









理解Laplacian矩阵
在GCN相关的理论知识中,都提到了Laplacian矩阵(拉普拉斯矩阵),那么GCN为什么要用拉普拉斯矩阵以及拉普拉斯矩阵是怎么来的却很少有人说明。下面通过一个列子来说明。
一个基于图的热传播模型

上图一个热传播模型,我们都知道热量只会从温度高的地方流向温度低的地方,再上图中,热量只会从温度高的节点流向温度低的节点,比如节点1会与节点0,2,4发生直接的热交换,会与其他间接连通的节点(比如节点8)发生间接的温度交换。
假设热量的流动满足牛顿冷却定律(热量传递的速度正比于温度梯度,直观上看,如果A,B两个地方接触,温度高的地方的热量会以正比于他们俩温度差的速度从A流向B。)
考虑图中某个节点
i
i
i随时间
t
t
t的变化可以用下式来刻画:
d
φ
i
d
t
=
−
k
∑
j
A
i
,
j
(
φ
i
−
φ
j
)
(1)
{\tag 1}{d\varphi_{i} \over dt} = -k\sum_{j}A_{i,j}(\varphi_{i}-\varphi_{j})
dtdφi=−kj∑Ai,j(φi−φj)(1)
变量说明:
φ
\varphi
φ表示图中节点的温度,
φ
i
\varphi_{i}
φi表示第
i
i
i个节点的温度。
A
A
A表示图的邻接矩阵,若节点i与节点j之间有边连接,则
A
i
,
j
=
1
A_{i,j}=1
Ai,j=1否则
A
i
,
j
=
0
A_{i,j}=0
Ai,j=0
k
k
k是与节点的比热容有关的常数。
注意到上图是一个无向图,所以 A A A是对称阵,节点没有回到自己的边,所以 A A A对角线的元素都为0。所以(1)式表示只有与节点 i i i直接连接才会发生热交换。
对(1)式使用乘法分配律:
d
φ
i
d
t
=
−
k
[
φ
i
∑
j
A
i
,
j
−
∑
j
A
i
,
j
φ
j
]
=
−
k
[
φ
i
D
e
g
(
i
)
−
∑
j
A
i
,
j
φ
j
]
(2)
\begin{aligned} \tag{2}{d\varphi_{i} \over dt} = & -k[\varphi_{i}\sum_{j}A_{i,j} -\sum_{j}A_{i,j}\varphi_{j}] \\ =& -k[\varphi_{i}Deg(i) -\sum_{j}A_{i,j}\varphi_{j} ] \end{aligned}
dtdφi==−k[φij∑Ai,j−j∑Ai,jφj]−k[φiDeg(i)−j∑Ai,jφj](2)
D
e
g
(
i
)
Deg(i)
Deg(i)表示对节点i求度,对于无向图来说,某个节点
i
i
i的度就是邻接矩阵
A
A
A中第
i
i
i行的元素和。
若对图中的所有节点都用(2)式计算,则可以写成矩阵的形式:
[
d
φ
1
d
t
d
φ
2
d
t
.
.
.
d
φ
n
d
t
]
=
−
k
[
D
e
g
(
1
)
∗
φ
1
D
e
g
(
2
)
∗
φ
2
.
.
.
D
e
g
(
n
)
∗
φ
n
]
+
k
A
[
φ
1
φ
2
.
.
.
φ
n
]
\begin{bmatrix} {d\varphi_{1} \over dt} \\ {d\varphi_{2} \over dt} \\ ... \\ {d\varphi_{n} \over dt} \end{bmatrix} = -k \begin{bmatrix} Deg(1) *\varphi_{1} \\ Deg(2) *\varphi_{2}\\ ... \\ Deg(n) *\varphi_{n} \end{bmatrix} +kA \begin{bmatrix} \varphi_{1} \\ \varphi_{2}\\ ... \\ \varphi_{n} \end{bmatrix}
⎣⎢⎢⎡dtdφ1dtdφ2...dtdφn⎦⎥⎥⎤=−k⎣⎢⎢⎡Deg(1)∗φ1Deg(2)∗φ2...Deg(n)∗φn⎦⎥⎥⎤+kA⎣⎢⎢⎡φ1φ2...φn⎦⎥⎥⎤
然后我们定义向量
Φ
=
[
φ
1
,
φ
2
,
.
.
.
φ
n
]
T
\varPhi = [\varphi_{1}, \varphi_{2},...\varphi_{n}]^{T}
Φ=[φ1,φ2,...φn]T,那么有
d
Φ
d
t
=
−
k
D
Φ
+
k
A
Φ
=
−
k
(
D
−
A
)
Φ
=
−
k
L
Φ
(3)
\begin{aligned} \tag{3} {d\varPhi \over dt} =& -kD\varPhi + kA\varPhi \\ = & -k(D-A)\varPhi \\ = &-kL\varPhi \end{aligned}
dtdΦ===−kDΦ+kAΦ−k(D−A)Φ−kLΦ(3)
其中
D
=
d
i
a
g
(
D
e
g
(
1
)
,
D
e
g
(
2
)
,
.
.
.
,
D
e
g
(
n
)
)
D=diag(Deg(1), Deg(2), ..., Deg(n))
D=diag(Deg(1),Deg(2),...,Deg(n))称为度矩阵,是一个对角矩阵。
L
=
D
−
A
L=D-A
L=D−A就是拉普拉斯矩阵。
(3)式的意义:刻画了拓扑空间中的有限节点,单位时间状态的变化正比于 − L -L −L作用在状态 Φ \varPhi Φ
常用的拉普拉斯矩阵有3种,
- L = D − A L=D-A L=D−A
- L = D − 0.5 L D − 0.5 L =D^{-0.5}LD^{-0.5} L=D−0.5LD−0.5,称作对称规范化的拉普拉斯矩阵,很多GCN论文种都是这种
- L = D − 1 L L = D^{-1}L L=D−1L,称作随机游走规范化的拉普拉斯矩阵。
推广到GCN
现在问题已经很明朗了,只要你给定了一个空间,给定了空间中存在一种东西可以在这个空间上流动,两邻点之间流动的强度正比于它们之间的状态差异,那么何止是热量可以在这个空间流动,任何东西都可以!
自然而然,假设在图中各个结点流动的东西不是热量,而是特征(Feature),而是消息(Message),那么问题自然而然就被推广到了GCN。所以GCN的实质是什么,是在一张Graph Network中特征(Feature)和消息(Message)中的流动和传播!这个传播最原始的形态就是状态的变化正比于相应空间(这里是Graph空间)拉普拉斯算子作用在当前的状态。
以上内容转载自:如何理解 Graph Convolutional Network(GCN)
GCN推导
上面理解了GCN中拉普拉斯矩阵的作用,阐述了特征、消息等在图数据结构中流动和传播的可行性,我们运用GCN的目的就是学习到graph的特征,然后基于这些特征对下游任务做一些处理。
那么如何运用GCN学习到graph的特征呢,考虑CNN网络是怎么学习图像的特征的,是用卷积来实现的,但是图像是规则的,而图是不规则的,所以不能用CNN中的卷积来处理不规则的graph,后来有学者借鉴傅里叶变换中的卷积来在graph空间中使用卷积。
我们知道线性代数中的特征方程定义是: A V = λ V AV = \lambda V AV=λV,其中 A A A是一个方阵, V V V是 A A A的特征向量, λ \lambda λ是对应的特征值。若我们将上述定义推广, A A A是一种变换,则 V V V就是其特征函数。
拉普拉斯算子
拉普拉斯算子其实就是对函数求二阶微分。比如
f
(
x
)
=
x
3
,
则
Δ
f
=
6
x
f(x) = x^3,则\Delta f = 6x
f(x)=x3,则Δf=6x
关于拉普拉斯算子的物理意义可以看:为什么 空间二阶导(拉普拉斯算子)这么重要?
下面我们看看拉普拉斯算子
Δ
\Delta
Δ的特征函数。
Δ
e
−
i
w
t
=
∂
2
e
−
i
w
t
∂
t
2
=
−
w
2
e
−
i
w
t
\Delta e^{-iwt} = {\partial^2e^{-iwt} \over \partial t^2} = -w^2e^{-iwt}
Δe−iwt=∂t2∂2e−iwt=−w2e−iwt
所以
e
−
i
w
t
e^{-iwt}
e−iwt就是拉普拉斯算子的特征函数。
Graph上的傅里叶变换
传统的傅里叶变换为:
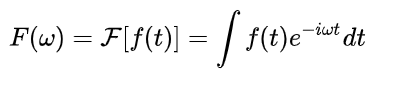
可以看到,传统的欧式空间上的傅里叶变换引入了拉普拉斯算子的特征函数,在Graph空间中,我们前面提到了拉普拉斯矩阵,所以自然而然就去考虑拉普拉斯矩阵的特征值和特征向量了。
由于
L
L
L是对称阵,所以有下式:
L
u
=
λ
u
Lu = \lambda u
Lu=λu,
u
是
L
的
特
征
向
量
u是L的特征向量
u是L的特征向量,设
f
f
f是定义在Graph上的N维向量,维度与Graph的节点数一致,由于
f
f
f是离散的,离散的积分就是求和,所以Graph上的傅里叶变换定义如下:
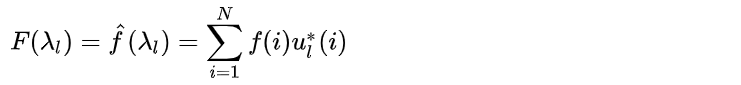
其中,
f
(
i
)
f(i)
f(i)表示Graph上的第i个节点,
u
l
(
i
)
u_{l}(i)
ul(i)表示第
l
l
l个特征向量的第
i
i
i个分量,所以在特征值
λ
l
\lambda_{l}
λl下的,
f
f
f在Graph上的傅里叶变换就是
f
与
u
l
f与u_{l}
f与ul的内积,
f
^
(
λ
l
)
\hat{f}(\lambda_{l})
f^(λl)是一个值而不是一个向量。
注:上述的内积运算是在复数空间中定义的,所以采用了
u
l
∗
(
i
)
u^{*}_{l}(i)
ul∗(i),也就是特征向量
u
l
∗
(
i
)
u^{*}_{l}(i)
ul∗(i)的共轭。


注意:(b)式说明了,将定义在Graph上的任意向量,表示成了拉普拉斯矩阵的特征向量的线性组合
Graph上的卷积
卷积定理
函数卷积的傅里叶变换是函数傅立叶变换的乘积,即对于函数
f
(
t
)
f(t)
f(t) 与
h
(
t
)
h(t)
h(t)两者的卷积是其函数傅立叶变换乘积的逆变换.
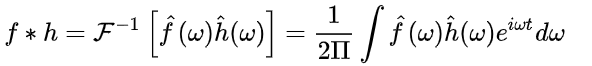
类比到Graph上并把傅里叶变换的定义带入,
f
f
f与卷积核
h
h
h 在Graph上的卷积可按下列步骤求出:

其中,
h
^
(
λ
l
)
=
∑
i
=
1
N
h
(
i
)
u
l
(
i
)
\hat{h}(\lambda_{l}) = \sum^{N}_{i=1}h(i)u_{l}(i)
h^(λl)=∑i=1Nh(i)ul(i)是卷积核
h
h
h在Graph上的傅里叶变换,也是一个值,不是向量。


(1)与(2)式是等价的,证明见:GCN中的等式证明
Deep learning中的 Graph Convolution
Deep learning中的Convolution就是要设计含有可被训练参数的kernel,从(1)式中很直观,就是
[
h
^
(
λ
1
)
.
.
.
h
^
(
λ
n
)
]
\begin{bmatrix} \hat{h}(\lambda_{1}) & & \\ & ... & \\ & & \hat{h}(\lambda_{n}) \end{bmatrix}
⎣⎡h^(λ1)...h^(λn)⎦⎤,令
g
θ
(
Λ
)
=
[
h
^
(
λ
1
)
.
.
.
h
^
(
λ
n
)
]
g_{\theta}(\Lambda) = \begin{bmatrix} \hat{h}(\lambda_{1}) & & \\ & ... & \\ & & \hat{h}(\lambda_{n}) \end{bmatrix}
gθ(Λ)=⎣⎡h^(λ1)...h^(λn)⎦⎤
则,(1)式变为
(
f
∗
h
)
G
=
U
g
θ
(
Λ
)
U
T
f
(f*h)_{G} = Ug_{\theta}(\Lambda) U^{T}f
(f∗h)G=Ugθ(Λ)UTf
下面的每一代GCN主要就是
g
θ
(
Λ
)
g_{\theta}(\Lambda)
gθ(Λ)的不同,为了避免混淆,称
g
θ
(
Λ
)
g_{\theta}(\Lambda)
gθ(Λ)为卷积核。
- 第一代GCN
《Spectral Networks and Deep Locally Connected Networks on Graphs》论文中提出了第一代GCN,
y
=
σ
(
U
g
θ
(
Λ
)
U
T
x
)
其
中
,
g
θ
(
Λ
)
=
[
θ
1
.
.
.
θ
n
]
y = \sigma(Ug_{\theta}(\Lambda)U^{T}x) \\其中, g_{\theta}(\Lambda) = \begin{bmatrix} \theta_{1} & & \\ & ... & \\ & & \theta_{n} \end{bmatrix}
y=σ(Ugθ(Λ)UTx)其中,gθ(Λ)=⎣⎡θ1...θn⎦⎤
σ
是
激
活
函
数
,
g
θ
(
Λ
)
初
始
化
赋
值
后
通
过
误
差
反
向
传
播
进
行
调
整
,
x
是
G
r
a
p
h
上
每
个
顶
点
的
f
e
a
t
u
r
e
v
e
c
t
o
r
\sigma是激活函数,g_{\theta}(\Lambda)初始化赋值后通过误差反向传播进行调整,x是Graph上每个顶点的feature vector
σ是激活函数,gθ(Λ)初始化赋值后通过误差反向传播进行调整,x是Graph上每个顶点的featurevector
该版本的GCN有一下缺点:
- 没有local信息。每次卷积都是所有顶点都参与运算,没有实现局部卷积和参数共享。
- 运算量大。每次卷积都要进行拉普拉斯矩阵分解和矩阵相乘,计算复杂度为 O ( n 2 ) O(n^{2}) O(n2)。
- 参数量大。每个卷积核参数量为n。
- 第二代GCN
《Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering》中提出了第二代GCN,

注意: λ i \lambda_{i} λi表示的是 L L L的第i个特征值, λ i j \lambda^{j}_{i} λij表示的 j j j次幂,
所以, y = σ ( ∑ j = 0 K − 1 a j L j x ) y = \sigma(\sum^{K-1}_{j=0}a_{j}L^{j}x) y=σ(j=0∑K−1ajLjx)
其中, a 1 , a 2 , , , a k − 1 a_{1}, a_{2},,,a_{k-1} a1,a2,,,ak−1是任意的参数,通过初始化赋值后利用误差反向传播调整。
图的邻接矩阵 A 的 k 次 幂 A的k次幂 A的k次幂具有一定的物理意义,若 A i , j K ≠ 0 A^{K}_{i,j} \not = 0 Ai,jK=0,则说明顶点 i 和 j 之 间 有 一 条 长 为 k i和j之间有一条长为k i和j之间有一条长为k的路径。所以 L L L的 k k k次幂也具有类似的物理意义,表示k-hop的感受野,也就是说与中心节点距离为k的路径上的节点都可以捕捉到。
所以第二代GCN的优点有:
- 卷积核只有K个参数,复杂度降低了。
- 矩阵变换后,不需要对 L L L进行矩阵分解了,直接用拉普拉斯变换进行即可
- 引入了k-hop的感受野,可以捕获局部特征。

- 第三代GCN
《Semi-supervised Classification with Graph Convolutional Networks》中提出了第三代GCN,是通过切比雪夫多项式来近似卷积核的,具体可以看Chebyshev多项式作为GCN卷积核















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









