







稀疏编码介绍
稀疏编码算法是一种无监督学习方法,它用来寻找一组“超完备”基向量来更高效地表示样本数据。稀疏编码算法的目的就是找到一组基向量
ϕi
,使得我们能将输入向量 x 表示为这些基向量的线性组合:
x=∑i=1kaiϕi
不同于PCA,sparse coding目的是寻找一组“超完备”基向量而非“完备”基向量。也就是说sparse coding中k要大于n。
含了限制条件的稀疏编码代价函数的完整形式如下(参考UFLDL):
minimizea(j)i,ϕisubject to∑j=1m∣∣∣∣∣∣∣∣x(j)−∑i=1ka(j)iϕi∣∣∣∣∣∣∣∣2+λ∑i=1kS(a(j)i)||ϕi||2≤C,∀i=1,...,k
学习算法
使用稀疏编码算法学习基向量集的方法,是由两个独立的优化过程组合起来的。第一个是逐个使用训练样本 x 来优化系数 ai ,第二个是一次性处理多个样本对基向量
ϕ
进行优化。
可以使用 L1 范式 :
S(ai)=|ai|1
或L2 范式作为稀疏惩罚函数。(具体参考UFLDL)
根据前面的的描述,稀疏编码是有一个明显的局限性的,这就是即使已经学习得到一组基向量,如果为了对新的数据样本进行“编码”,我们必须再次执行优化过程来得到所需的系数。这个显著的“实时”消耗意味着,即使是在测试中,实现稀疏编码也需要高昂的计算成本,尤其是与典型的前馈结构算法相比。
目标函数
J(A,s)=∥As−x∥22+λs2+ϵ−−−−−√+γ∥A∥22
s2+ϵ−−−−−√是∑ks2k+ϵ−−−−−√
的简写。在给定 A 的情况下,最小化 J(A,s) 求解 s 是凸的。同理,给定 s 最小化 J(A,s) 求解 A 也是凸的。这表明,可以通过交替固定 s和 A 分别求解 A和s。其中包括weight decay还有smoothing parameter(sparsity parameter)。
该目标函数可以通过以下过程迭代优化(注意一种矩阵微积分的求法):
- 随机初始化A
- 重复以下步骤直至收敛:
根据上一步给定的A,求解能够最小化J(A,s)的s
根据上一步得到的s,,求解能够最小化J(A,s)的A
梯度下降方法求解目标函数也略需技巧,另外使用矩阵演算或反向传播算法则有助于解决此类问题
拓扑稀疏编码
我们拓扑希望稀疏编码能学习得到一组有某种“秩序”的特征集。
J(A,s)=∥As−x∥22+λ∑VssT+ϵ−−−−−−−√+γ∥A∥22
稀疏编码实践(技巧)
两种更快更优化的收敛技巧:
- 将样本分批为“迷你块”
- 良好的s初始值:令
s←WTx(x是迷你块中patches的矩阵表示)。或者
s中的每个特征(s的每一列),除以其在A中对应基向量的范数。即,如果sr,c表示第c个样本的第r个特征,则Ac表示A中的第c个基向量,则令sr,c←sr,c∥Ac∥.
稀疏编码算法修改如下:
- 随机初始化A。
- 重复以下步骤直至收敛:
随机选取一个有2000个patches的迷你块
如上所述,初始化s
根据上一步给定的A,求解能够最小化J(A,s)的s
根据上一步得到的s,求解能够最小化J(A,s)的A
作业题
该作业需要我们自己对costfunction求导:
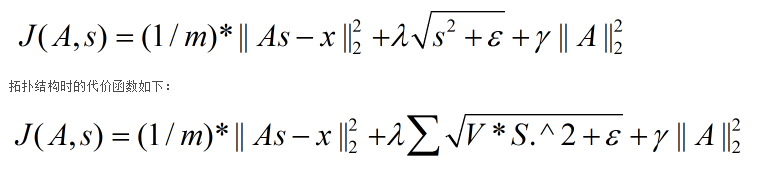
















 9481
9481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









