









 本文介绍了一种名为UniFMIR的深度学习模型,应用于荧光显微镜图像恢复。该模型通过大规模预训练和微调,展示了在不同成像任务中的高精度和泛化能力,尤其在处理超分辨率、各向同性重建等任务上表现出色。研究者使用SwinTransformer技术优化模型,证实了其在提高图像质量和处理多样成像条件下的优势。
本文介绍了一种名为UniFMIR的深度学习模型,应用于荧光显微镜图像恢复。该模型通过大规模预训练和微调,展示了在不同成像任务中的高精度和泛化能力,尤其在处理超分辨率、各向同性重建等任务上表现出色。研究者使用SwinTransformer技术优化模型,证实了其在提高图像质量和处理多样成像条件下的优势。
期刊介绍:文章发表在《Nature Methods》期刊上。《Nature Methods》是一份覆盖生物医学研究方法的科学期刊,由Springer Nature出版。Nature Methods 是一个专注于生命科学领域新方法和重大技术改进的科学方法期刊。它发表经过实验验证的基础研究技术论文,旨在为积极参与实验室实践的学术和行业研究人员提供跨学科的交流平台。Nature Methods 期刊在科研界享有较高的声誉,被中科院SCI期刊分区评为 1区 生化研究方法期刊,并且是TOP期刊
文章标题为“Pretraining a foundation model for generalizable fluorescence microscopy-based image restoration”,作者为Chenxi Ma, Weimin Tan, Ruian He和Bo Yan,来自中国上海复旦大学的计算机科学学院以及智能信息处理的上海重点实验室
文章的接收日期是2023年7月27日,接受日期是2024年3月13日
文章的核心内容是关于一种名为UniFMIR的通用荧光显微镜图像恢复(fluorescence microscopy-based image restoration, FMIR)模型的研究。关键点的总结:
-
研究背景:荧光显微镜图像恢复技术在生命科学领域受到广泛关注,深度学习技术在此领域取得了显著进展。然而,现有的特定任务方法对于不同的荧光显微镜图像恢复问题具有有限的泛化能力。
-
UniFMIR模型:提出了一种通用的荧光显微镜图像恢复模型UniFMIR,旨在解决不同的图像恢复问题,如去噪、超分辨率(SR)、各向同性重建等。UniFMIR通过在大规模数据集上预训练并在特定子数据集上微调,展示了更高的图像恢复精度、更好的泛化能力和增加的多功能性。
-
数据集和实验:研究者收集了一个约30GB的大型训练数据集,涵盖14个公共数据集,包括多种成像模式、生物样本和图像恢复任务。UniFMIR在此数据集上预训练,并在不同的子数据集上微调,以覆盖各种退化条件、成像模式和生物样本。
-
性能评估:通过在五个任务和14个数据集上的演示,证明了UniFMIR能够有效地通过微调将预训练期间学到的知识转移到具体情况中,揭示清晰的纳米级生物分子结构,并促进高质量成像。
-
技术细节:UniFMIR模型采用多头多尾网络结构,包括特征增强模块,使用先进的Swin Transformer结构来增强特征表示,并重建通用且有效的特征,以实现高质量的荧光显微镜图像恢复。
-
结果:在超分辨率、各向同性重建、3D图像去噪、表面投影和体积重建等多个任务中,UniFMIR均展现出优越的性能,并与特定任务的最先进方法进行了比较。
-
泛化能力:UniFMIR在未见过的数据上进行了图像恢复性能的验证,证明了其出色的泛化能力。
-
资源和代码:提供了用于训练和测试的所有数据集和代码的访问链接,以及预训练模型和示例图像用于推理。
-
资助和贡献:研究得到了中国国家自然科学基金(NSFC)和上海市自然科学基金的支持。文章列出了所有作者的贡献。
这篇文章展示了深度学习在荧光显微镜图像恢复领域的潜力,特别是在提高模型泛化能力和处理多种成像任务方面。通过大规模预训练和微调,UniFMIR模型能够为不同的成像问题提供有效的解决方案。
其中性能评估上:
UniFMIR模型与以下几种方法进行了对比:
- XTC: 一种深度学习基础的荧光显微镜超分辨率模型。
- DFCAN: 用于图像超分辨率的深度学习模型。
- ENLCN: 用于宏观照片的单图像超分辨率模型。
- CARE: 一种基于内容感知的图像恢复方法,用于提高荧光显微镜图像质量。
- GVTNets: 一种用于3D图像去噪的U-Net基础的去噪模型。
- VCD-Net: 用于光场显微镜图像序列的实时体积重建的模型。
这些方法代表了不同的图像恢复任务,包括超分辨率、各向同性重建、3D图像去噪、表面投影和体积重建等。UniFMIR在这些任务上的性能通过定量和定性的指标进行了评估,并且在多个基准上展示了其优越的性能和泛化能力。
对比实验包括以下几个方面:
- 定量指标:使用峰值信噪比(PSNR)、结构相似性指数(SSIM)、归一化均方根误差(NRMSE)等指标来量化评估图像恢复结果的准确性。
- 计算复杂性:比较不同模型在处理输入数据时所需的计算量,包括浮点运算次数(FLOPs)和比特运算次数(BOPs)。
- 模型大小和参数数量:评估不同模型的大小和参数数量,以了解模型的效率和可扩展性。
- 运行时间:比较不同模型在CPU/GPU上运行所需的时间,以评估模型的实时性能。
通过这些对比,UniFMIR证明了其在不同成像任务中的有效性和优越性,特别是在泛化到未见过的数据和不同成像模态上的能力。
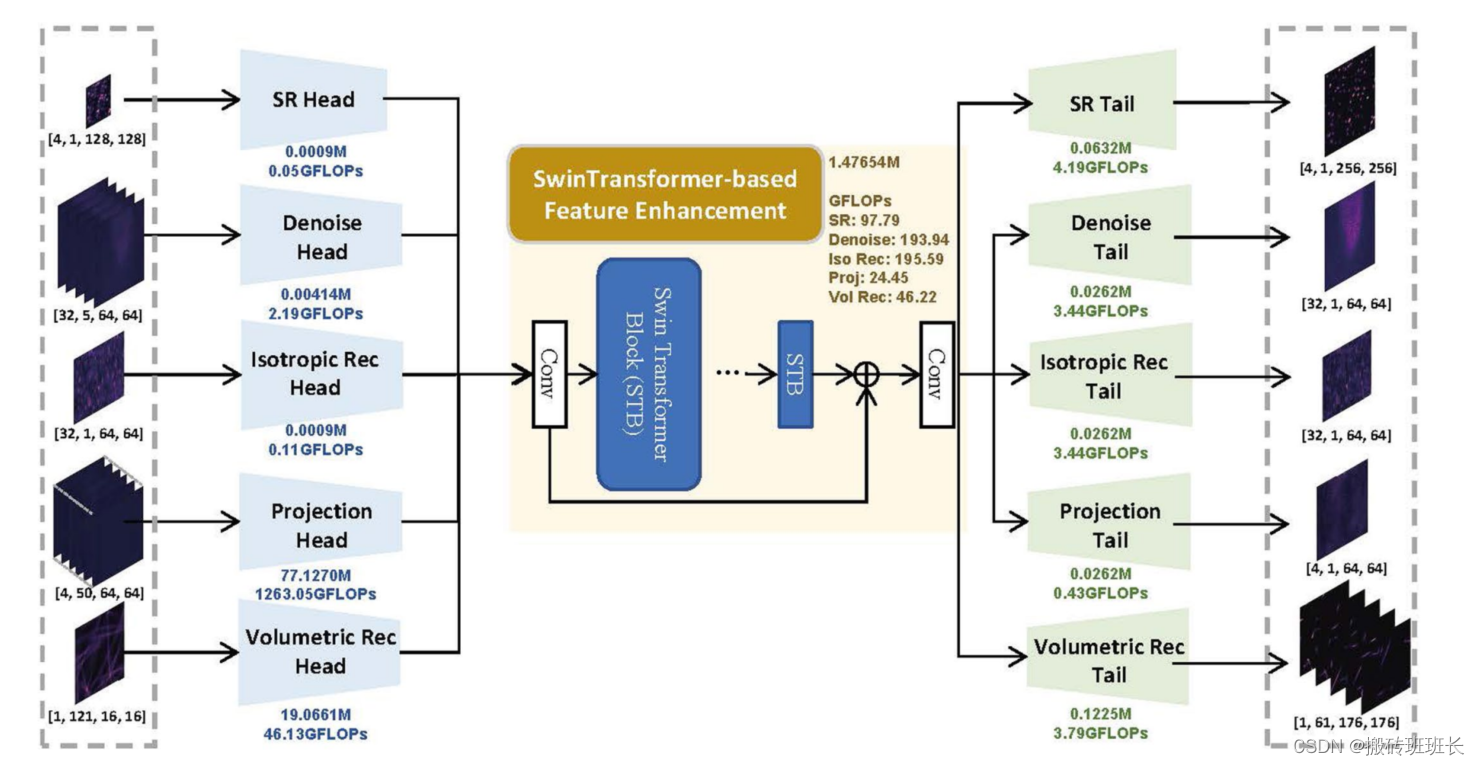
再其次主干网络使用是UniFMIR模型的主干网络(backbone),由几个关键组件构成的,这些组件共同工作以实现荧光显微镜图像的高质量恢复。以下是UniFMIR主干网络的主要部分:
-
多头部(Multihead)模块:这个模块包含多个特征提取分支,用于针对不同的图像恢复任务提取特定的浅层特征。
-
特征增强模块(Feature Enhancement Module):这是UniFMIR的核心部分,使用基于Swin Transformer的结构来增强特征表示。Swin Transformer是一种视觉Transformer,它通过层归一化、多头自注意力机制和多层感知机来处理输入特征。
-
多尾部(Multitail)模块:与多头部模块相对应,这个模块包含多个图像重建分支,用于根据不同任务重建高质量的图像。
-
Swin Transformer层(Swin Transformer Layer):在特征增强模块中,Swin Transformer层通过分块操作将输入特征划分为多个小区域,并在每个区域内计算自注意力,以输出增强后的特征。
Swin Transformer结构是特别为了处理图像恢复任务而设计的,它利用了Transformer架构的优势,同时通过引入基于局部性的操作来提高计算效率。
UniFMIR模型的训练和迁移学习过程使用以下步骤:
-
预训练(Pretraining):UniFMIR首先在大规模的荧光显微镜图像数据集上进行预训练。这个数据集包含了14个公共数据集,大约30GB的数据,涵盖了多种成像模式、生物样本和图像恢复任务。
-
微调(Fine-tuning):预训练完成后,模型在特定的子数据集上进行微调,以适应不同的退化条件、成像模式和生物样本。微调是在预训练模型的基础上,针对特定任务调整模型参数的过程。
-
样本数量:UniFMIR模型使用了196,418对训练样本进行预训练,这些样本来自不同的荧光显微镜成像任务和成像模态。
-
数据块(Patch Size):在训练过程中,为了适应深度神经网络中固定大小的特征空间,原始图像被裁剪成多个具有相同空间尺寸的数据块。预训练阶段的批量大小(batch size)设置为1,数据块大小(patch size)设置为64×64像素。微调阶段,根据不同任务的需要,批量大小和数据块大小会有所调整。
-
损失函数:预训练阶段使用了ℒ1和ℒ2损失函数的组合,以利用ℒ1损失的鲁棒性和ℒ2损失的稳定性。微调阶段则使用了ℒ1损失函数,以追求更高的定量指标,如峰值信噪比(PSNR)。
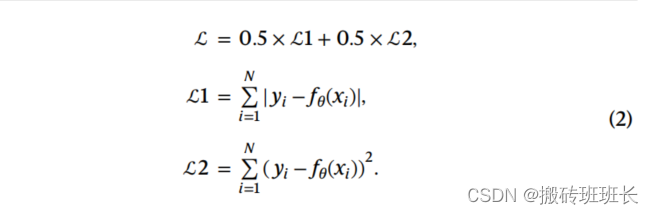
-
训练细节:UniFMIR模型基于PyTorch实现,并使用自适应矩估计(Adam)优化器进行训练,初始学习率设置为5×10^-5,并在训练200个周期后减半。所有实验在配备Nvidia GeForce RTX 3090 GPU的机器上进行。
-
评估指标:使用峰值信噪比(PSNR)、结构相似性指数(SSIM)、归一化均方根误差(NRMSE)等指标来评估图像恢复的质量。
-
模型优化:为了提高效率和减少计算资源消耗,研究者还对模型进行了剪枝和量化,以减少模型的大小和计算需求。
通过这种预训练和微调的方法,UniFMIR能够学习到从低质量图像到高质量图像的转换知识,并在不同的图像恢复任务上展示出强大的泛化能力。















 1422
1422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









