







介绍
论文地址:https://arxiv.org/pdf/2306.08276
虚拟试穿是以人的图像和服装的图像为基础,目的是想象服装穿在人身上的效果。虚拟试穿可以改善网上购物体验,但大多数传统试穿方法只有在身体姿势和形状变化较小时才能奏效。主要的挑战在于如何根据目标体形对服装进行非刚性变形,同时不扭曲服装的图案或纹理。
本文介绍了 TryOnDiffusion 方法,该方法可处理大型障碍物、姿势变化和体形变化,同时在 1024×1024 美元的分辨率下保留服装的细节。该方法使用两张图像作为输入–一张是目标人物的图像,另一张是另一个人所穿衣服的图像–并生成目标人物穿着衣服的图像作为输出。
为了在 1024×1024 美元的高分辨率下生成高质量图像,TryOnDiffusion 采用了级联扩散模型。具体来说,它首先在 128×128和256×256 分辨率下使用基于 Parallel-UNet (Parallel-UNet) 的扩散。然后将 256×256的结果输入超分辨率扩散模型,生成最终的1024×1024 图像。
与其他最先进的方法相比,TryOnDiffusion 在数量和质量上都有明显优势。特别是,在一项人体实验评估中,与三种最新的先进技术相比,TryOnDiffusion 的概率高达 92.72%,被评为最佳技术。
建议方法

图 1:TryOnDiffusion 概述。
输入预处理
如图 1 左上角所示,除人物和服装图像共有六个组成部分外,整个模型输入由四个组成部分组成。首先,通过训练有素的模型预测人物和服装图像的二维姿势关键点。然后,从服装图像中分割出纯粹的服装图像。对于人物图像,会生成与服装无关的 RGB 图像,在去除原始服装的同时保留人物特征。
试穿级联扩散模型
拟议方法的级联扩散模型由一个基本扩散模型和两个超分辨率(SR)扩散模型组成,如图 1 上半部分所示。基本扩散模型的参数设置为一个 128×128 美元的 Parallel-UNet (图 1 底部)。该模型根据上述输入生成试拟合图像。
128×128至256×256 超分辨率扩散模型的参数设置为 256×256平行−UNet。除上述输入外,该模型还使用了128×128 模型的输出,即试拍图像。
从 256×256到1024×1024 的超分辨率扩散模型的参数为Saharia 等人提出的 Efficient-UNet 模型。这是一个纯粹的超分辨率模型,不以上述六个分量输入为条件。
Parallel-UNet
Parallel-UNet 概览由两部分组成:人-UNet(人)和衣-UNet(衣),如图 1 下部所示。人-UNet 以添加噪点的人像和去除服装的人像作为输入,生成试穿图像。服装-UNet 从仅有服装的分割图像中提取适当的特征,并将其输入到人物-UNet,从而在试穿图像中成功生成目标服装。
在UNet 的每个阶段,通常使用串联法(矩阵串联)将服装-UNet 提取的特征输入到人物-UNet 中。但是,由于逐通道连接可能无法处理服装翘曲等复杂变换,因此本文采用交叉连接,如下式所示。
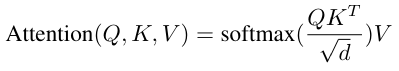
计算方法与通常的 Attention 机制类似,其中 Q 为人物图像的扁平化特征,K 和 V 为服装的扁平化特征。为确保试穿图像中正确反映人物姿态和服装图案,在预处理中创建的人物和服装图像的二维姿态关键点被线性嵌入,并通过类似的交叉注意输入到人物-UNet 和服装-UNet 中。
试验
数据集
我们收集了 400 万个样本作为训练配对数据集。每个样本都由同一人的两张不同姿势和穿着相同服装的图像组成。在测试中,收集了 6000 个在训练中从未见过的样本。每个测试样本包含两个不同人物的两张不同图片,人物的姿势和穿着各不相同。根据检测到的二维人体姿势,训练和测试图像都被裁剪并调整为 1024 x 1024 大小。该数据集包括不同姿势、体形、肤色的男性和女性,以及穿着不同纹理图案服装的男性和女性。还使用了 VITON-HD 数据集
与以往研究的比较
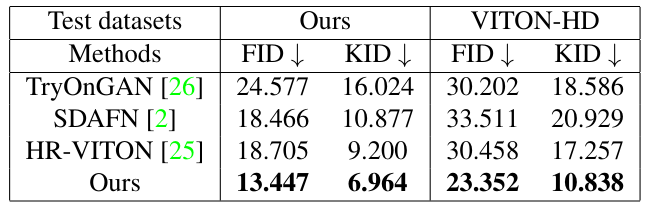
表 1.与以往研究的定量比较
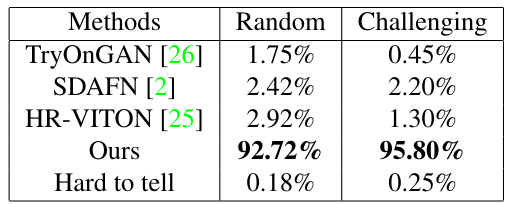
表 2.人类评分比较

图 2:与以往研究的定性比较
在本实验中,所提出的方法与 TryOnGAN、SDAFN 和 HR-VITON 进行了比较,它们都是虚拟试衣图像生成的典型模型。表 1 显示了图像质量和自然度方面的 FID 和 KID 比较结果。可以看出,在这两个数据集上,所提出的方法在所有评价指标上都优于之前的研究。
图 2 中的定性评估显示了类似的结果,表明与之前的研究相比,所提议的方法显然能够生成更自然、更清晰的图像。特别是,我们观察到人物的姿势和衣服上的图案都得到了很好的再现。
除定性和定量评估外,还进行了两项用户研究。结果见表 2。在第一项研究 "随机 "中,从 6 000 个测试集中选取了 2804 个输入对,由评估人员选出最佳结果。在第二项研究 "挑战性 "中,使用类似的程序选择并评估了 2 000 个难度更大的输入对。结果显示,95.8% 的人选择了拟议方法。
交叉关注和串联的比较
如前所述,在 UNet 的每个阶段将服装 UNet 提取的特征输入人物 UNet 时,使用了交叉注意法而不是传统的并集法。本节将评估交叉注意的有效性。图 3 显示了比较结果,结果表明交叉注意在保留服装细节方面更胜一筹,即使在身体姿势和形状发生较大变化时也是如此。
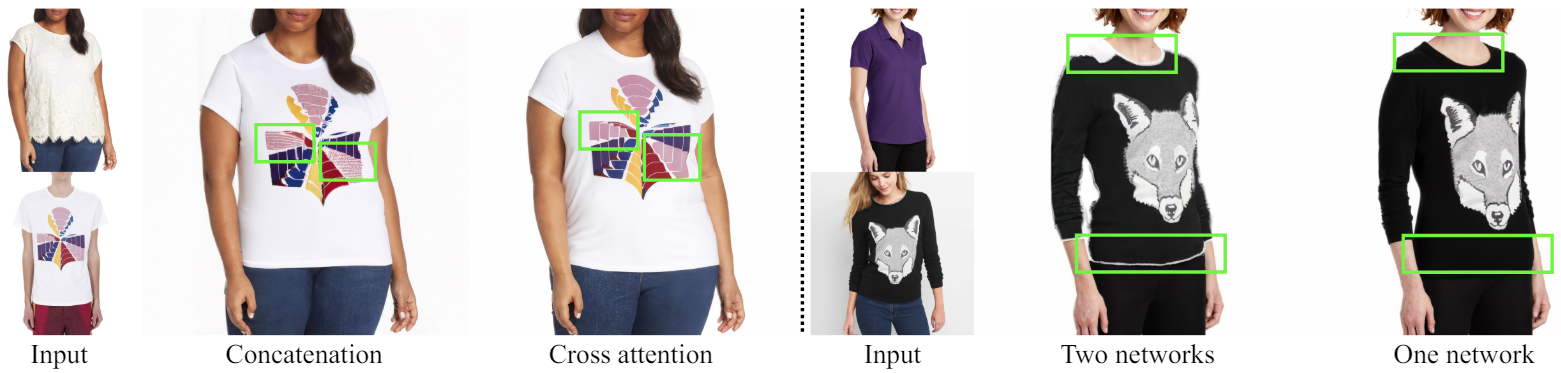
图 3.Cross-Attention 和 Concatenation 的比较。
总结
本文介绍了 TryOnDiffusion,它能根据人物图像和服装图像合成试穿图像。该方法利用 Parallel-UNet,能够处理各种姿势和体形,而不会扭曲服装的图案和纹理,从而达到最先进的性能。不过,目前尚未研究其与复杂背景图像和全身图像的兼容性。未来的研究有望克服这一问题,并取得进一步发展,特别是扩展到视频领域。



















 5305
5305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











