






Summary
[GPT3.5]
Entropy encoding and run-length coding are both techniques used in data compression to reduce the amount of data needed to represent a given message or signal.
Entropy encoding is a lossless data compression technique that works by encoding symbols in a message with fewer bits for those that occur more frequently and more bits for those that occur less frequently. This is based on the principle that more frequently occurring symbols can be represented with fewer bits, resulting in a more efficient representation of the message. The most common form of entropy encoding is Huffman coding, which is used in many compression algorithms, including JPEG and MP3.
Run-length coding, on the other hand, is a simple lossless data compression technique that works by replacing sequences of repeated symbols with a count of the number of times the symbol is repeated. For example, if a message contains the sequence "AAAABBBBCCCC", it can be compressed using run-length coding as "4A4B4C". This technique is particularly effective for compressing data that contains long sequences of repeated symbols, such as some types of images.
Both entropy encoding and run-length coding can be used together in a compression algorithm to achieve even greater compression ratios.
Data Compression
Data Compression Lecture Slide from Princetonhttps://www.cs.princeton.edu/courses/archive/fall04/cos226/lectures/compress.4up.pdfhttps://www.cs.princeton.edu/courses/archive/fall04/cos226/lectures/compress.4up.pdfhttps://www.cs.princeton.edu/courses/archive/fall04/cos226/lectures/compress.4up.pdf
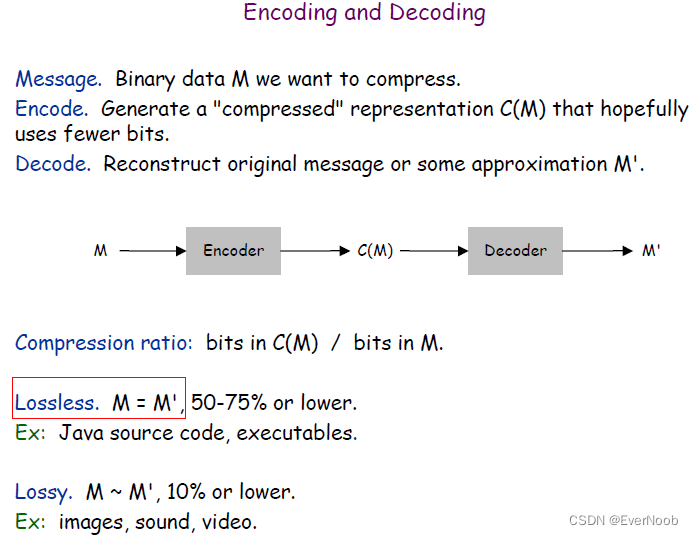
Compression reduces the size of a file:
To save TIME when transmitting it.
To save SPACE when storing it.
Most files have lots of redundancy.
"not all bits have equal value"
simple idea:

a binary encoding can then be compressed by Run-Length Encoding as:


the earliest "processors" (1886) use:

the basic principle is to assign shortest encoding to the most frequently used symbol


How to represent (the Prefix-Free Code)? Use a binary trie.
– symbols are stored in leaves
– encoding is path to leaf
Encoding.
Method 1: start at leaf corresponding to symbol, follow path up to the root, and print bits in reverse order.
Method 2: create ST of symbol-encoding pairs.
Decoding.
Start at root of tree.
Take left branch if bit is 0; right branch if 1.
If leaf node, print symbol and return to root.
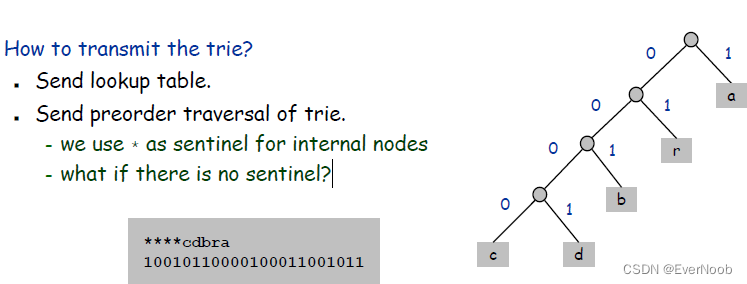
"sentinel" value: In computer programming, a sentinel value (also referred to as a flag value, trip value, rogue value, signal value, or dummy data) is a special value in the context of an algorithm which uses its presence as a condition of termination, typically in a loop or recursive algorithm.
==> if there are no sentinels, retriving encoding scheme is confusing(, write a trie parser for any traversal and see how you fare without sentinels).
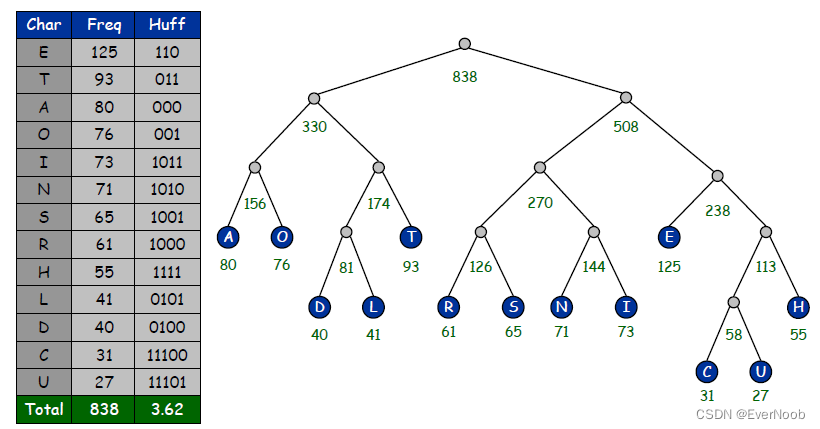
Huffman Coding
https://en.wikipedia.org/wiki/Huffman_coding

==> the most frequent symbol, with the largest weight will be nearest to the root, which means it will have the shortest encoding

(wiki)
Huffman's original algorithm is optimal for a symbol-by-symbol coding with a known input probability distribution, i.e., separately encoding unrelated symbols in such a data stream. However, it is not optimal when the symbol-by-symbol restriction is dropped, or when the probability mass functions are unknown. Also, if symbols are not independent and identically distributed, a single code may be insufficient for optimality. Other methods such as arithmetic coding often have better compression capability.

Difficulty of Data Compression

for a (small) pseudo-randomly generated file, the compression process can very well add to the overall size (by transmitting trie)
Entropy and Compression



https://en.wikipedia.org/wiki/Arithmetic_coding
Probability Distribution Modelling

LZW Algorithm

ST: Suffix Trie
https://en.wikipedia.org/wiki/Suffix_tree

some details are missing, more on LZW: LZW (Lempel–Ziv–Welch) Compression technique - GeeksforGeeks
How does it work?
LZW compression works by reading a sequence of symbols, grouping the symbols into strings, and converting the strings into codes. Because the codes take up less space than the strings they replace, we get compression. Characteristic features of LZW includes,
- LZW compression uses a code table, with 4096 as a common choice for the number of table entries. Codes 0-255 in the code table are always assigned to represent single bytes from the input file.
- When encoding begins the code table contains only the first 256 entries, with the remainder of the table being blanks. Compression is achieved by using codes 256 through 4095 to represent sequences of bytes.
- As the encoding continues, LZW identifies repeated sequences in the data and adds them to the code table.
- Decoding is achieved by taking each code from the compressed file and translating it through the code table to find what character or characters it represents.
Summary
















 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









