






1、Tyron Diffusion: A Tale of Two UNets (CVPR2023)
论文:https://arxiv.org/abs/2306.08276
代码:TryOnDiffusion: A Tale of Two UNets
1、背景
TryOnDiffusion ,由Google Research与华盛顿大学联合研发 。可以通过将两张图片融合起来,让模特无须重新拍摄就可以展示出不同服装的上身效果。传统的合成方法通常只能接受造型区别不大的两张图片,否则合成出来的新图片会出现服装变形严重的情况。而 TryOnDiffusion 基于并行 UNet 的扩散式架构打造,能够在保留更多细节的情况下让服装和真人模特相结合,呈现出自然的服装效果。

给定两张描绘一个人和另一个人穿的衣服的图像,Tyron Diffusion的目标是生成一个可视化的图像,显示衣服在输入人身上的样子。关键的挑战是合成一个逼真的保留服装细节的可视化图像,同时扭曲服装以适应人物主要的身体姿势变化。以前的方法要么注重服装细节的保存,而没有有效的姿势和形状的变化,要么允许以所需的形状和姿势试穿,但缺乏服装细节。并且大部分方法将试穿任务分为两个阶段:服装扭曲和混合模型。
服装细节问题:TryOnGAN通过在未配对的时尚图像上训练一个有姿态约束的StyleGAN2,并在隐式空间中进行优化,但此时容易丢失隐式空间中表征较少的服装细节。当服装有图案或细节,如口袋,或特殊的袖子时,这一点就很明显了。
本文提出了一种基于扩散的架构,该架构统一了两个unet (称为Parallel-UNet),这使我们能够在单个网络中保留服装细节并对服装进行扭曲,以实现显著的姿势和身体上的变化。Parallel-UNet的核心思想包括:
- 服装是通过交叉注意机制隐式扭曲的;
- 服装扭曲和人的融合是一个统一过程的一部分,而不是两个独立任务。
2、方法概述
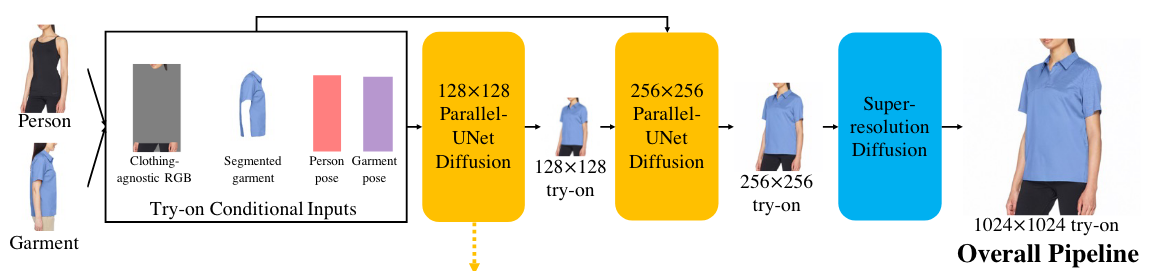
给定一个人的图像Ip和另一个人穿着服装的图像Ig,该方法生成人穿着服装的试穿结果Itr。模型在成对数据上进行训练,其中Ip和Ig是同一个人穿着同一件衣服但在两种不同姿势下的图像。在推理过程中,Ip和Ig为两个不同的人在不同姿势下穿着不同服装的图像。
(1)数据预处理
- 预测Ip和Ig的人体解析图Sp和Sg,2D姿态关键点Jp和Jg;
- 利用Ig人体解析图Sg分割出服装Ic;
- 对于Ip,生成了衣物不可知的RGB图像Ia,去除了原始的衣物但保留了人物身份;
- 输入数据:Ctryon = (Ia, Jp, Ic, Jg),标准化到0-1中
(2)Cascaded Diffusion Models for Try-On
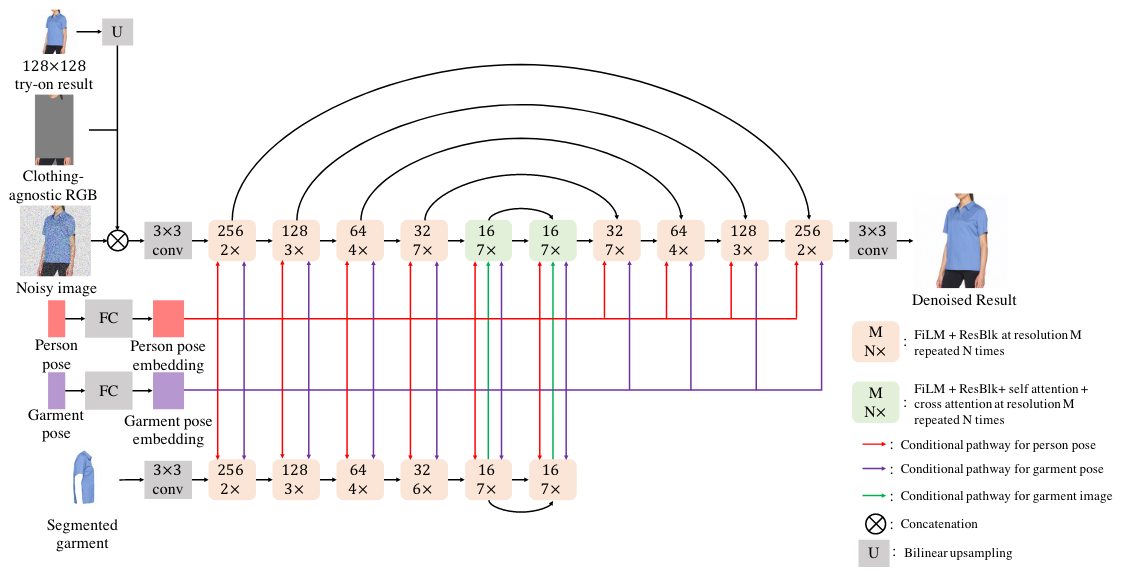
输入Ctryon被送入128×128的Parallel-UNet(关键贡献),以创建128x128的试穿图像,该图像与Ctryon输入一起进一步作为输入发送到256×256 Parallel-UNet。256×256 Parallel-UNet的输出被发送到标准超分辨率扩散(无Ctryon)以创建1024×1024图像Itr。
ResBlk: GroupNorm→swish→conv→GroupNorm→swish→conv
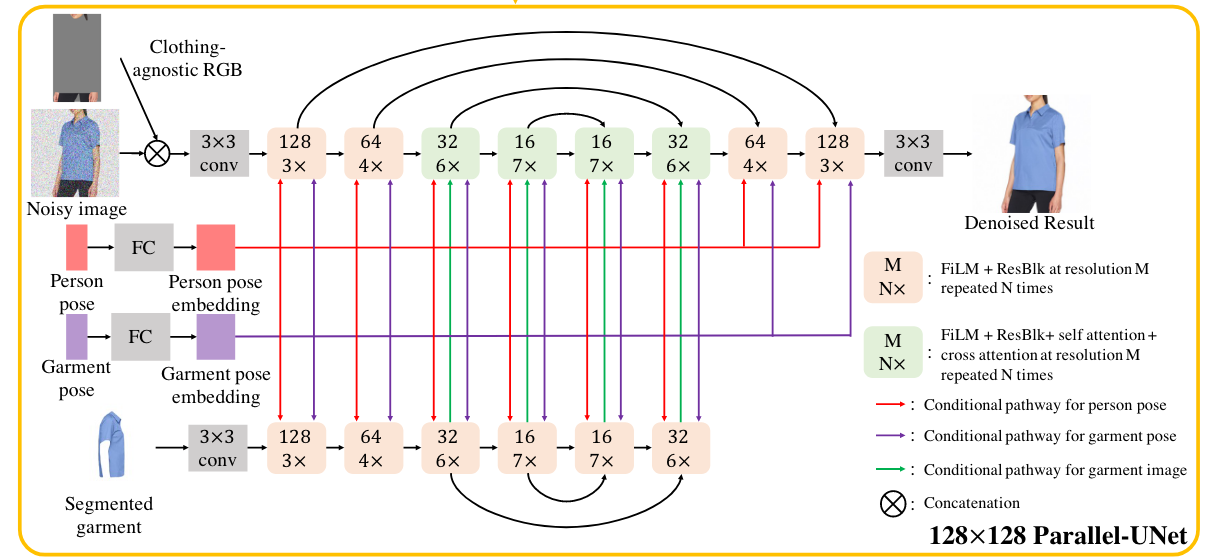
(3)Parallel-Unet
网络处理过程表示为:
![]()
t是diffusion时间步长,zt是t时刻的噪声图像,Ctryon是条件输入,tna是不同条件图像的噪声增强级别;et是预测到的噪声,用于从zt中恢复gt图像。
如何实现隐式扭曲?
之前的解决方案:使用传统的Unet网络,并将分割的服装Ic和噪声图像zt沿通道维度拼接起来,然而通道级联无法实现复杂的扭曲,如服装变形,这是因为传统Unet的计算单元是空间卷积和空间注意力,而这些单元具有很强的逐像素结构偏差。
tryondiffusion的做法:使用信息流(Ic和zt)之间的交叉注意力机制来实现隐式的扭曲。交叉自注意力基于普通的自注意力,但查询和键值来自不同的输入:其中Q来自zt,K,V来自Ic,通过计算Attention Map来获得服装与目标模特之间的相似性。同时将交叉注意力设置为多个头,允许模型学习到多个特征子空间的表示。
如何在一次前向传播过程中实现扭曲和融合?
之前的做法:将服装扭曲到目标人体,再与目标人体混合;
tryondiffusion的做法:使用两个Unet网络分别处理服装和人体。person-Unet将“去除服装的RGB图像”Ia和噪声图像zt作为输入,由于Ia和zt是按照像素对齐的,因此在UNet处理开始时直接沿通道维度将它们拼接起来。garment-Unet将分割后的服装Ic作为输入,服装特征通过上述交叉注意力融合到目标图像。
人体姿势Jp和服装姿势Jg首先被输入到线性层来计算pose embedding,之后通过注意力机制融合到person-Unet(连接到每个自注意力层的键值对)。此外,CLIP-style 1D attention pooling沿着关键点维度减少pose embedding,并与扩散时间步t和噪声增强级别tna的位置编码相加,产生的一维向量用于在所有尺度上使用FiLM调制Person-Unet和Garment-Unet的特征。
3、实验细节
训练集:4百万样本的成对数据集,每个样本由同一个人在两种不同姿势下穿着同一件服装的两张图像组成。(1024×1024)
测试集:6K个未出现在训练集中的未配对样本,每个测试样本包括不同人在不同姿态下穿着不同服装的两幅图像。(1024×1024)
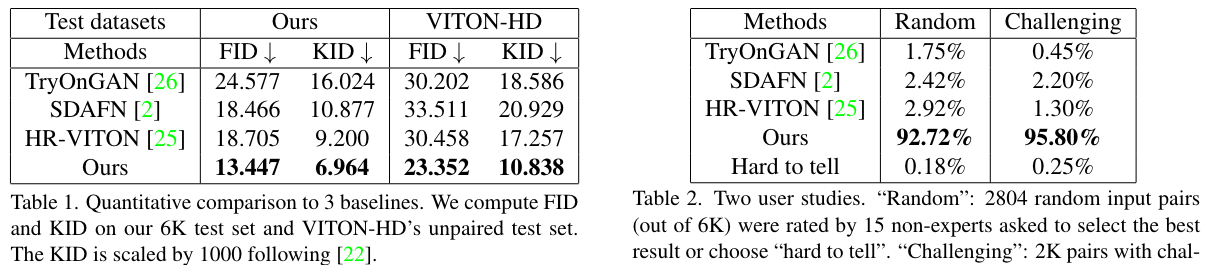
评价指标:FID、KID,在两个测试数据集(6K测试数据集和VITON-HD数据集)上计算。User Study:15名专家在不同方法的2408个输入图像中选择最佳结果。

Kernel Inception Distance (KID):与FID类似,KID通过计算Inception表征之间最大均值差异的平方来度量两组样本之间的差异。此外,与所说的依赖经验偏差的FID不同,KID有一个三次核的无偏估计值,它更一致地匹配人类的感知。
使用DDPM对基础扩散模型进行256时间步的采样;使用DDPM对128×128→256×256 SR扩散模型进行128步采样;最终的256×256→1024×1024 SR扩散模型使用DDIM进行32个时间步的采样。
定量结果:
定性结果:



















 1638
1638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









