






We very often see a menagerie of performance benchmarks for LLM papers listed to showcase the "breakthroughs" and very likely know very little about the specifics about each particular test suite.
There, then, lies a danger of being misled and manipulated by the authors to see only the tailored tests, and we should make sure to know what is actually being presented by the swarms of LLM papers, to better judge their quality and make sure the inspirations we derived from them are not distorted by the lens of presentation.
Sources
[1] a short listing of popular LLM tests:
[2] more listing:
Decoding 21 LLM Benchmarks: What You Need to Know
[3] a guide for benchmarking your AI project:
https://towardsdatascience.com/llm-evals-setup-and-the-metrics-that-matter-2cc27e8e35f3
LLM Benchmarks
Coding
HumanEval: LLM Benchmark for Code Generation [1]
HumanEval is the quintessential evaluation tool for measuring the performance of LLMs in code generation tasks.
HumanEval consist of HumanEval Dataset and pas@k metric which use to evaluate LLM performance. This hand-crafted dataset, consisting of 164 programming challenges with unit tests, and the novel evaluation metric, designed to assess the functional correctness of the generated code, have revolutionized how we measure the performance of LLMs in code generation tasks
HumanEval Dataset
HumanEval Dataset consist of set of 164 handwritten programming problems assessing language comprehension, algorithms, and simple mathematics, with some comparable to simple software interview questions. Each problem includes a function signature, docstring, body, and several unit tests, with an average of 7.7 tests per problem
Pass@k Metric
The pass@k metric, designed to evaluate the functional correctness of generated code samples. The pass@k metric is defined as the probability that at least one of the top k-generated code samples for a problem passes the unit tests. This method is inspired by how human developers test code correctness based on whether it passes certain unit tests.
You can look at HumanEval leaderboard here, where multiple Language Models finetuned on Code benchmarked and currently GPT-4 maintained at the top position in the leaderboard.
HumanEval Benchmark (Code Generation) | Papers With Code
MBPP (Mostly Basic Python Programming) [1]
MBPP benchmark is designed to measure the ability of LLM to synthesize short Python programs from natural language descriptions. The Mostly Basic Programming Problems (MBPP) dataset contains 974 programming tasks, designed to be solvable by entry-level programmers covering programming fundamentals, standard library functionality, and so on. Each problem consists of a task description, code solution and 3 automated test cases to check for functional correctness. You can find the MBPP Dataset at huggingface
==> MBPP state the coding problem in natural language, while HumanEval prompt by a function to be completed, with comment stating the problem, sometimes with mathematical expression; hence the latter can claim to test more than simple coding ability
==> in terms of coding problem difficult, these 2 seems similar, about the "easy" level on leetcode.
CodeXGLUE (General Language Understanding Evaluation benchmark for CODE) [2]
CodeXGLUE tests how well LLMs can understand and work with code. It measures code intelligence across different types of tasks, including:
-
Code-to-Code: Fixing code errors, finding duplicate code, etc.
-
Text-to-Code: Searching for code using natural language
-
Code-to-Text: Explaining what code does
-
Text-to-Text: Translating technical documentation
Here’s the full list of included tasks, datasets, programming languages, etc.:

Source: GitHub
NLP
Chatbot Arena (Chat) [1]
Benchmarking LLM assistants is extremely challenging because the problems can be open-ended, and it is very difficult to write a program to automatically evaluate the response quality.
Chatbot Arena, a benchmark platform for large language models (LLMs) that features anonymous, randomised battles between two LLMs in a crowdsourced manner. And finally LLMs ranked using Elo rating system which is widely used rating in chess.
Arena contains popular open-source LLMs and in the arena, a user can chat with two anonymous models side-by-side and then vote for output response which one is better among those two LLMs. This crowdsourcing way of data collection represents some use cases of LLMs in the wild. You can try out Chatbot Arena at https://arena.lmsys.org and rank LLMs by voting the best output response.
Chatbot Arena Elo, based on 42K anonymous votes from Chatbot Arena using the Elo rating system.
MT Bench (Mixed QA) [1]
MT-bench is a challenging multi-turn question set designed to evaluate the conversational and instruction-following ability of models.
MT-Bench is a carefully curated benchmark that includes 80 high-quality, multi-turn questions. These questions are tailored to assess the conversation flow and instruction-following capabilities of models in multi-turn dialogues. They include both common use cases and challenging instructions meant to distinguish between chatbots.
MT Bench Dataset
MT Bench identified 8 primary categories of user prompts: Writing, Roleplay, Extraction, Reasoning, Math, Coding, Knowledge I (STEM), and Knowledge II (humanities/social science) which consist of crafted 10 multi-turn questions per category, yielding a set of 160 questions in total.
Evaluate ChatBot’s Answers
Its always difficult to evaluate language answers, and human as an evaluator always preference to be the gold standard but it is notoriously slow and expensive to evaluate performance of every LLM therefore they used GPT-4 as a judge to grade ChatBot’s Answers. This approach explain in the paper “Judging LLM-as-a-judge” and in the blog where they evaluate Vicuna using GPT-4 as a judge.
ARC Benchmark (Reasoning MC) [1]
AI2 Reasoning Challenge (ARC) to be a more demanding “knowledge and reasoning” test which requires far more powerful knowledge and reasoning than previous challenges such as SQuAD or SNLI. The ARC question set is partitioned into a Challenge Set and an Easy Set, where the Challenge Set contains only questions answered incorrectly by both a retrieval-based algorithm and a word co-occurence algorithm.
==> of course we cannot be sure there is any underlying human-like reasoning capacity for current ML-based AI, in fact I'd argue we can be fairly certain there isn't any, due to the obviously lack of full prepositional logical reasoning ability; we are simply testing for reasoning-like competence which is crucial for using LLM in simple tasks and human interactions.
The ARC Dataset
The ARC dataset contains 7787 non-diagram, 4-way multiple-choice science questions designed for 3rd through 9th grade-level standardized tests.
==> the multiple choice is the key difference from MT Bench, since MT bench requires conversational response.
These questions derived from numerous sources and targeting various knowledge types (e.g., spatial, experimental, algebraic, process, factual, structural, definition, and purpose) — are split into an Easy Set and a Challenge Set.
Difficultly nature of task can be interpreted by when top neural models from the SQuAD and SNLI tasks tested against ARC Benchmark then none are able to significantly outperform a random baseline.
Leaderboard
ARC maintains their own leaderboard here and this benchmark is also part of Huggingface open LLM leaderboard.
MultiNLI (Multi-Genre Natural Language Inference) (Reasoning MC) [2]
This benchmark contains 433K sentence pairs—premise and hypothesis—across many distinct “genres” of written and spoken English data. It tests an LLM’s ability to assign the correct label to the hypothesis statement based on what it can infer from the premise.
Sample questions (correct answer bolded)

WinoGrande (Reasoning MC) [2]
https://arxiv.org/pdf/1907.10641.pdf
WinoGrande’s a massive set of 44,000 problems based on the Winograd Schema Challenge. They take the form of nearly-identical sentence pairs with two possible answers. The right answer changes based on a trigger word. This tests the ability of LLMs to properly grasp context based on natural language processing.

HellaSwag (Reasoning QA) [1]
HellaSwag benchmark is use to test the commonsense Reasoning understanding about physical situations by testing if language model could complete the sentence by choosing the correct option with common reasoning among 4 options. It consists of questions that are trivial for humans (with an accuracy of around 95%), but state-of-the-art models struggle to answer (with an accuracy of around 48%). The dataset was constructed through Adversarial Filtering (AF), a data collection paradigm that produces a dataset and helps to increase complexity of the dataset.
Adversarial Filtering (AF)
Adversarial Filtering (AF) is a data collection paradigm used to create the HellaSwag dataset. The key idea behind AF is to produce a dataset that is adversarial for any arbitrary split of the training and test sets. This requires a generator of negative candidates, which are wrong answers that violate commonsense reasoning. A series of discriminators then iteratively select an adversarial set of machine-generated wrong answers. The insight behind AF is to scale up the length and helps to increase complexity of the dataset.
HellaSwag’s questions are segments of video captions (describing some event in the physical world). A video caption segment provides an initial context for an LLM. Each context is then followed by four options for completing that context, with only one option being correct with commonsense Reasoning.
Leaderboard
HellaSwag benchmark is part of Huggingface open LLM leaderboard.
BIG-Bench (Beyond the Imitation Game) (Reasoning QA) [2]
This one’s a holistic and collaborative benchmark with a set of 204 tasks ranging from language to math to biology to societal issues. It is designed to probe LLMs ability for multi-step reasoning.2
Sample task:

GSM8K (Reasoning QA) [2]
https://arxiv.org/pdf/2110.14168v1.pdf
GSM8K (Grade Schooler Math?) is a set of 8.5K grade-school math problems. Each takes two to eight steps to solve using basic math operations. The questions are easy enough for a smart middle schooler to solve and are useful for testing LLMs’ ability to work through multistep math problems.
Sample question:
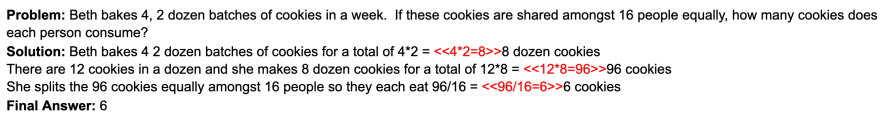
Massive Multitask Language Understanding (Mixed MC) [1]
MMLU benchmark measures the model’s multitask accuracy. The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more at varying depths, from elementary to advanced professional level. To attain high accuracy on this test, models must possess extensive world knowledge and problem solving ability.
==> it's multiple choice
MMLU Dataset
The MMLU dataset is a proposed test for measuring massive multitask language understanding. It consists of 15,908 questions across 57 tasks covering various branches of knowledge, including the humanities, social sciences, hard sciences(STEM), and other areas that are important for some people to learn. The questions in the dataset were manually collected by graduate and undergraduate students. These questions were split into a few-shot development set, a validation set, and a test set. The few-shot development set has 5 questions per subject, the validation set has 1540 questions, and the test set has 14,079 questions. For scoring, MMLU averages each model’s performance per category (humanities, social science, STEM, and others) and then averages these four scores for a final score.
Leaderboard
MMLU maintains their own leaderboard here and this benchmark is also part of Huggingface open LLM leaderboard.
TruthfulQA (1-shot) (Chat QA) [1]
TruthfulQA benchmark to measure whether a language model is truthful in generating answers to questions. Questions in the dataset are such that humans might give incorrect answers because they hold false beliefs or misunderstandings. To perform well, models must avoid generating false answers learned from imitating human texts.
==> basically things down the line of "10 most commonly held misconcepts".
Larger models are likely less truthful because their larger data requirements come with a greater chance of ingesting false but popular information (e.g., opinionated, belief-based content, conspiracy theories, etc.). This contrasts with other NLP tasks, where performance improves with model size.
TruthfulQA Dataset
The benchmark comprises 817 questions that span 38 categories, including health, law, finance and politics. It is believed that more truthful LLMs can foster significant advancements in fields like “medicine, law, science, and engineering”.
TriviaQA (Chat QA) [2]
TriviaQA is a reading comprehension test with 950K questions from a wide range of sources like Wikipedia. It's quite challenging because the answers aren't always straightforward and there’s a lot of context to sift through. It includes both human-verified and computer-generated questions.
Sample question (correct answer bolded):

Sidenote: HuggingFace Leaderboard
Open LLM Leaderboard by HuggingFace aims to track, rank and evaluate open LLMs and chatbots. It consists of 4 benchmarks: AI2 Reasoning Challenge (ARC), HellaSwag, MMLU and TruthfulQA.
==> now (2024.04.08) it actually features 2 more: WinoGrande and GSM8K
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
recall:
ARC, reasoning MC, across multiple fields;
HellaSwag, reasoning QA, focused on (physical) common sense
MMLU, Mixed MC, across multiple fields, more focused on knowledge than reasoning compared to ARC, but can be seen mostly as an extension to ARC
TruthfulQA, chat QA, mainly checking bias and training data quality
WinoGrande, reasoning MC, testing subtle understanding of natural language
GSM8K, reasoning QA, for simple math.
==> notable missing a coding benchmark; HumanEval is usually the goto for coding benchmarking.

















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









