







最近看了余凯的CVPR12 Tutorial on Deep Learning(下载),在此记录下自己的一些学习心得。
——特征提取
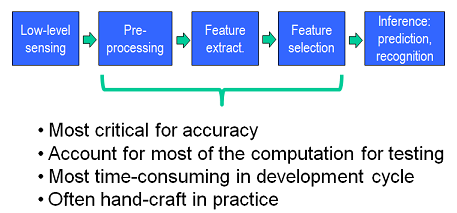
特征提取是目标识别的基础,直接关系到最终识别结果的好坏。在现阶段,特征提取一般采用人工设计好的算法,SIFT/HOG/LBP等,这些特征在特定类型的图像中能够达到较好的识别效果,基本能够满足现实需求。但这些算法提取的只是一些low-level特征,无法获得图像的high-level特征。能不能通过特征学习的方法,让机器自动学习特征,取代手工设计的特征,是近年来Machine Learning的研究热点。Sparse Coding无疑为解决Feature Learing提供了很好的思路。
——Feature Learing Framework
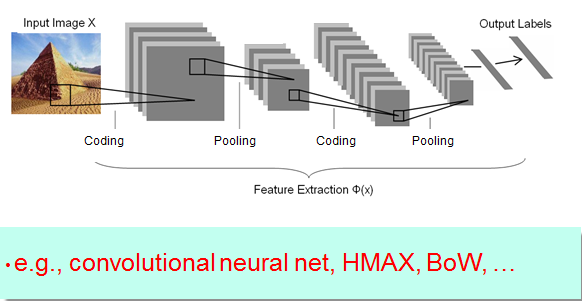
coding:特征编码过程,用非线性映射将图像数据映射到另一个特征空间,以更好的表达原始图像的内容,常用的coding方法有Spase Coding,RBMs,auto-encoders等。
pooling:特征加工过程,对提取的特征进行二次加工,使提取的特征能够更好的用于后续的分类过程。
output labels:可以运用各种Machine Learing算法(如SVM/CNN/Adaboost)进行分类。
——Sparse Coding
Sparsecoding 最早被提出的时候是为了模拟人的大脑,研究人脑对视觉信息的处理过程。
算法包括以下两个步骤:
Training:given a set of random patches x, learning a dictionary of bases [Φ1, Φ2, …]

Coding:for data vector x, solve LASSO to find the sparse coefficient vector a
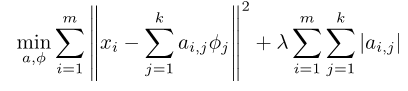

——Sparse Coding VS RBM & autoencoders
(关于RBM & autoencoders 的内容可以参考链接)
1)Sparse Coding:
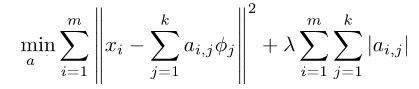
——系数a是稀疏的;
——a的维数一般比x的维数大(X=BS,X:n*m B:n*k S:k*m,B是over-complete的,即k>n);
——编码过程a=f(x)是一个关于x的非线性的隐函数(这是一个LASSO问题,我们无法得到f(x)的显示表达式);
——重建过程x'=g(a)是一个线性的显示的关于a的函数(X’=ΣaiΦi)。

2)RBM& autoencoders
——有显式的f(x);
——不需要限制a是稀疏的,但如果我们要求a是稀疏的(如稀疏自编码,稀疏RBM),通常能得到更好的效果(sparse helps learning)。
——Sparse activations vs. sparse models
sparse model:f(x)的参数是稀疏的
sparse activations:f(x)的输出是稀疏的
下面举例说明:
sparsemodels: f(x)=<w,x>(点积), 其中 w=[0, 0.2, 0, 0.1, 0, 0]

sparseactivations (sparse coding) :
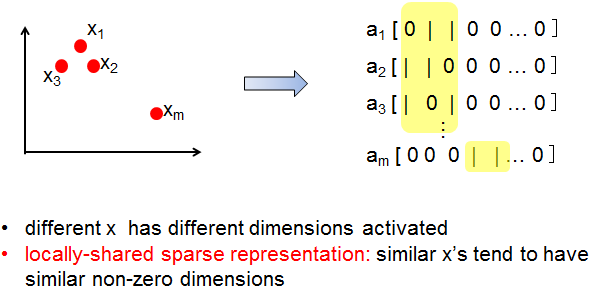
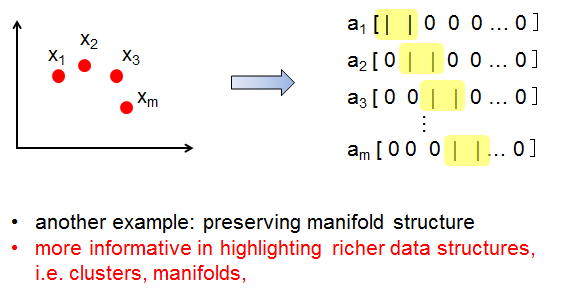
——Sparsity vs. Locality
从直观上来讲,相似的数据应该有相似的特征,不相似的数据的特征应该也不相似。而Local sparse coding要求data in the same neighborhood 有相似的feature,data in different neighborhoods 有不同的features 。
spasity和locality的关系简单总结如下:
sparsity不一定导致locality,而locality肯定是sparse的。sparse不比locality好,因为locality具有smooth的特性(即相邻的x编码后的f(x)也是相邻的),而仅仅sparse不能保证smooth。smooth的特性对classification会具有更好的效果,并且设计f(x)时,应尽量保证相似的x在它们的编码中有相似的非0的维度。
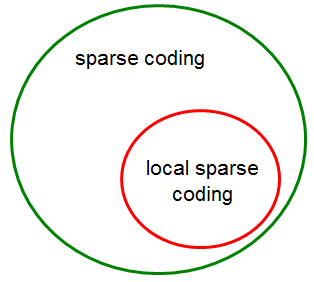
Classical sparse coding 一般而言都是local的
1)Whenit works best for classification, the codes are often found local
2)It’s preferred to let similar data have similar non-zero dimensions in their codes.
但是有些时候,sparse coding并不是local的,如
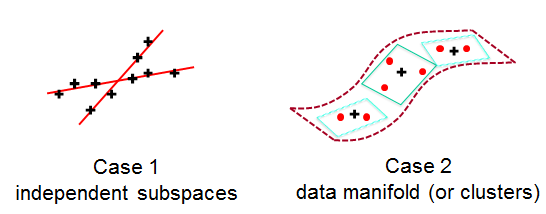
Case 1:
1)Eachbasis is a “direction”
2)Sparsity:each datum is a linear combination of only several bases.
Case 2:
1)Eachbasisan “anchor point”(参考点/基点,用来表示其他数据点)
2)Sparsity:each datum(黑色十字) is alinear combination of neighbor anchors(红色点)
3)Sparsityis caused by locality
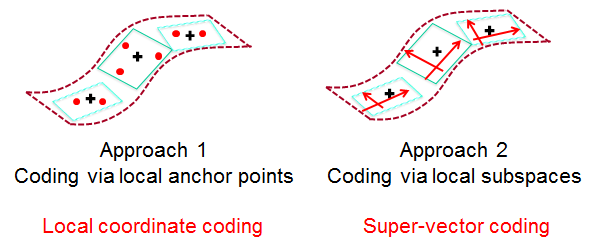
一个好的编码算法应该满足:
- havea small coding error
- and also be sufficiently local
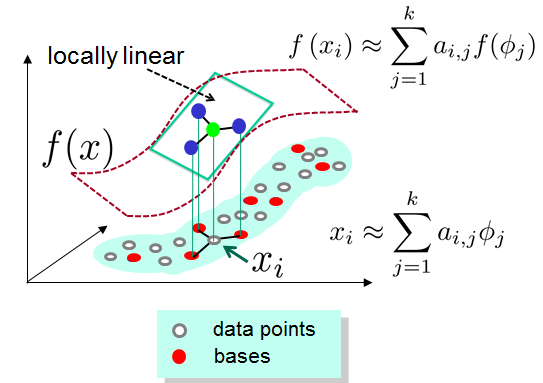
LCC学习过程:

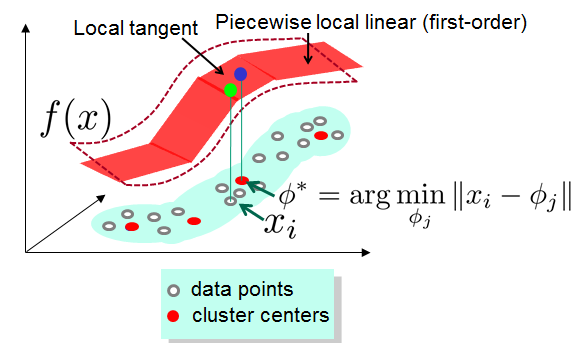
已知字典C(每个word为d维),对于d维空间的的任意x都可以用下式估计:
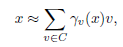
其中v是字典中的word,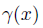
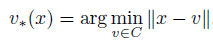
其中
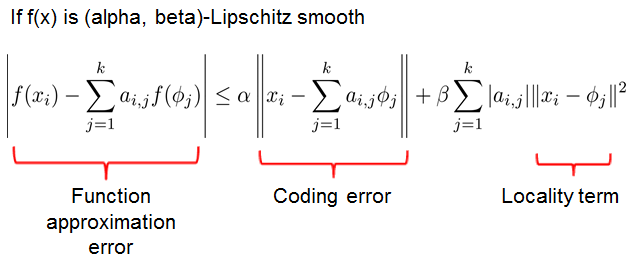
如果f(x) 是beta-Lipschitz smooth,那么
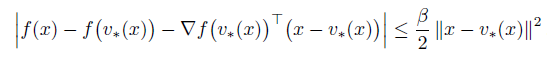
因此,f(x) can be expressed as a linear function on a nonlinear coding scheme
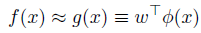
其中,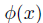
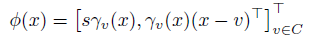
s是非负常数,由于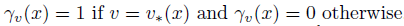
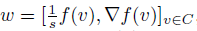
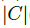
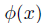
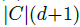
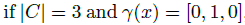
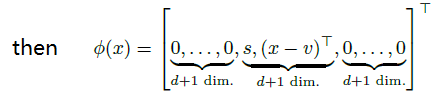
SVC学习过程

最后推荐一篇博文:http://blog.csdn.net/jwh_bupt/article/details/9837555 ScSPM和LLC总结















 4481
4481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









