







引言
在全球众多的语言中,只有极少数的语言在语音识别领域取得了显著的进展。这种不平衡现象的主要原因是,现有的语音识别模型往往依赖于大量的标注语音数据,而这些数据对于许多语言来说难以获得。
近年来,尽管语音识别技术取得了飞速的发展,少量的训练数据已经能够实现较高的准确度,但这一进步背后隐藏着一个关键的局限:每种语言都需要单独开发和训练模型。
因此,本研究旨在探索一种新的路径,即利用多语言标签进行零样本(Zero-shot)转录,以期打破现有模型对大量标注数据的依赖,推动语音识别技术向更多语言的普及和应用。
论文地址:https://arxiv.org/abs/2109.11680
方法
- 利用多语言数据进行自学
- 用多种语言进行微调。还有语音意识。
- 在推理过程中使用从学习语言音素到目标语言的音素映射
- 针对所有未学习语言测试微调模型
音素
它是如此重要,以至于在语音识别研究中经常出现。音素是我们说话时的最小发音单位。只要记住它是最小的发音单位就足够了。
微调
根据自己的用途和任务,使用自己的数据额外训练预训练模型。通过这种方法,您可以将广义模型调整为易于使用的模型。
wav2vec2.0
预训练模型,即在建立模型阶段已在海量数据上训练过的模型。训练数据量确实巨大。你不可能在一所研究生院里复制它。这样做的好处是,由于事先已经在海量数据上进行了训练,因此只需要少量数据就可以进行微调。
实验装置
关于学习模式
本研究使用的模型是wav2vec2.0 XLSR-53。这将是一个多语言学习模型,已在 53 种语言上进行过训练。
关于数据集
使用了三种主要的多语言语音库。这些语言包括荷兰语、法语、德语、意大利语和葡萄牙语。
此外,使用的语言种类繁多,音频播放时间很长。
要学会使用这台超高性能计算机,肯定要花很长时间。
关于学习模型
该模型是用 fairseq 实现的。这是 META(前身为 Facebook)在 githab 上发布的用于构建机器学习模型的开放源代码。
只要懂一点 Python 和英语,任何人都可以免费使用它,并建立机器学习模型。
回到主题,所使用的模型将是经过预训练的 XLSR-53 模型,该模型已进行了约 56 000 小时的预训练。与学习相关的参数目前不在讨论之列。
- 在多语言数据集上进行训练,尝试转录未学习过的语言。
- 使用 wav2vec2.0 XLSR-53
- 需要进行大量细致的参数调整
实验与测试
与无监督方法的比较
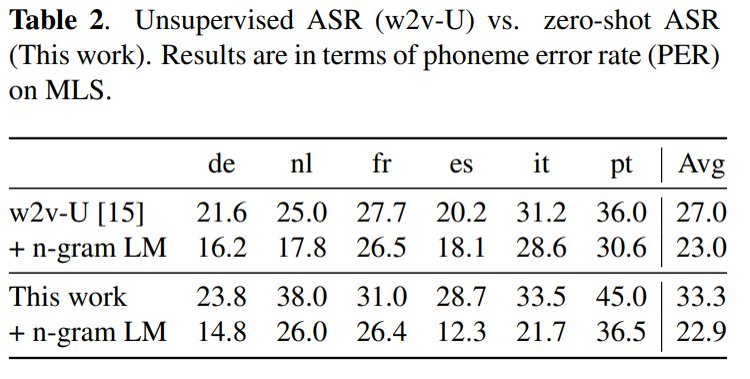
现在,第一个实验将零点过渡学习与无监督 wav2vec2.0 进行比较。两者使用的模型相同。
至于这个实验的结果,你可以看到零点过渡学习和无监督模型几乎同样出色。老实说,这是令人惊讶的。如果这是可能的,那么在各种语言中使用它将是现实的。
如果物联网要在未来变得越来越普遍,这项技术将非常重要。
与其他零镜头的比较
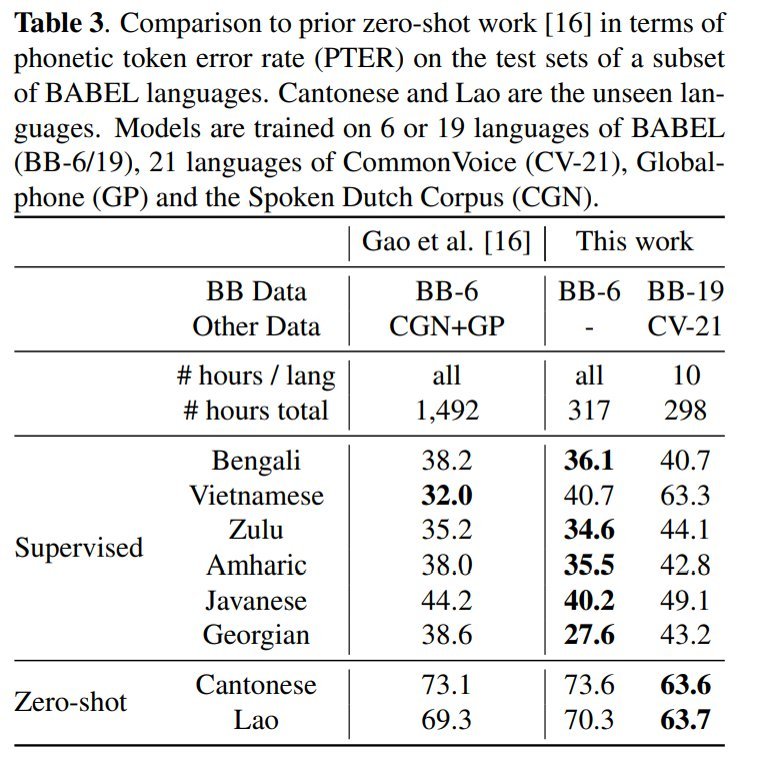
将其性能与本研究之前的模型进行比较。在这里,你又可以轻松实现零投篮(如果你是一家公司的话)。与建立单个模型相比,它的数据密集度要低得多。在某些方面,其结果优于监督模型的结果,这是一种真正的创新方法。
不过,它的瓶颈在于必须在大量的时间数据上进行训练,因此除非大学或公司拥有超级计算机,否则很难复制。
总结
世界上有如此之多的语言,要为每一种语言都建立模型将非常昂贵和耗时。
从这个角度看,这种 "零镜头 "方法大有可为。大家对此有何看法?
这项研究的结果可归纳如下
- 无需专门为未学习语言建立模型
- 准确率高,与有监督和无监督模型相比毫不逊色。
















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











