







概述
去噪扩散概率模型(DDPM)推动了图像生成技术的快速发展,该模型通过对潜在变量进行迭代去噪生成高保真样本,但在扩展到更高分辨率时面临计算挑战。其中,自注意机制是一个瓶颈,而表示压缩则可用于降低计算成本。
高分辨率架构采用斑块和多尺度分辨率,会导致空间信息退化和伪影;DIFFUSSM 取消了自注意机制,并使用状态空间模型(SSM)来降低计算复杂度。DIFFUSSM 采用沙漏架构来处理图像的精细表示并提高效率:在 ImageNet 上进行的实验表明,FID、sFID 和 Inception Score 均有所提高,而 Gflops 却低于现有方法。
论文地址:https://arxiv.org/pdf/2311.18257
算法架构
本文的目标是设计一种扩散架构,它能在高分辨率下学习长程相互作用,而无需像斑块效应那样 “缩减长度”;与基于变换器的扩散模型(DiT)类似,这种方法将图像扁平化,并将序列建模问题作为一个 "序列 "问题来处理。它将其视为序列建模问题。然而,与 Transformers 不同的是,这种方法对序列的长度进行了次二次计算。
状态空间模型(SSM)
状态空间模型(SSM)是一种处理离散时间序列的架构。这些模型基于输入序列 u1、. . . 处理 uL 并输出 y1, . . . yL 并像线性递归神经网络 (RNN) 一样产生 y1, .
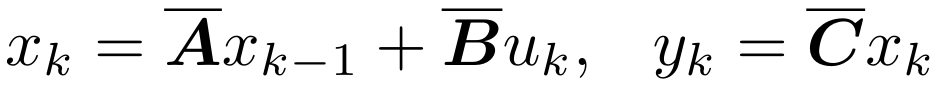
在哪里?
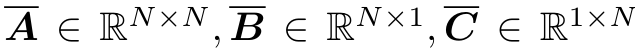
就是这种情况。与变换器或标准 RNNs 等其他架构相比,这种方法的主要优势在于它允许使用线性结构实现长卷积而非递归。具体来说,通过使用 FFT 从 uk 计算 yk,可以获得 O(LlogL) 的计算复杂度,并应用于较长的序列。在处理矢量输入时,可以堆叠 D 个不同的 SSM 并应用 D 个批量 FFT。
线性 RNN 本身并不是一个有效的序列模型,但从一个合适的连续时间状态空间模型中使用离散时间值是一种稳定而有效的方法。我们使用对角化 SSM 神经网络 S4D 作为骨干模型,它可以学习连续时间 SSM 参数化和离散时间参数,并通过近似获得等效结果。
DIFFUSSM 块
DIFFUSSM 的核心部分是一个门控双向 SSM,用于优化处理长序列。为了提高效率,MLP 层采用了沙漏结构。该设计在双向 SSM 周围交替延长和缩短序列长度,特别是在 MLP 内缩短序列长度。完整的模型架构如图 1 所示。
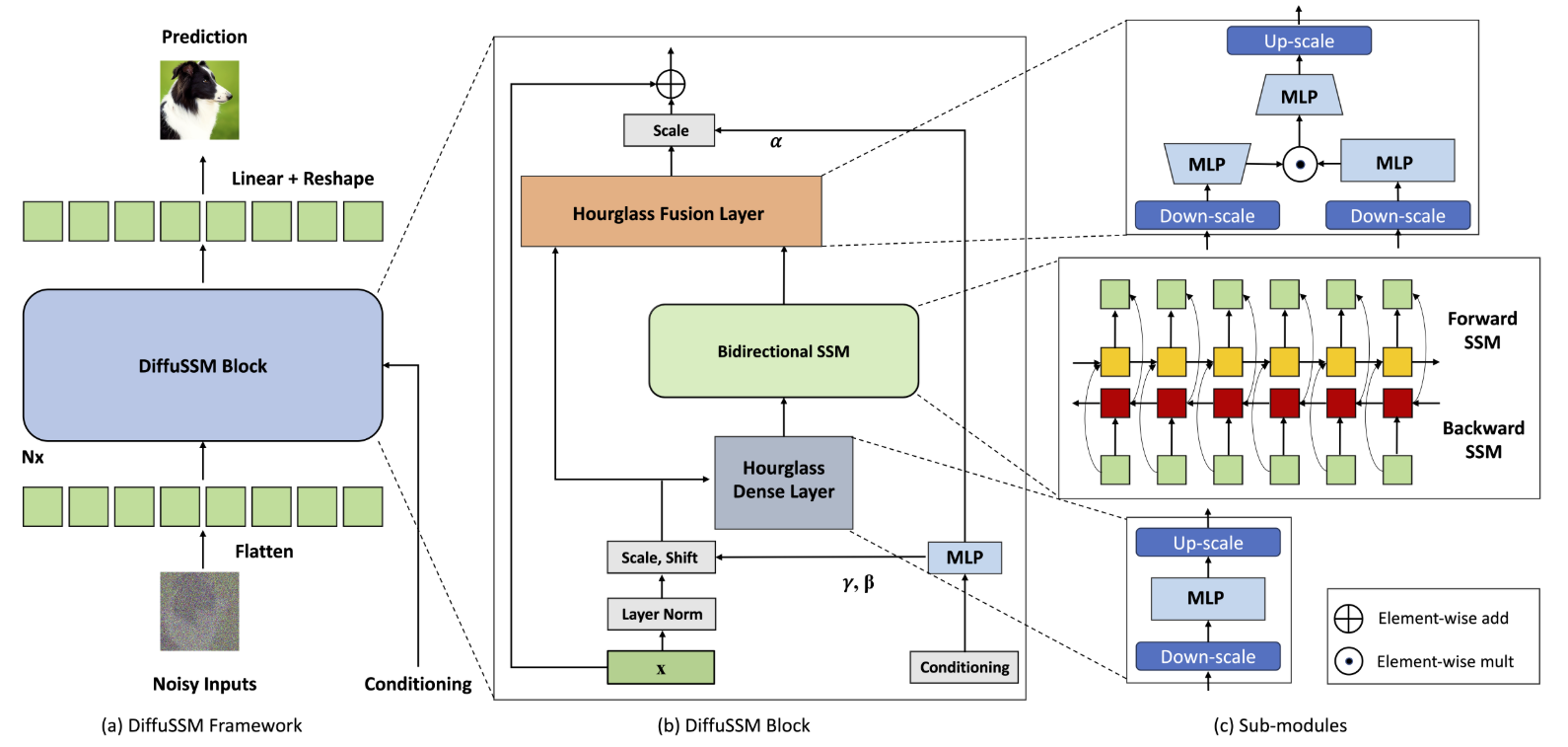
图 1.1 DIFFUSSM 结构。
具体来说,每个沙漏层接收一个缩短、扁平化的输入序列 I∈RJ×D。其中 M = L/J 是降频与升频的比率。与此同时,包含双向 SSM 的整个区块以原始长度计算,充分利用全局上下文。这里,σ 表示激活函数。l∈1…L,j = ⌊l/M⌋,m=lmodM,Dm=2D/M,我们计算如下。
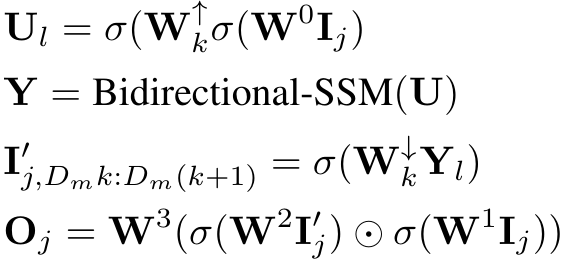
在每一层,这个门控 SSM 块都与跳过连接整合在一起。此外,如图 1 所示,它还在每个位置整合了类别标签 y∈RL×1 和时间步长 t∈RL×1 的组合。
测试与实验
类条件图像生成
在本实验中,通过在ImageNet 256x256 和512x512数据集上进行类条件图像生成任务,测试了所提方法的有效性。实际结果汇总于表 1。可以看出,与之前的研究相比,特别是与传统的扩散模型相比,计算复杂度(Gflops)明显降低。
在ImageNet 256x256 数据集上,我们能够在多个指标上超越 DiT,而在ImageNet 512x512数据集上,我们以较少的学习量取得了具有竞争力的结果。
这意味着降低计算复杂度和保持生成图像质量的目标已经实现。图 2 显示了在每个数据集上生成图像的示例。
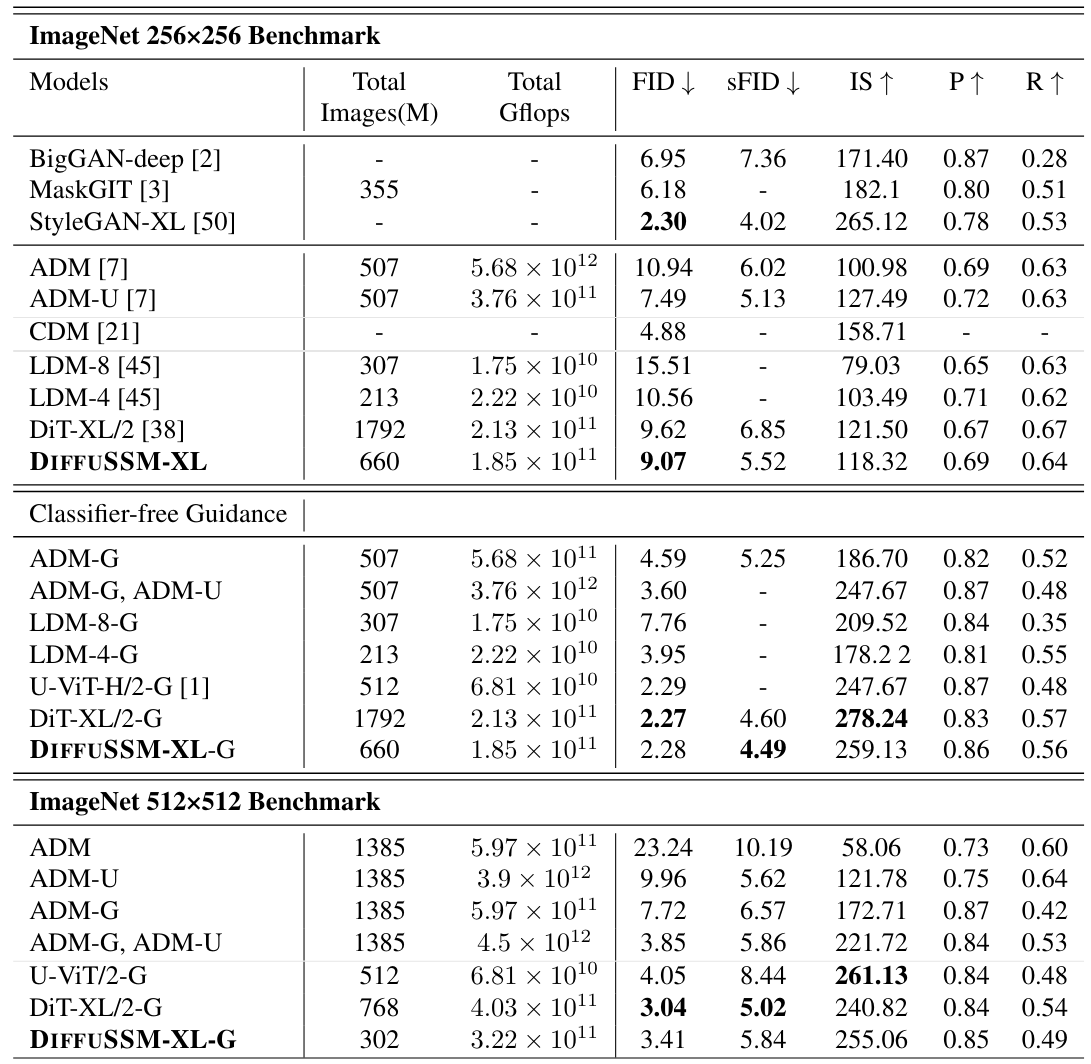
表 1:按类别条件生成图像的实验结果。

图 2:生成的图像示例。
非类别条件生成性能
结果表明,DIFFUSSM 与 LDM 的 FID 分数相当,而训练成本相似(分别为-0.08 和 0.07)。这一结果凸显了 DIFFUSSM 对不同基准和不同任务的适用性:与 LDM 一样,这种方法在 LSUN-Bedrooms 中的表现并没有优于 ADM。不过,这是因为 DIFFUSSM 的总训练成本仅为 ADM 的 25%。
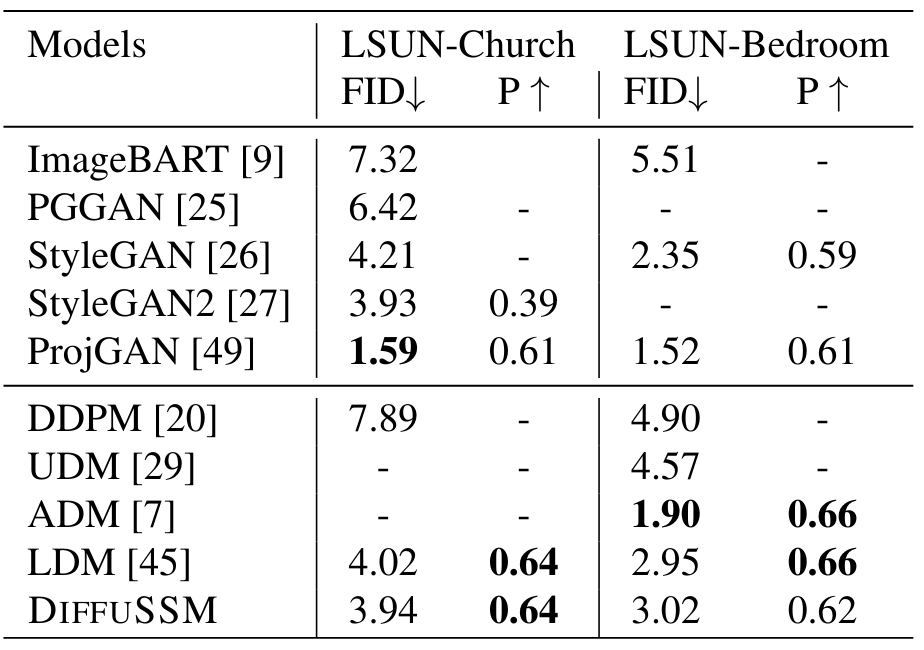
表 2.非类条件图像生成的实验结果
模型的可扩展性和沙漏结构的影响。
使用不同的采样设置对模型进行了训练,以评估压缩潜空间的影响。结果如图 3(右图)所示。将常规模型(M = 2)与应用了补丁大小为 2 的模型(P = 2)进行比较,常规模型的 FID 得分更高,随着训练步骤的增加,差异也在扩大。这表明,信息压缩可能会对高质量图像的生成产生负面影响。
还对三种不同大小的 DIFFUSSM 进行了训练,以评估扩展后的性能。对前 400k 步的 FID-50k 计算证实,较大的模型能更有效地利用 FLOPs,并且在每个训练阶段的扩展都能提高 FID。结果如图 3(左)所示。
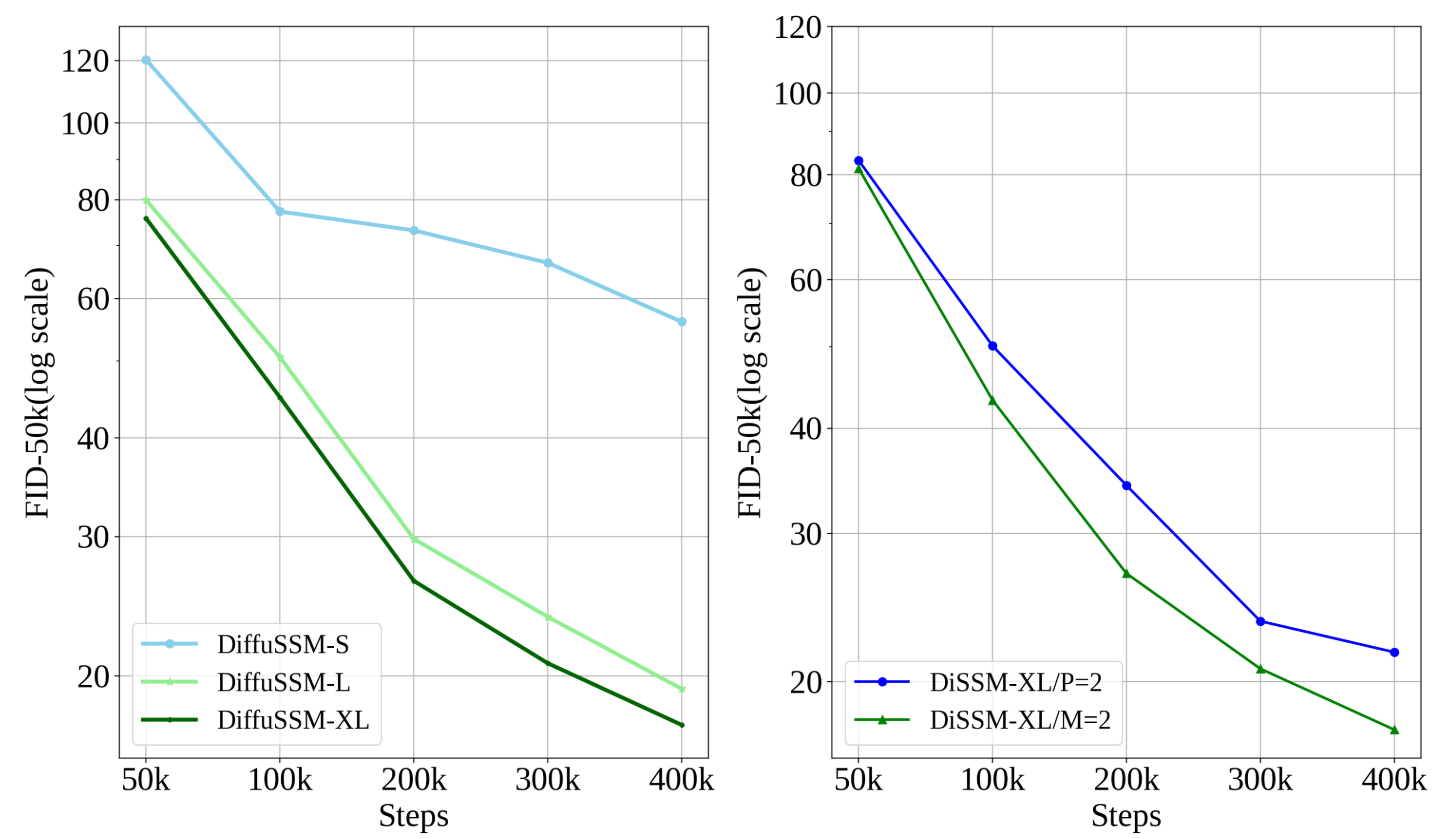
图 3:消融。
左图:不同隐藏维度大小 (D) 的 DIFFUSSM。
右图:不同补丁大小 (P = 2) 和下采样率 (M = 1) 的 DIFFUSSM 的 FID 分数
总结
本文介绍了与注意力无关的扩散模型 DIFFUSSM。这种方法可以处理长程隐藏状态,而无需压缩表示。因此,在 256x256 分辨率下,它能以更少的 Gflops 达到比 DiT 模型更好的性能,并且在更高分辨率下,只需更少的训练就能显示出具有竞争力的结果。
然而,它仍然存在一些局限性。首先,它侧重于无条件图像生成,不支持全文到图像的方法。此外,掩码图像训练等最新方法也可以改进该模型。
然而,DIFFUSSM 为学习大规模扩散模型提供了另一种方法,我们相信,消除注意力瓶颈将为其他需要长距离扩散的领域(如高保真音频、视频和三维建模)带来潜在应用。.
















 2221
2221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











