










Teaser by Bard
DeConvolution (also known as transposed convolution) is a mathematical operation that reverses the effects of convolution. It is a useful operation in many signal processing and image processing applications, such as image super-resolution, image denoising, and image segmentation.
How DeConvolution works
Convolution is a mathematical operation that combines two signals to produce a third signal. It is often used to extract features from signals or to filter out noise. DeConvolution is the opposite of convolution. It takes a signal and produces two signals that, when convolved together, produce the original signal.
Applications of DeConvolution
DeConvolution is used in many signal processing and image processing applications. Here are a few examples:
- Image super-resolution: DeConvolution can be used to increase the resolution of images. This is done by convolving the image with a filter kernel that is designed to extract high-frequency information. The deconvolution operation is then used to reconstruct the high-frequency information, which results in a higher-resolution image.
- Image denoising: DeConvolution can be used to remove noise from images. This is done by convolving the image with a filter kernel that is designed to extract the noise. The deconvolution operation is then used to reconstruct the image without the noise.
- Image segmentation: DeConvolution can be used to segment images, which means to identify different objects or regions in an image. This is done by convolving the image with a filter kernel that is designed to extract features that are specific to the objects or regions of interest. The deconvolution operation is then used to reconstruct the image in a way that highlights the objects or regions of interest.
DeConvolution is a powerful tool that can be used to solve a variety of signal processing and image processing problems. It is a key component of many deep learning models, such as autoencoders and generative adversarial networks.
==> here
Recent state-of-the-art (by 2021) methods employ an encoder-decoder structure for image semantic segmentation. The encoder part is a fully convolutional network (FCN) used to extract features at different resolutions. The decoder part, which is often termed as a “deconvolution”, is used to gradually upsample the feature maps obtained by the encoder into a semantically segmented output image. The FCN proposed by Shelhamer et al. [6] is arguably the first deep learning model designed for the task of image pixel-wise classification.
The Mathematical DeConv
Definition and basics
The deconvolution process is the mathematical process of removing the effects of the impulse response from a signal to obtain the original signal. In simple terms, the process of convolution can be viewed as a mathematical transformation of two functions, f and g, to produce a third function h. The process of deconvolution is the inverse of the convolution process.
In other words, if h = f * g, where * is the convolution operator, then deconvolution aims to recover the original signal, f, by knowing g and h. The process of deconvolution involves finding the inverse of the convolution operator, which can be challenging because the convolution operator is not always an invertible function.
Deconvolution can be done in two ways: linear and non-linear. Linear deconvolution assumes that the system response is linear and time-invariant. Non-linear deconvolution, on the other hand, does not make this assumption and can be used to recover signals in more complex systems.
Convolution and its relation to deconvolution
Convolution and deconvolution are inverse operations. The convolution of two functions, f and g, is defined as:
(f * g)(t) = ∫f(τ)g(t - τ)dτ
Where * is the convolution operator, f and g are functions, t is the independent variable, and τ is the integration variable. Convolution is a mathematical operation that combines two functions to produce a third function that describes how one of the original functions modifies the other.
The deconvolution of two functions, f and g, is defined as:
f(t) = (f * g)(t) / g(t)
Where g(t) is the impulse response of the system. Deconvolution is the process of reversing the effects of convolution by finding the original signal from the convolved signal and the impulse response of the system.
DeConv Layer in Machine Learning
DeConv is Upsampling, With Trainable Parameters
Why use deconvolution layers in deep learning?
The deconvolution operation is an upsampling procedure that both upsamples feature maps and keeps the connectivity pattern. The deconvolutional layers essentially increase and densify the input by employing convolution-like procedures with numerous filters. Deconvolution, unlike previous scaling algorithms, has trainable parameters. During network training, the weights of deconvolutional layers are constantly updated and refined. It is accomplished by inserting zeros between the consecutive neurons in the receptive field (==> the region perceived by the model, i.e. the extracted feature map by conv. layer) on the input side, and then one convolution kernel with a unit stride is used on top.
Transposed Convolution vs Deconvolution
==> note some people do not distinguish between these layers "ConvTranspose" and "DeConv"
==> here we actually have a conflicting use of terms by our two sources:
from: Why use deconvolution layers in deep learning?
A deconvolutional layer reverses the process of a typical convolutional layer, i.e. it deconvolutes the output of a standard convolutional layer.
The spatial dimension created by the transposed convolutional layer is the same as the spatial dimension generated by the deconvolutional layer. Transposed convolution reverses the ordinary convolution by dimensions only, not by values.
==> which suggests that instead of using trainable weights in filters, we might simply use, say identity filter to only enlarge the input in this "transposed convolution". The author is regarding both as layers in NNs.
while from: https://medium.com/@marsxiang/convolutions-transposed-and-deconvolution-6430c358a5b6
Deconvolution is a term floating around next to transposed convolutions, and the two are often confused for each other. Many sources use the two interchangeably, and while deconvolutions do exist, they are not very popular in the field of machine learning.
A deconvolution is a mathematical operation that reverses the effect of convolution. Imagine throwing an input through a convolutional layer, and collecting the output. Now throw the output through the deconvolutional layer, and you get back the exact same input. It is the inverse of the multivariate convolutional function.
On the other hand, a transposed convolutional layer only reconstructs the spatial dimensions of the input. In theory, this is fine in deep learning, as it can learn its own parameters through gradient descent, however, it does not give the same output as the input. ==> the author actually just casually pointed out the heart of ML, to guess rather than solve math problems ;)
==> clearly the author use the term "transposed convolution" as the previous one's "deconvolution"; here we use "deconvolution", or "DeConv" interchangeably with "transposed convolution" or "ConvTranspose", since we are focused on its role in NN.
Update0
on 2024.01.10
before reading on, about the visualization and the mental gymnastics about the meaning of the cfg. parameters, checkout this better explanation illustration I just found:
https://towardsdatascience.com/what-is-transposed-convolutional-layer-40e5e6e31c11
and here is a well written doc. with pytorch convTranspose examples
14.10. Transposed Convolution — Dive into Deep Learning 1.0.3 documentation
Another Note on Popular ConvTranspose API Choice
torch.nn.functional.conv_transpose2d — PyTorch 2.1 documentation
as you can check above,
instead of output shape, the cfg. now use DeConv input padding to define output shape, as demonstrated clearly in pyTorch API:
padding –
dilation * (kernel_size - 1) - paddingzero-padding will be added to both sides of each dimension in the input. Can be a single number or a tuple(padH, padW). Default: 0 ==> so this is the conv paddingfor the key DeConv padding, I found an alternative API doc. for the same function from ConvTranspose2d — PyTorch 2.1 documentation
output_paddingcontrols the additional size added to one side of the output shape. See note below for details.The
paddingargument effectively addsdilation * (kernel_size - 1) - paddingamount of zero padding to both sizes of the input. This is set so that when a Conv2d and a ConvTranspose2d are initialized with same parameters, they are inverses of each other in regard to the input and output shapes. However, whenstride > 1, Conv2d maps multiple input shapes to the same output shape.output_paddingis provided to resolve this ambiguity by effectively increasing the calculated output shape on one side. Note that .output_paddingis only used to find output shape, but does not actually add zero-padding to output. ==> hence output_padding is our DeConv paddingnote that we derived later, the DeConv padding is (l - 1)*(k - 1) - P_conv, and the difference is due to pyTorch dilation is likely simply due to "dilation" in pyTorch is:
"the spacing between kernel elements. Can be a single number or a tuple
(dH, dW). Default: 1", while the we take the normal meaning dilation, and py_dilation = l - 1.as for TensorFlow,
https://www.tensorflow.org/api_docs/python/tf/keras/layers/Conv2DTranspose
it actually offers a similar but less expressive API, so we would think in terms of PyTorch now on; the latter is the also the most dominant framework anyway.

Visualize DeConv
https://medium.com/@marsxiang/convolutions-transposed-and-deconvolution-6430c358a5b6
To control the extent in which the input is compressed or expanded, additional upsampling and downsampling techniques are applied. The most common ones are padding, strides, and dilations.
- To increase output dimensions, padding is usually used. The edges of the input are filled with 0’s, which do not affect the dot product, but gives more space for the kernel to slide.

Padding 1
- Strides control how many units the kernel slides at a time. A high stride value can be used to further compress the output. The stride is usually and implicitly set to 1.
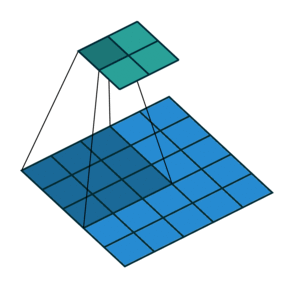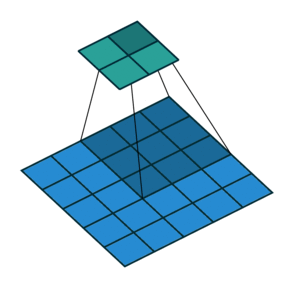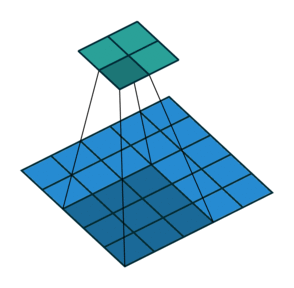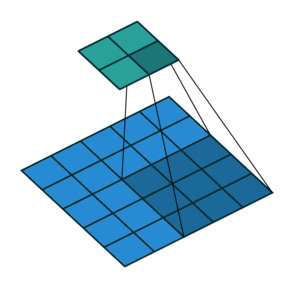
Stride is (2, 2)
- Dilations can be used to control the output size, but their main purpose is to expand the range of what a kernel can see (now you have visualized "receptive field") to capture larger patterns. In a dilation, the edge pieces of the kernel are pushed further away from the center piece.
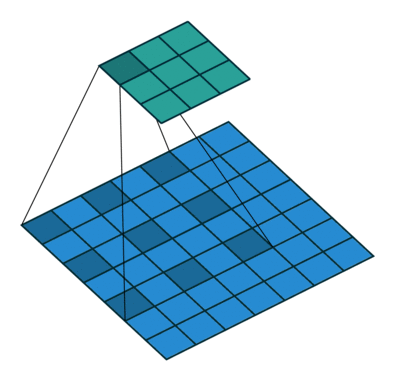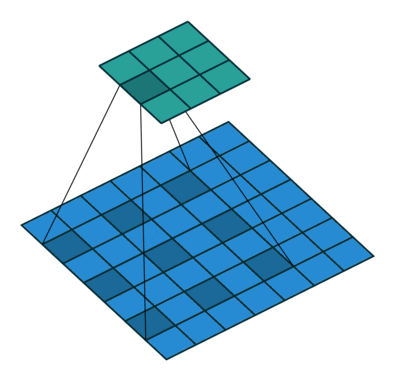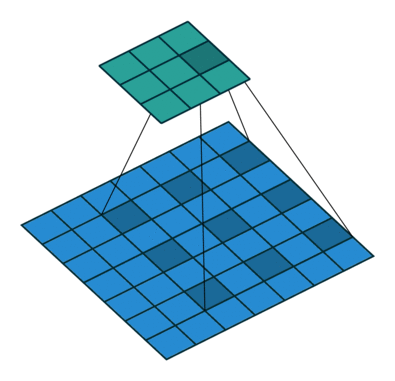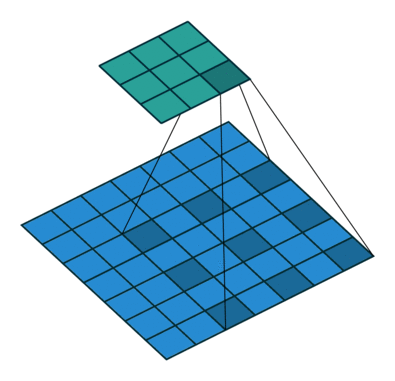
Dilation of 2
Dilated Convolution Explained | Papers With Code
Dilated Convolutions are a type of convolution that “inflate” the kernel by inserting holes between the kernel elements. An additional parameter l (dilation rate) indicates how much the kernel is widened. There are usually l−1 spaces inserted between kernel elements.
a more detailed explanation found in Dilated Convolution - GeeksforGeeks
The transposed convolutional layer, unlike the convolutional layer, is upsampling in nature. Transposed convolutions are usually used in auto-encoders and GANs, or generally any network that must reconstruct an image.
The word transpose means to cause two or more things to switch places with each other, and in the context of convolutional neural networks, this causes the input and the output dimensions to switch.
In a tranposed convolution, instead of the input being larger than the output, the output is larger. An easy way to think of it is to picture the input being padded until the corner kernel can just barely reach the corner of the input. ==> of course how to pad the images would be determined by the same set of parameters as conv (padding, stride), but with subtly different meaning, i.e. they are specified as they are for the convolution operation that the deconvolution is supposed to undo.

Transposed Convolution
Downsampling and Upsampling… In Reverse
When downsampling and upsampling techniques are applied to transposed convolutional layers, their effects are reversed. The reason for this is for a network to be able to use convolutional layers to compress the image, then transposed convolutional layers with the exact same downsampling and upsampling techniques to reconstruct the image.
==> remind yourself again, BLUE ==> INPUT; TEAL==> OUTPUT
- When padding is ‘added’ to the transposed convolutional layer, it seems as if padding is removed from the input, and the resulting output becomes smaller.

Without padding, the output is 7x7, with padding it is 5x5.
==>we ignore the padding on original image when try to upsampling it back
==> in effect, reducing input size
- When strides are used, they instead affect the input, instead of the output.

Strides (2, 2) increases the output dimension from 3x3 to 5x5.
==> we have to account for compression rate when upsampling back the original image
==> in effect, stride works to "dilate" input of DeConv, i.e. introduce padding in-between pixels
Math of DeConv
Terminology:
use H for height,
W for width,
D for depth, (though we do not consider 3D Conv/DeConv to be different from 2D Conv/DeConv, since it really is just one more layer of traversal),
l for dilation,
S for stride,
K for kernal,
P for padding;
Sw would be stride size along W,
lw would be dilation rate along W,
Kw would be Kernel dimension along W,
Pr would be padding to the right of W,
Pb would be padding to the bottom of H.
Convolution Dimension Calculation
since all dimensions are identical for conv we simply showcase H.
(eq.1)
(subsequent equations would drop floor() for convenience; it goes without saying we are dealing with integer arithmetic in natural domain here and input dimension with padding cannot be less than dilated kernel,)
therefore
(eq.2)
DeConvolution Dimension Calculation
first thing first, the input of Conv. would be output of DeConv. and vice versa, so switch subscript first:
(eq.3)
notice that: S, P, l, all retain the original meaning as for Conv. and that's why we must do some mental gymnatics when visualizing DeConv with padding and stride > 1 as shown above.
==> this equation looks nice but it's missing DeConv input padding, we shall see them later.
DeConv Actual Kernel and Stride
==> DeConv do not necessarily use the same kernel dimensions as it Conv counterpart;
==> DeConv kernels themselves always move by stride=1, or S^de = 1
these info. together with (Pt, Pb, S, l, K, Hi) let us compute DeConv input padding.
DeConvolution (Anti-)Padding Calculation
1. inter-pixel padding
here S functions as l for conv. (while l for DeConv is a output enlarge factor)
for S > 1, we pad S - 1 0s in between each pixel for the DeConv input;
2. frame padding
let P^de_t be the top padding of DeConv input, and notice by (eq.1), with S^de = 1, DeConv I/O dimension should satisfy:
(eq.4)
we ignore dilation for DeConv, since DeConv is upsampling by nature, and there is no sense in adding dilation rate for DeConv itself (, NOT the same as knowing the dilation rate used by Conv)
==> now we acknowledge the fact in most cases, either Pt == Pb or one of them is 0, and we simplify eq3, 4 to:
(eq.5)
then by eq.5 we get:
(eq.6)
obviously padding cannot be negative, i.e. it requires,
Now remember we are dealing with interger arithmetic here, and we have dropped the floor() function from eq.1; picking it back means whenever full divide by S_h is not possible, we lose information going from eq1 to eq.2. and all subsequent calculation is not accurate and we can get is a range for Hout given Hin, Ph, Kh, Sh, lh.
in practice we either specify P^de or H_out, and the later is more popular, used by major frameworks, and directly address main goal of this operator, i.e. to get a larger image.
Tasks Using DeConv
1. Segmentation
https://medium.com/geekculture/deconvolution-and-how-it-works-and-its-importance-80ce8f137e1b
Image Segmentation is dividing an image into multiple segments or classes. Segmentation makes it easier to understand and analyze the images. Segmentation is a computationally very expensive process because we need to classify each pixel for this.

Image Segmentation (Credits: Codicals)
Since Segmentation is about finding classes of every pixel, here downsampled Feature map cannot work. So we use DeConvolution to convert it into an image of the same dimensions as of the Original Image.
DeConvolution is done after applying the Convolution layer, to maintain the Output size of the image same as Original Image.
2. Deconvolution Network for Understanding CNN-like Networks
again, from Why use deconvolution layers in deep learning?
shows how deconv networks can be applied to retrive how CNN-like networks extract features.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









