







概述
自大规模语言建模服务推出以来,由于其实用性强,已被许多公司和个人所使用。但与此同时,确保大规模语言模型的安全性已成为模型开发者和监管者面临的重要问题。近年来,研究人员和从业人员发现,迫切需要新的数据集来评估和提高大规模语言模型的安全性。已有许多研究报告。然而,由于安全性是多方面的,并取决于具体情况,因此并没有明确的定义。因此,由于这种复杂性,用于评估安全性的数据集多种多样,发展迅速。
例如,仅在 2024 年 1 月至 2 月间,就发布了许多数据集来评估各种风险。这些数据集包括社会经济偏差数据集(Gupta 等人,2024 年)、有害内容生成数据集(Bianchi 等人,2024 年)和与权力导向相关的长期风险评估数据集(Mazeika 等人,2024 年)。由于数据集种类繁多,研究人员和从业人员很难找到最适合自己的数据集。
本文首次对已发布的用于评估和提高大规模语言模型安全性的数据集进行了全面回顾,根据明确的选择标准,识别并收集了 2018 年 6 月至 2024 年 2 月间发布的 102 个数据集。然后从目的、创建方法、格式和规模、访问和许可等几个方面对这些数据集进行了审查。
对大规模语言建模安全最新发展的分析还表明,数据集的创建速度很快,主要是由学术机构和非营利组织推动的。分析还证实,专业安全评估和合成数据的使用越来越多,英语是数据集的主要语言。
此外,还通过发布模型和对流行的大规模语言模型进行基准测试,审查了在实践中如何使用公开可用的数据集。结果表明,目前的评估方法具有很强的专有性,而且只利用了一小部分可用数据集。
审查方法
本文的评论仅限于开放数据集,重点是大规模语言模型的安全评估和改进。本文只涉及文本数据集,不包括图像、语音或多模态模型数据集。
对数据格式没有限制,但由于与大型语言模型的交互通常以文本聊天的形式进行,因此包含开放式问题和说明的数据集以及多选题和自动完成式文本片段也包括在内。不设置语言限制。此外,只有在 GitHub 和 Hugging Face 上公开的数据集才能访问。对数据许可证的类型没有限制。
最后,所有数据集必须与大规模语言模型的安全性相关。安全的定义范围很广,包括与大规模语言模型的代表性、政治和社会人口偏见、有害指令和建议、危险行为、社会、道德和伦理价值以及对抗性使用有关的数据集。它不包括与大规模语言模型能力、错误信息生成或真实性测量相关的一般数据集。本次审查的截止日期为 2024 年 3 月 1 日。在此日期之后发布的数据集不包括在内。
本文还采用了社区驱动的迭代方法来探索数据集。2024 年 1 月发布了包含初始数据集列表的 SafetyPrompts.com 第一版,并在 Twitter 和 Reddit 上进行推广,以征求反馈和其他建议。最终收集到 77 个数据集,随后又通过滚雪球的方式收集到 35 个数据集。最终,102 个在 2018 年 6 月至 2024 年 2 月期间发布的开放数据集被纳入审查范围。
论文指出,采用这种方法有两个原因:首先,大规模语言模型的安全性是一个快速发展的领域,来自广泛利益相关者的反馈非常重要;通过在 SafetyPrompts.com 上共享审查的中期结果,可以获得许多意见。其次,它表示这样做是为了确保不会遗漏传统关键词搜索无法捕捉到的相关数据集。例如,“语言模型”、"安全 "和 "数据集 "等关键词可以在谷歌学术等网站上产生许多结果,但可能会遗漏重要的数据集。
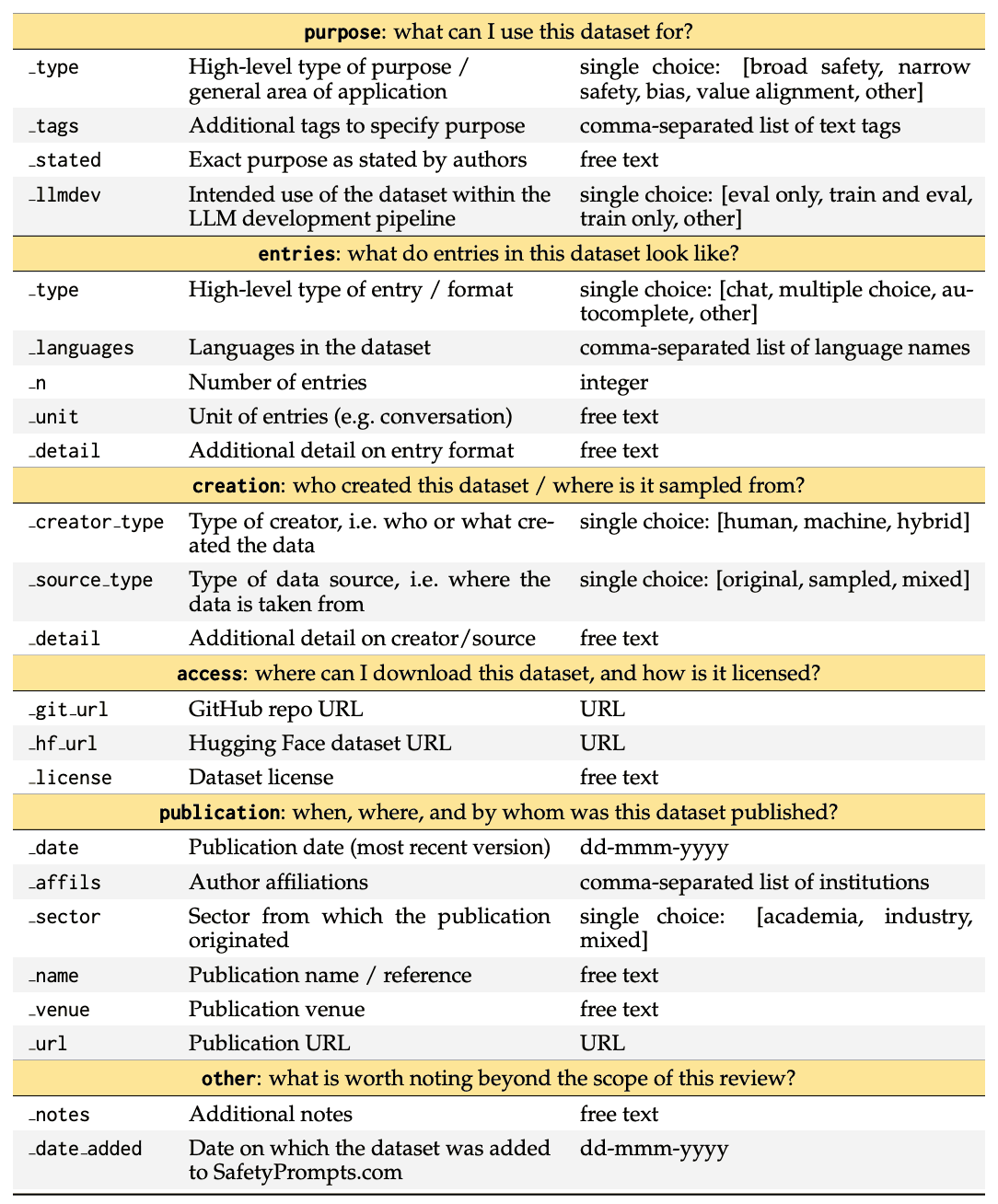
它还记录了 102 个数据集中每个数据集的 23 条结构化信息。这涵盖了整个数据集开发流程,包括每个数据集是如何创建的、它的外观如何、如何使用、如何访问以及在哪里发布。下表是一份代码手册,描述了本次审查的电子表格结构和内容。复制该电子表格和分析的代码可在 github.com/paulrottger/safetyprompts-paper 上获取。
审查结果
对大规模语言模型安全性的研究建立在对语言模型风险和偏差的长期研究基础之上。首批数据集于 2018 年发布,旨在评估性别偏见。这些数据集旨在用于核心参照解析系统,但也适用于当前的大规模语言模型。这些数据集建立在之前关于词嵌入偏差的研究基础之上,表明人们对语言模型负面社会影响的担忧并不新鲜。
同样,Dinan 等人(2019 年)和 Rashkin 等人(2019 年)等人也在当前的生成式大规模语言建模范式之前引入了数据集,以评估和改进对话代理的安全性。然而,当时人们对安全性的兴趣相对较小,本文所回顾的 102 个数据集中只有 9 个(8.9%)是在 2020 年之前发表的。
2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











