







开源社区开发者画像
项目社区:https://gitee.com/G-SCHENG/WBDCA
目标与分工
目标
-
评估模型建立
对开发者进行画像,实际上即是建立一个数据模型,用该模型对开发者进行描述。项目名为“开源社区开发者画像",其直接任务就是建立一个模型,能够对开源社区开发者的各方面能力进行评估。我们希望能够建立一个合理的能力评估模型,能够对所研究的(GitHub)开发者给出恰当的评价。
-
数据获取
项目需要对开发者进行画像,那么开发者的信息是必不可少的。项目需要对 GitHub 上开发者的信息有选择性的获取(全量获取会使效率降低,获取后的多余数据也不会进行任何处理而是丢弃,故不选用全量获取方式),为下游的数据分析和后续的模型修改提供原始数据。项目应能够正确获取GitHub上指定用户的信息;在保证正确率的基础上,能够提高获取的效率。
-
数据分析与存储
从开源社区(GitHub)上获取用户数据后,还要对数据再提取,即对数据进行分析,为模型提供所需数据。
分析后得到的数据需要存入数据库中,方便后续对数据进行查询。
-
数据展示
项目最终需要将开发者的模型数据进行展示。
分工
-
数据获取
数据获取的内容为从GitHub上获取所需的开发者信息,这一部分由Felix Hua 负责。
-
数据分析与存储
将从GitHub上获取的数据进行解析和处理;并分析好的数据存入数据库(MySQL)中,这一部分由pan-peizheng负责。
-
数据展示
从数据库中获取信息,并将数据以图表形式展示在页面上。这一部分由G-SCHENG负责。
技术研发进展
-
爬虫
利用GitHub API获取我们所需信息;当然现有的API并不能满足我们的需求,我们还通过解析网页获取所需信息。
-
数据库
将开发者信息进行分割,并存入不同的表中,实现分表存储和查询;同时,我们还使用了视图,加强了数据的安全性,并提高了数据的查询效率。
-
可视化展示
利用echarts插件,将开发者信息以图表形式呈现;同时,我们将数据在一到两个页面中展示,保证了数据的集中性,方便了他人更快、更直观地了解信息。
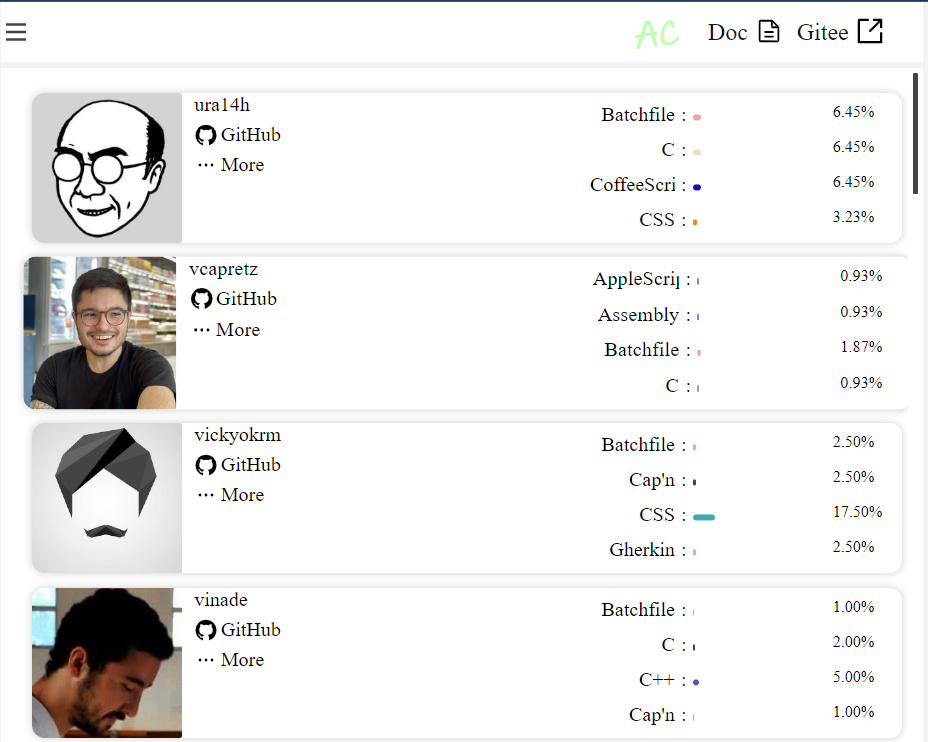
在该页面我们可以看到项目中多个开发者的基本信息,包括其姓名、常用语言等。同时,还可以点击“GitHub”跳转到该开发者的GitHub主页,方便了解开发者的更多信息。
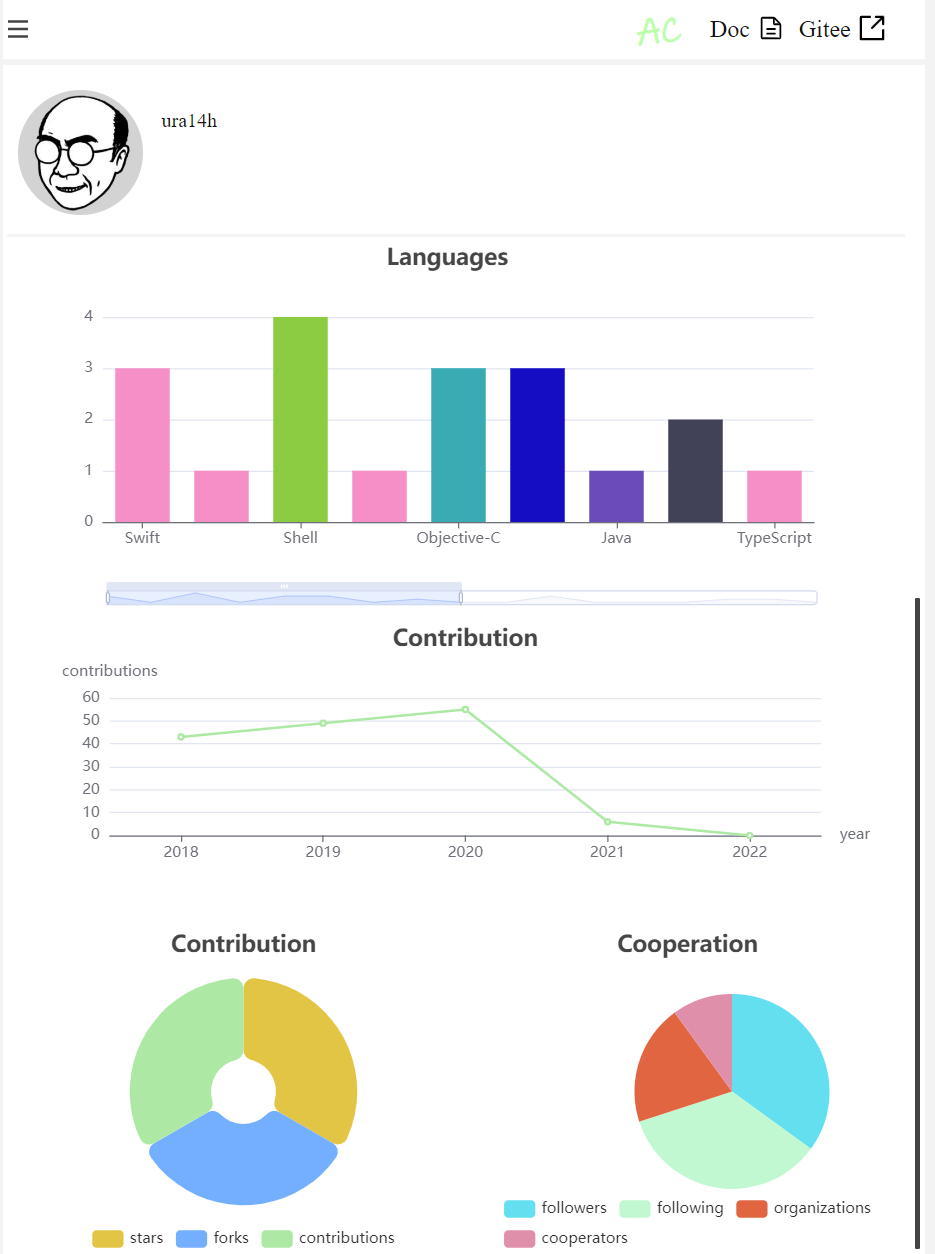
这一页面我们可以看到开发者的详细信息。同时,我们利用图表展示了一些信息的占比、增长态势或者联系关系。
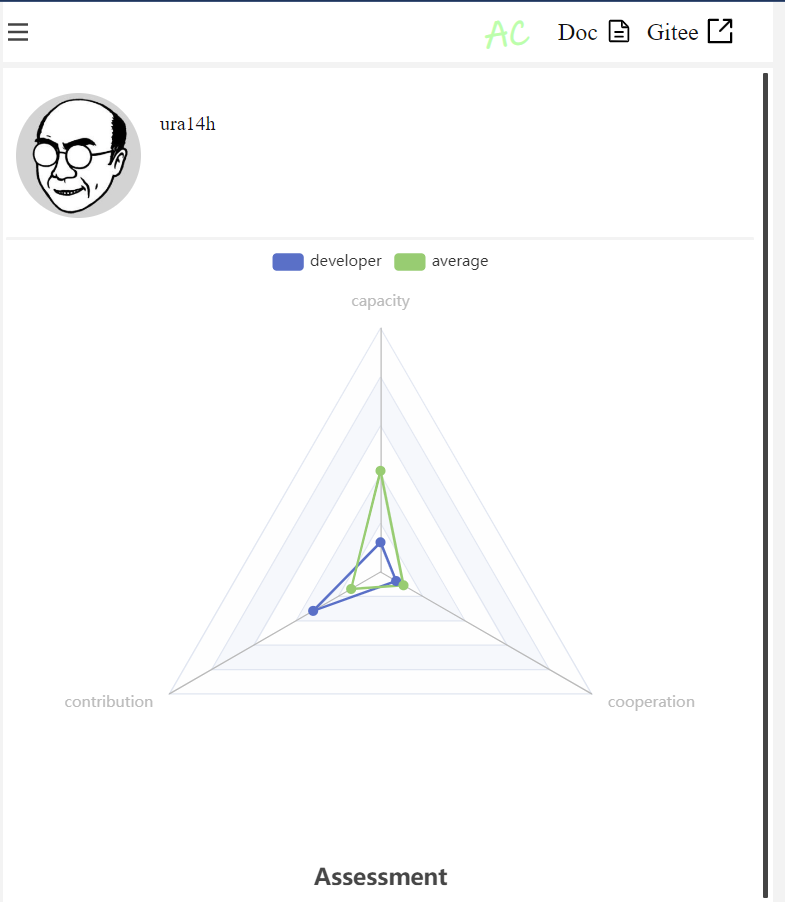
对于开发者的能力,我们给出了一些评分,用雷达图表现用户的侧重点。同时,我们还给出了项目的平均评分,但是由于项目中部分人的某些方面能力确实比较低,所以项目整体上的能力评估分数比较低。
开源开发工作
代码托管平台
以Gitee作为代码托管平台,更好地管理代码。选择 MuLan 协议作为开源协议,将我们的代码进行分享。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4QOkuO91-1671874058249)(null)]
分支管理
将任务、代码进行分割,主要分成前端和后端两个部分,创建两个分支。Master分支一般只做为代码的保存分支,而不会对其进行直接修改。对代码的修改均在两个分支上实现,通过merge操作合并代码。
总结与展望
亮点
本项目的核心任务在于给出一个评估模型并将其可视化。
我们通过调研给出了评价一个开发者能力的三个维度,并尝试构建一个评价体系。对于评估规则,我们给出了自己的判断,同时,也对数据进行了统计分析,保证评价体系的相对客观合理。
不足
-
效率
我们尽可能尝试提高获取数据的效率,但是获取多人数据时效率捉襟见肘。
-
数据实时性
我们的数据不具有实时性,比如一个人在12月提交了commits,但是我们的数据可能还停留在11月。
-
数据模型
数据模型的建立基于对已获取项目的研究,所以这一个模型不能够保证完全客观;同时,在极端数据的处理方面,还有较大的进步空间。
-
数据展示
目前我们的数据展示只针对部分数据,后续我们会尝试解析并展示更多有用的数据。
未来计划
-
高效爬虫
后续工作中我们会尝试引入异步、多线程的爬虫方式,从而更高效地获取数据,降低时间成本。
-
定期更新
我们会尝试定期从GitHub上获取新的数据,并对数据进行更新,保证数据不至于过于落后。
-
功能添加
我们会尝试搭建一个管理系统,能够对项目、个人的信息进行获取和分析,并且能够提供一个友好的查询方式。
-
模型优化
我们会对模型进行进一步的调研工作,并尝试对现有模型做修改和优化,以期给出一个合理、客观的评价体系。

















 996
996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









