










回顾Transformer
在NLP领域,对语言建模最常用的模型就是RNNS(包括LSTM),但是RNNS存在一些问题,比如学习长期依赖的能力很弱(LSTM语言模型平均只能建模200个上下文词语),而且学习速度也很慢。
在2017年,谷歌的一位学者提出了Transformer架构,其示意图如下图所示:Transformer不懂的可以看博客图解Transformer

虽然Transformer相比LSTM可以建模更长的序列,但是也需要对输入序列设置一个固定的长度(比如BERT中默认长度是512)。如果输入序列长度小于固定长度可以通过填充的方式来解决,如果序列长度大于固定长度,常用的做法是将序列切割成多个segments,切割的时候并没有考虑句子的自然边界,而是根据固定长度来划分序列,在训练的时候每个segment单独训练,并没有考虑相邻的segment之间的上下文信息,所以segment之间的语义是不完整的,如下图(a)所示:

在图(a)中,输入序列是
[
x
1
,
,
,
x
8
]
[x_1,,,x_8]
[x1,,,x8],固定长度是4,将输入序列分成2个segment进行训练,而且每个segment都要从头开始训练,segment2并没有利用到segment1的上下文信息,这种现象称为上下文碎片(context fragmentation)。
在预测的时候,会对固定长度的segment做计算,一般取最后一个位置的隐向量作为输出。为了缓解context fragmentation,在每做完一次预测之后,就对整个序列向右移动一个位置,再做一次计算,如上图(b)所示,这导致计算效率非常低。
Transformer-XL
为了解决上述的问题,在Transformer的基础上,提出了Transformer-XL,有两点创新:Segment-Level Recurrence和Relative Position Encodings
segment level recurrence
在对当前segment进行处理的时候,缓存并利用上一个segment中所有layer的隐向量序列,而且上一个segment的所有隐向量序列只参与前向计算,不再进行反向传播,这就是所谓的segment-level Recurrence。

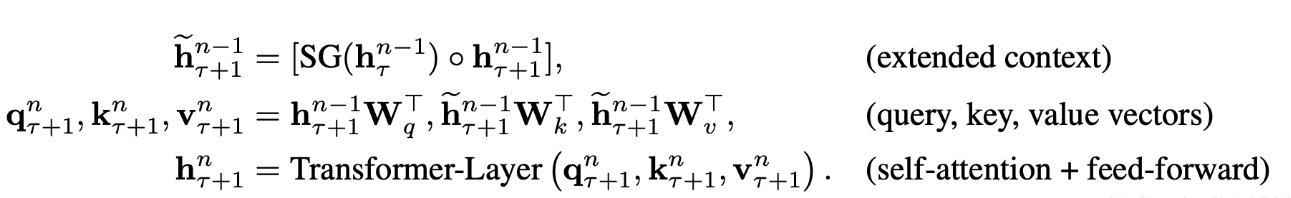

训练和预测过程如上图所示。
在图(a)中,与Transformer不同的是绿色线的部分,绿色线表示了上一个segment传递给当前segment的上下文信息,当前segment的第n层的每个隐向量的计算,都依赖于第n-1层的当前位置的隐向量和前L-1个隐向量。
在图(b)中,当前segment(除了第一个segment)中的Transnformer-XL的第
n
n
n层的每个节点都依赖前面
(
n
−
1
)
(
L
−
1
)
(n-1)(L-1)
(n−1)(L−1)个token,所以最后一层的节点依赖的token最多。n通常要比L小很多,比如在BERT中,N=12或者24,L=512,依赖关系长度可以近似为
O
(
N
∗
L
)
O(N*L)
O(N∗L) 。在对长文本进行计算的时候,可以缓存上一个segment的隐向量的结果,不必重复计算,大幅提高计算效率。
Relative Position Encodings
在vanilla Trm中,为了表示序列中token的顺序关系,在模型的输入端,对每个token的输入embedding,加一个位置embedding。位置编码embedding或者采用正弦\余弦函数来生成,或者通过学习得到。在Trm-XL中,这种方法行不通,每个segment都添加相同的位置编码,多个segments之间无法区分位置关系。Trm-XL放弃使用绝对位置编码,而是采用相对位置编码,在计算当前位置隐向量的时候,考虑与之依赖token的相对位置关系。具体操作是,在算attention score的时候,只考虑query向量与key向量的相对位置关系,并且将这种相对位置关系,加入到每一层Trm的attention的计算中。

整体计算公式

总结,Trm-XL为了解决长序列的问题,对上一个segment做了缓存,可供当前segment使用,但是也带来了位置关系问题,为了解决位置问题,又打了个补丁,引入了相对位置编码。
参考:
Transformer-XL介绍
Transformer-XL解读(论文 + PyTorch源码)















 2844
2844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









