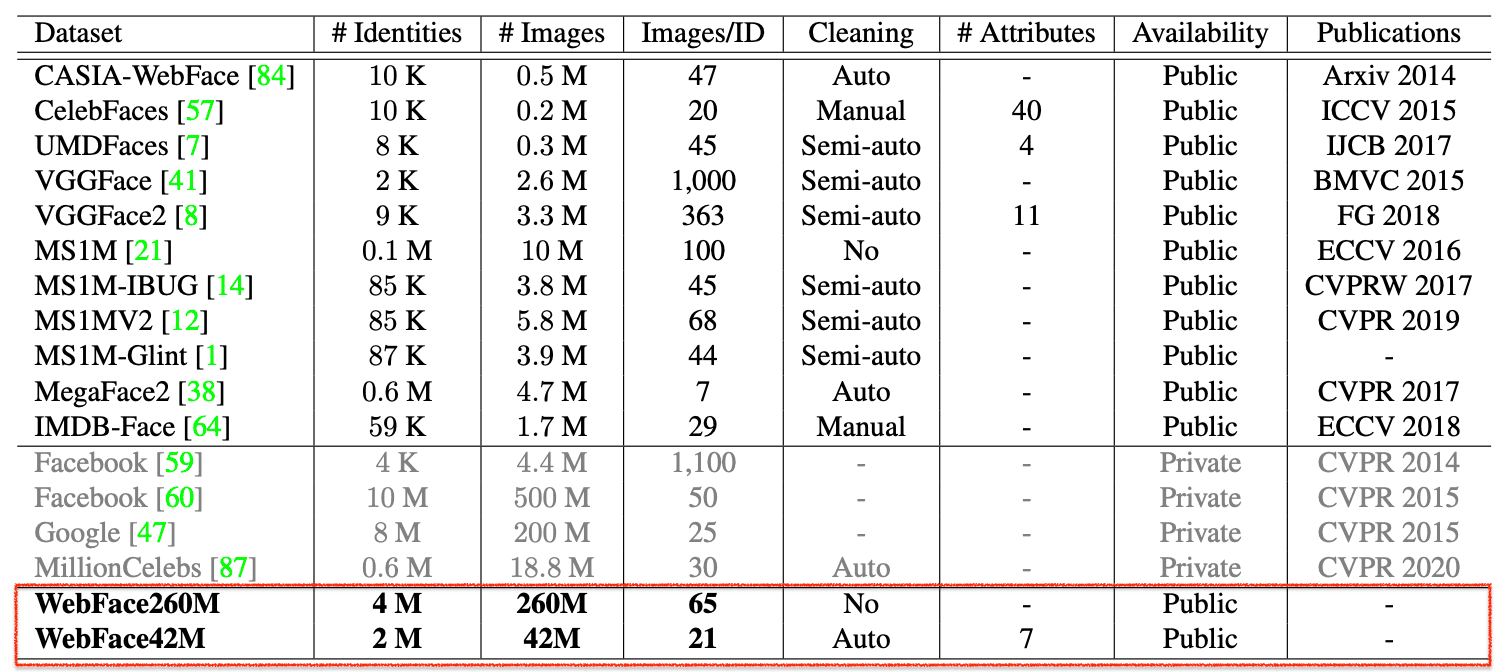
正如本文开头提到的,WebFace42M的ID是之前主流MS1M的3倍,图片是10倍,而MegaFace2的ID是20倍,图片是4倍。WebFace42M的噪声比例也小于10%,而MS1M的噪声比例约为50%,MegaFace2的噪声比例约为30%(取样结果)。
我们还提供了姿势、年龄、种族、性别、帽子、玻璃、面具等七种面部属性标签。具体来说,脸部方向、年龄和种族构成的比例如下图所示。
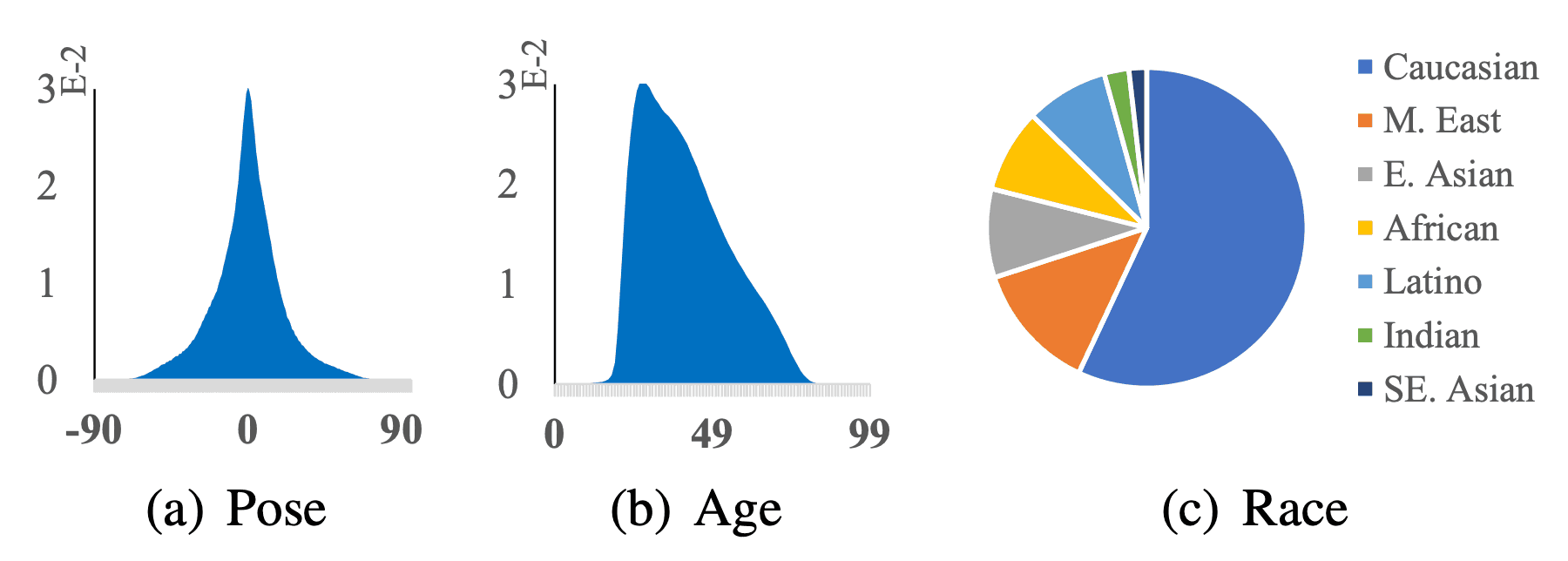
3. 自动清洗"CAST"
网络上收集的数据,因为它包含了大量的噪声数据。因此,有必要对数据进行清洗,建立高质量的数据集。用包含大量噪声的训练数据建立模型会降低性能。如上所述,作为WebFace260M的源头的MS1M,据说其噪声分数为50%。
已经使用了多种方法来清理已经构建的数据集。在VGGFace、VGGFace2和IMDB-Face中,清洗工作都是手动或半自动完成的,但人力比例很高,成本很高。这使得建立大型数据集非常困难。另外,MegaFace2还应用了自动清洗功能,但过程很复杂,据说即使应用了自动清洗功能,也会有远超过30%的噪音。
其他无监督方法和基于监督图的面部信息聚类方法也有研究,但这些都是假设整个数据集是有些复杂的,因此不适合WebFace260M,因为WebFace260M的噪声很大。
另一方面,最近研究了一种半监督学习的标准方法Self-Traning,可以显著提高图像分类的性能。
本文介绍CAST**(Cleaning**Automatically by Self-Training),如下图所示。然而,与闭集ImageNet分类不同,在开集人脸识别中直接生成伪标签并不实用。考虑到这一点,我们引入自转(CAST)管道就是为此而设计的。
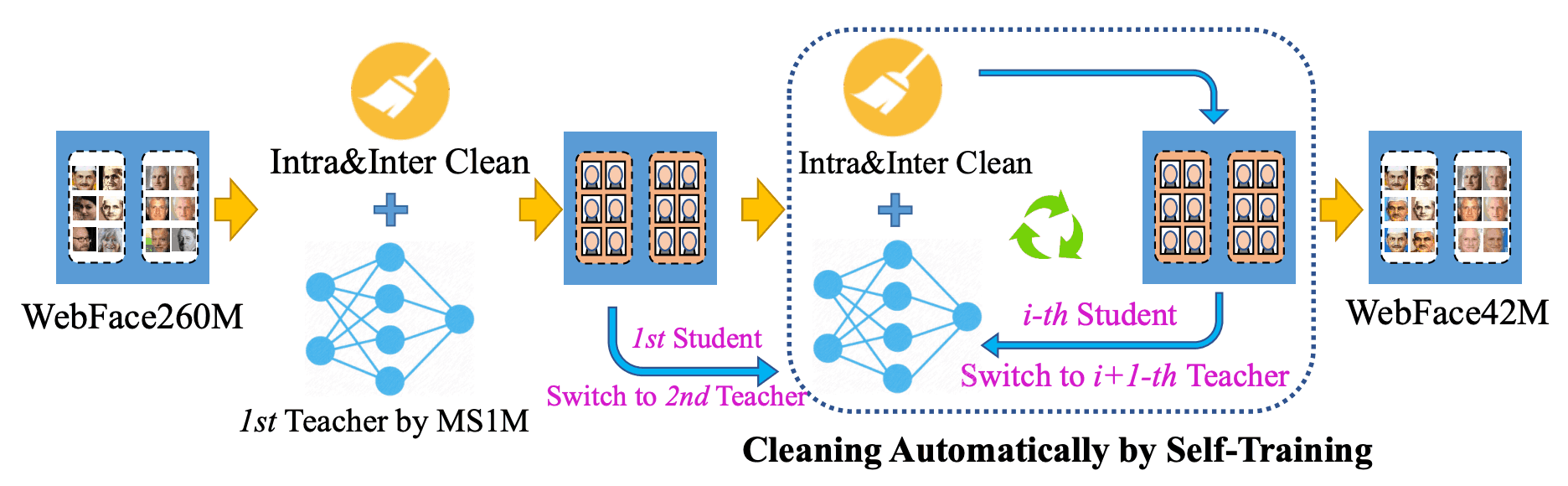
在CAST中,我们首先使用公共数据集MS1MV2来训练一个教师模型(ResNet100/ArcFace)来清理260M的类内/跨类图像。接下来,我们在这个清理过的数据集上训练一个学生模型(也是ResNet-100/ArcFace),并在类内/跨类进行清理。此后然后我们在学生模型和教师模型之间来回切换,直到得到一张高质量的42M图像。
CAST后,如果余弦相似度大于0.95,则认为受试者是相同的,删除重复的受试者。此外,每个主体特征的中心与关键基准(如LFW、FaceScrub、IJB-C)和本文拟建立的测试集(如下所述)进行比较,如果余弦相似度大于0.70,则作为重复的特征被删除。
CAST的迭代次数越高,就越干净,而ID和图片的数量越少,这些重复的东西就越多,最后我们得到了一个WebFace42M的205906个ID和42474558张图片。
4. FRUITS协议
FRUITS(Face Recognition Under Inference Time conStraint)是根据实际应用中的用例,在特定推理时间下评估性能的协议。
虽然已经提出了各种性能评估协议,如FRUITS(Face Recognition Under Inference Time conStraint),但考虑推理时间的模型很少。然而,这种观点很重要,特别是在使用轻量级模型时,例如在边缘使用的模型。
为了同样的目的,有人提出了轻量级人脸识别挑战。但它没有考虑到人脸识别所需的预处理,如人脸检测和人脸对齐,因此在考虑实际使用时,其性能评价受到一定限制。本文提出的FRUITS对人脸识别的一系列过程进行评估,包括人脸检测和人脸对齐。
NIST-FRVT也有类似的性能评估协议,但由于其要求,很难申请。在本文中,我们提出了一种新的协议,可以通过使用公共数据来方便地进行评估。
在这个FRUITS协议中,我们准备了三个条件。
- FRUITS-100
这是对人脸检测、人脸对齐、特征嵌入和匹配等一系列人脸识别过程在100毫秒内的性能评估。它主要用于对移动设备中实现的人脸识别系统进行基准测试。 - FRUITS-500这是对500ms内一系列人脸识别过程的性能评估。假设是以本地监控摄像头实现的人脸识别系统为基准。
- FRUITS-1000这是对1000ms内一系列人脸识别过程的性能评估。它旨在作为云端使用的人脸识别系统的基准。
这些推断时间是Intel Xeon CPUE5-2630-v4@2.20GHzによって計測されます。
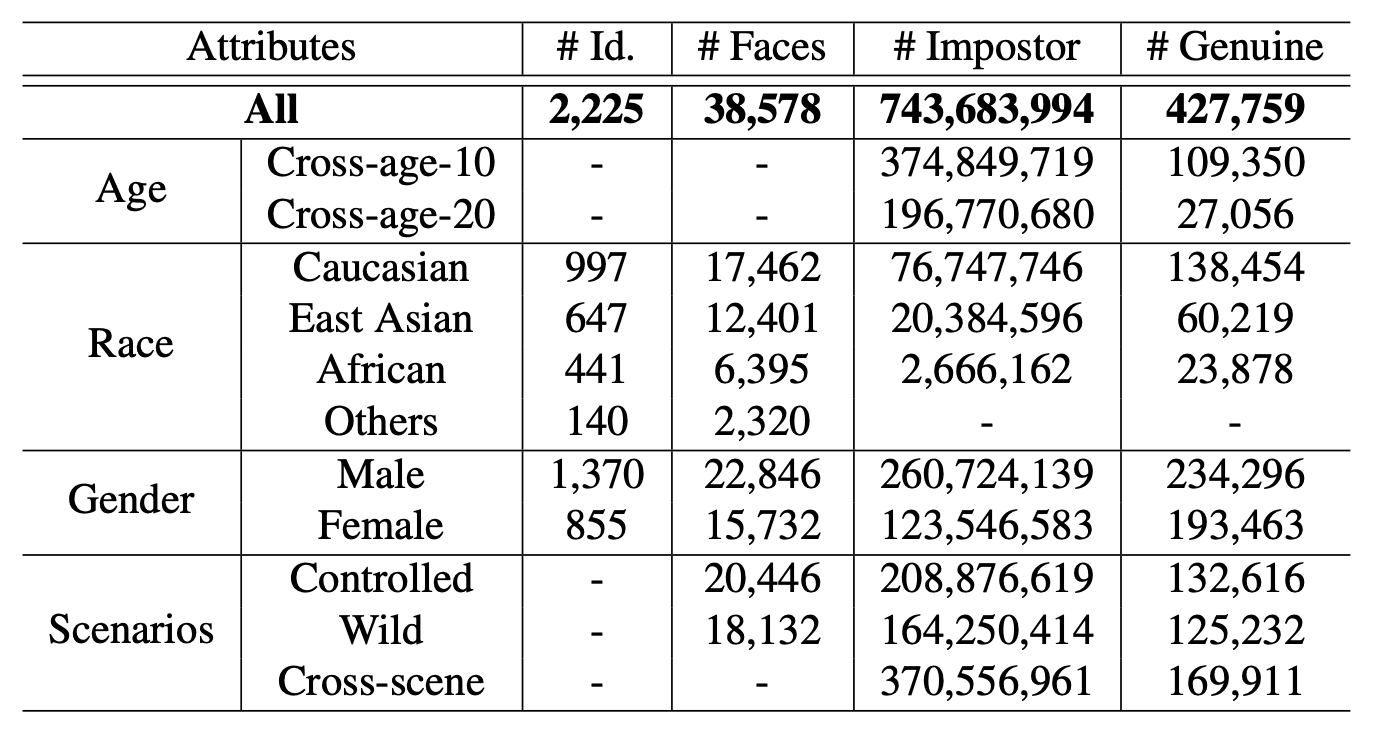
FRUITS提供了一套经过精心挑选的去掉噪音的更复杂的测试集。注释者在平衡属性信息的同时,手动选择高质量的图像。最后,测试集的统计结果如下表所示。总人数为2225人,总图片数为38578张。
性能评估是基于本FRUITS协议和下面描述的测试集来评估1:1验证的性能。我们使用虚假匹配率(FMR)和虚假非匹配率(FNMR)。在相同的FMR下,FNMR越低,说明性能越好。
5.总结
5.1 训练数据集的影响
为了研究新的训练数据的影响,我们在使用ResNet-100的基础上,应用主要的损失函数(ConFace/ArcFace/CurricularFace),并使用公共测试集进行对比验证。下表显示了在各种训练数据集(数据)上训练的模型和在各种测试数据集(对子)上测试的模型。/RFW/ RFWMega/IJB-C/Ours)。)
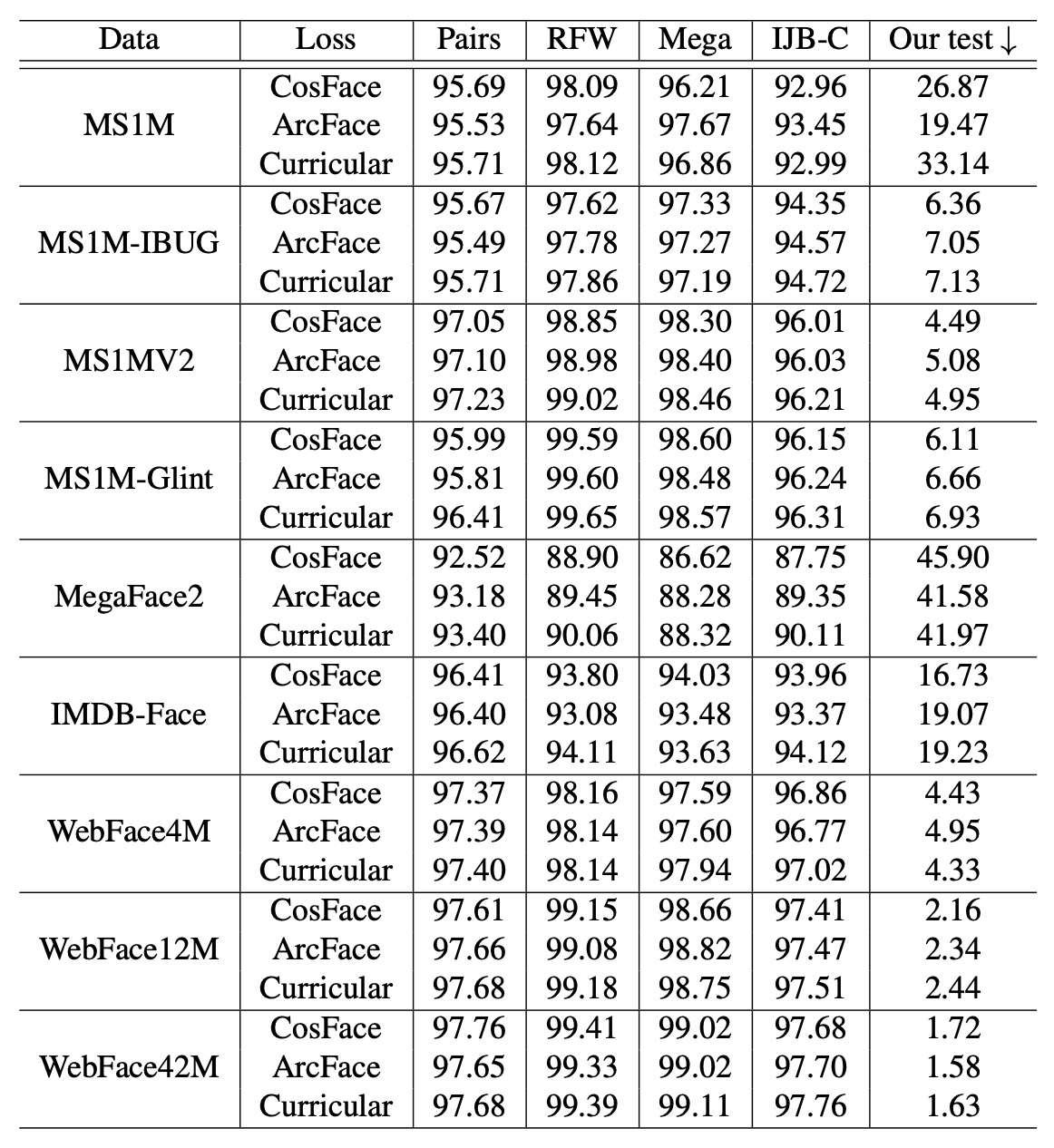
我们可以看到,用WebFace42M训练的模型表现出最高的性能。特别是与以IJB-C为测试数据的MS1MV2训练数据相比,TAR?(真实接受率)在FAR(False Accepte Rate)=1x10-4时,从96.03%提高到97.70%,错误率降低40%。
同样在WebFace中,对比4M、12M和42M,我们可以看到,随着数据量的增加,性能也在提升。
5.1 FRUITS协议的结果
我们用FRUITS协议评估其性能。下表是为本项目编制的基准清单。它展示了各种人脸识别系统,包括人脸检测(Det)、人脸对齐(Align)和人脸嵌入(Face Embedding)等模块及其推理速度(Time)。
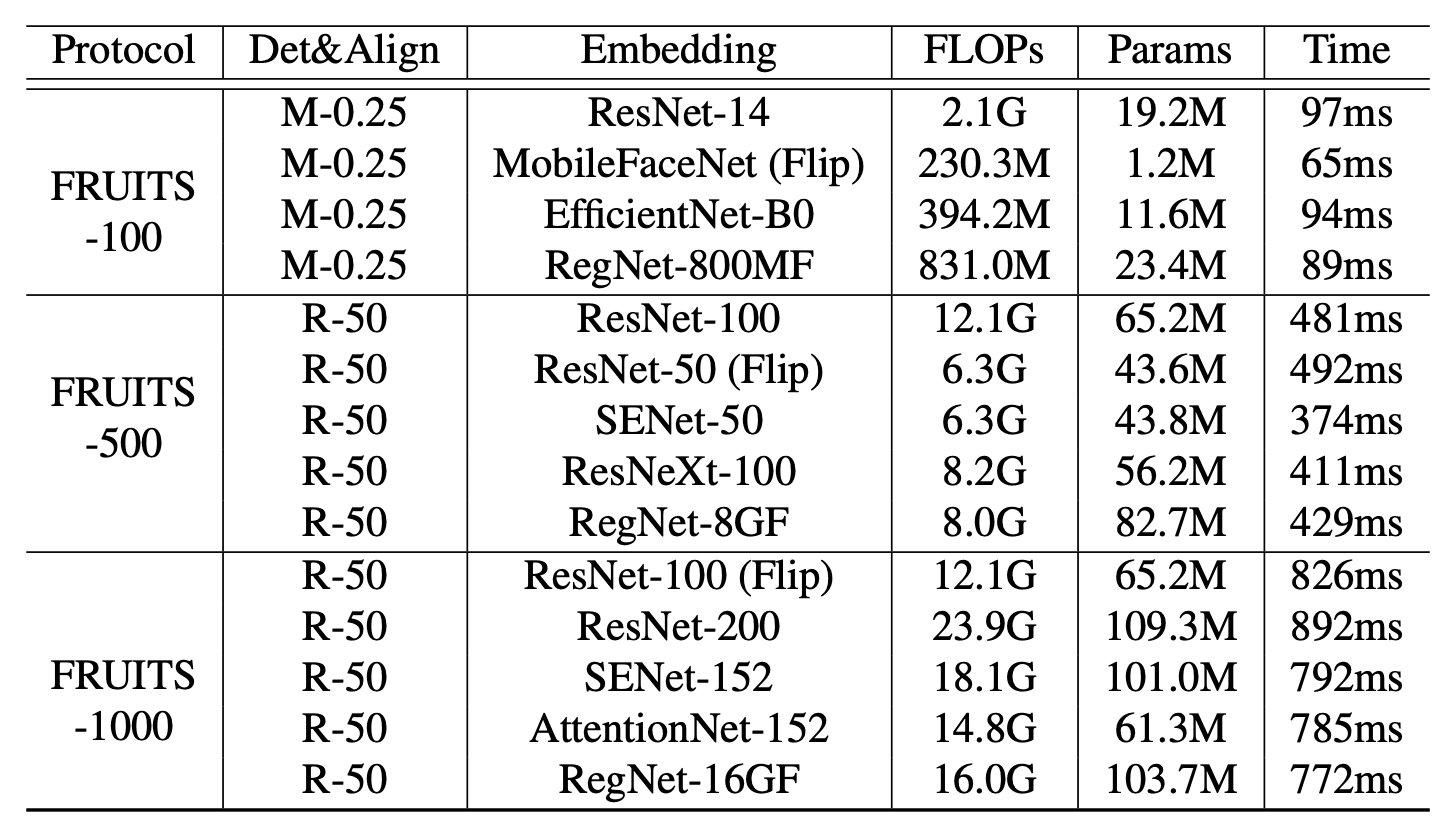
所有模型都应用ArcFace,并使用WebFace42M进行训练。对于Embedding,我们也应用了典型的网络架构,如MobileNet、EfficientNet、AttentionNet、ResNet、SENet和ResNeXt。
FRUITS-100的推理速度限制非常严格,所以我们用RetinaFace-MobileNet-0.25(M-0.25)来做Det&Align,用ResNet-14来做Embedding,用MobileFaceNet、EfficientNet-B0来做。RegNet-800MF等轻量级架构的应用。测试集中All的FNMR和属性偏差分析结果如下(a)和(b)所示。
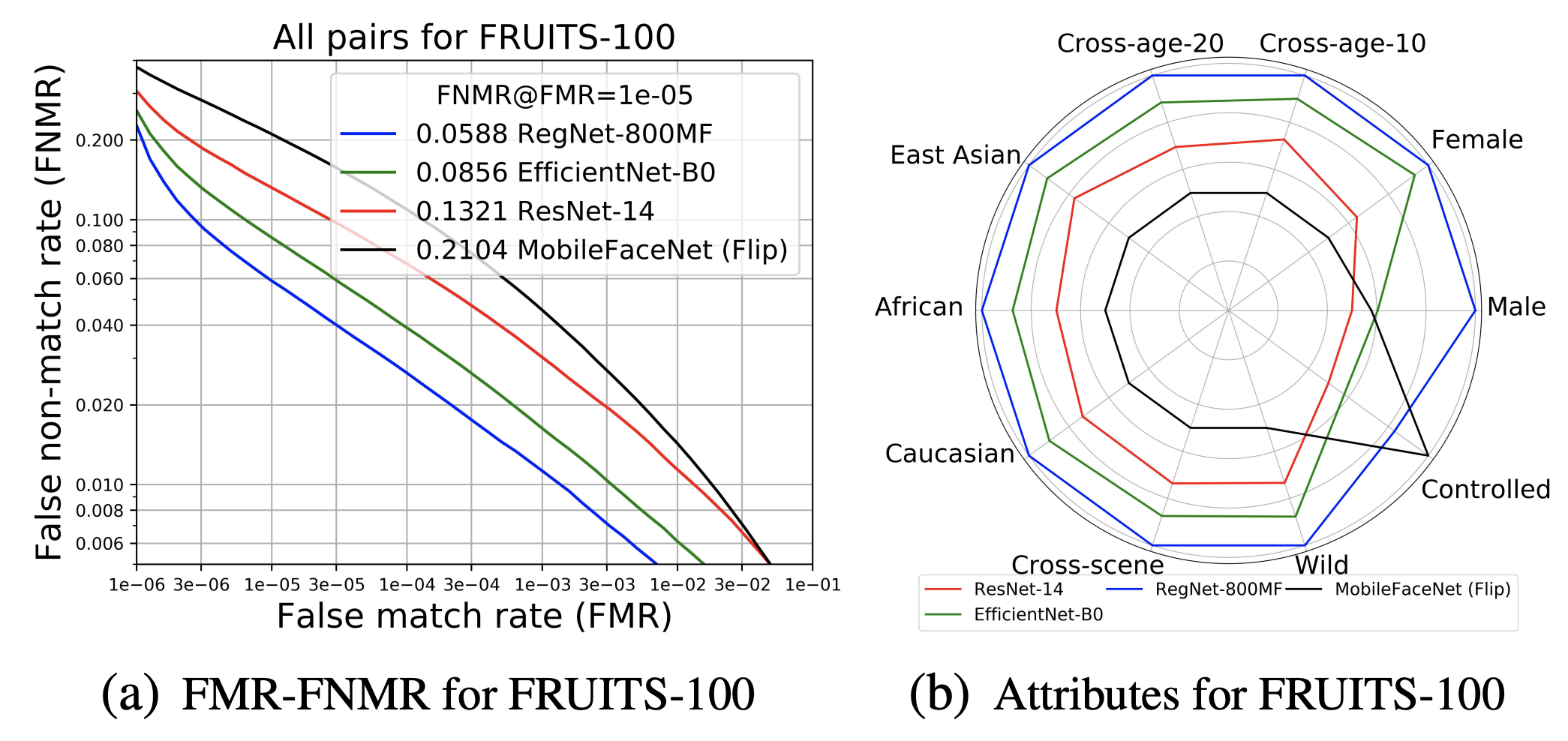
由于我们是在非常受限的条件下应用轻量级模型,最佳基线(RegNet800MF)给出了约5.88%的精度FNMR@FMR=1x10-5。可以说,FRUITS-100还有非常大的改进空间。
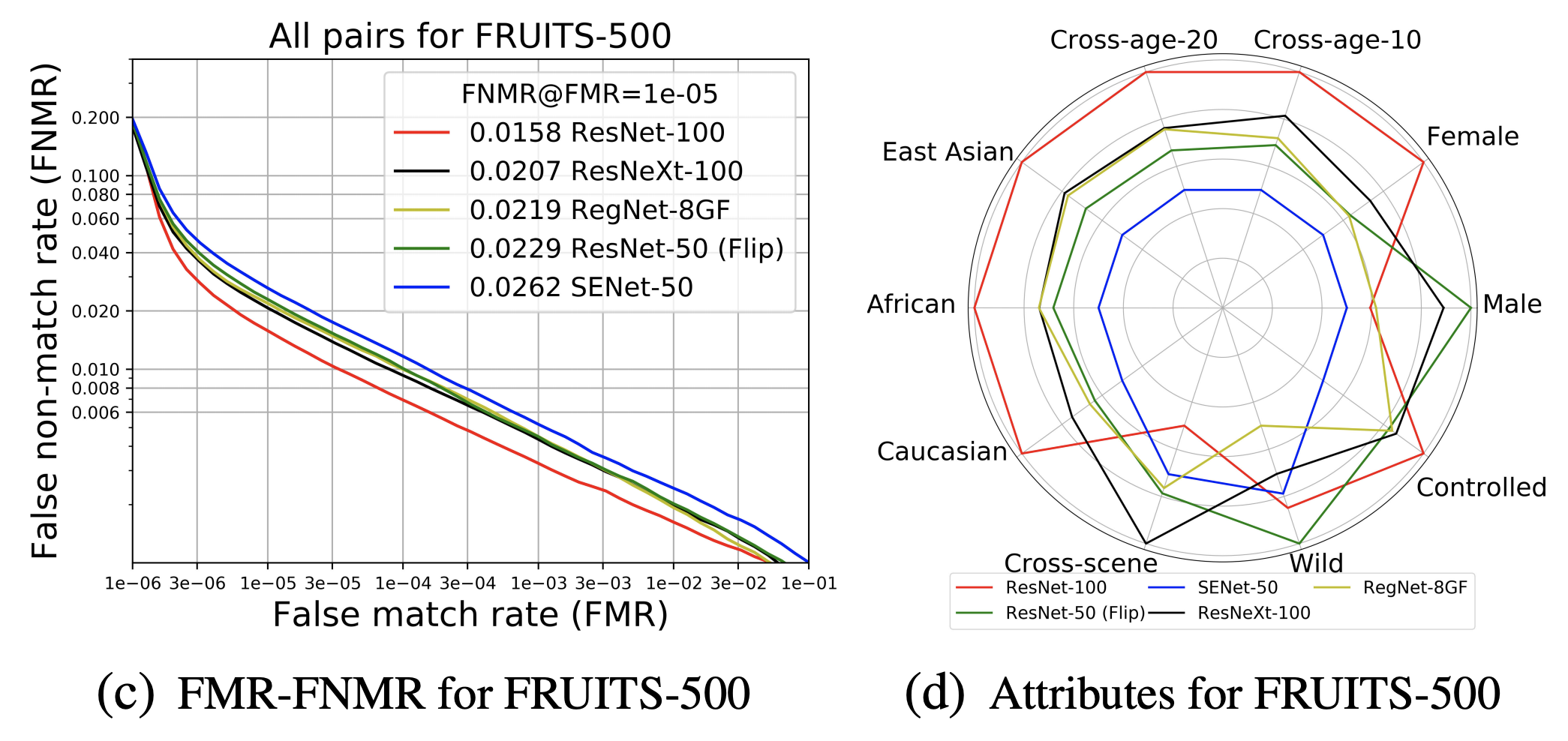
与FRUITS-100相比,FRUITS-500将能应用更高性能的模型。我们应用RetinaFace-ResNet-50(R-50)进行Det&Align、ResNet-100、ResNet-50、SENet-50、ResNeXt-100和RegNet-8GF进行嵌入。测试集中All的FNMR和属性偏差分析结果如下(c)和(d)所示。最佳基线(ResNet-100)显示了无偏差的最佳整体性能。
FRUITS-1000应用ResNet-100、ResNet-200、SENet-152、AttentionNet-152、RegNet-16GF进行嵌入。Te测试集中All的FNMR和属性偏差分析结果如下(e)和(f)所示。
5.1 NIST-FRVT的结果
NIST-FRVT(人脸识别 厂商测试)是由NIST(美国国家标准与技术研究所)进行的人脸识别模型的性能评估测试,它定义了安全标准。在国际上,通常以NIST-FRVT的结果来评价人脸识别模型。 NIST-FRVT:我们应用的模型是基于根据FRUITS-1000的配置,在WebFace42M上使用RetinaFace-ResNet-50进行人脸检测和人脸对齐,ArcFace-ResNet-200进行人脸嵌入训练。
在提交的430个模型中,用WebFace42M(OURS)训练的模型排名第三。结果显示,在各种任务上都有很高的表现。NIST-FRVT中的前五名车型中。在FNMR中。NIST-FRVT中前五名的型号如下表所示。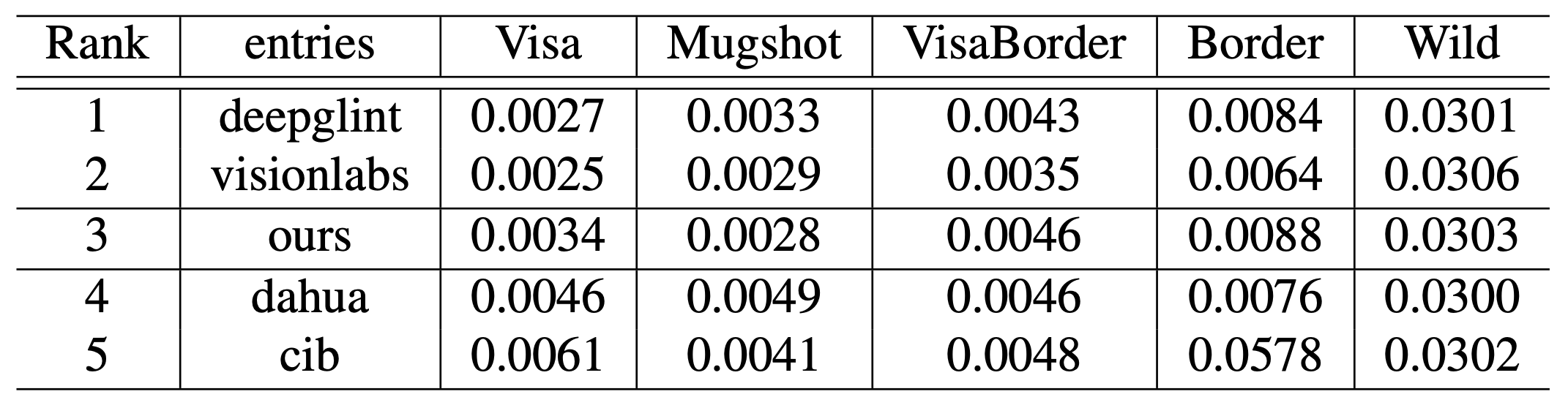
从NIST的结果可以看出,WebFace42M在Public数据上的表现很好,而拥有大数据集的私人公司则是表现最好的,这将是弥补学术界和私人部门在人脸识别研究方面差距的重要契机。



















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











