







接着上一篇的内容:
四:Transfer Learning:

1.对于数据量少或者中等的情况,迁移学习很有用
2.基于ImageNet的实验,将ImageNet的所有类的各分一半为A,B:
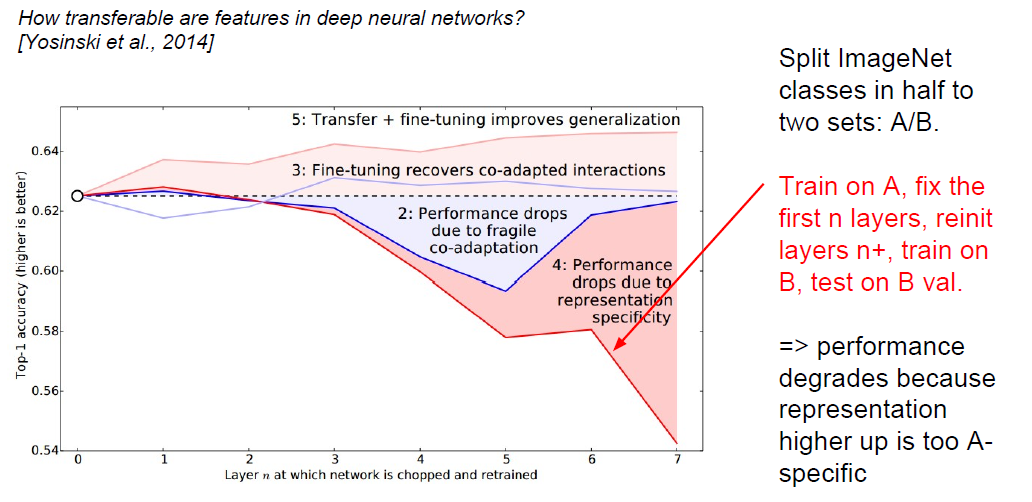
(1).先训练A部分,然后将前n层的参数保存好;再重新初始化后n+层的参数,用B部分训练;再将前面保存好的参数,和后面训练B部分得到的参数结合,在B的验证集上进行验证:
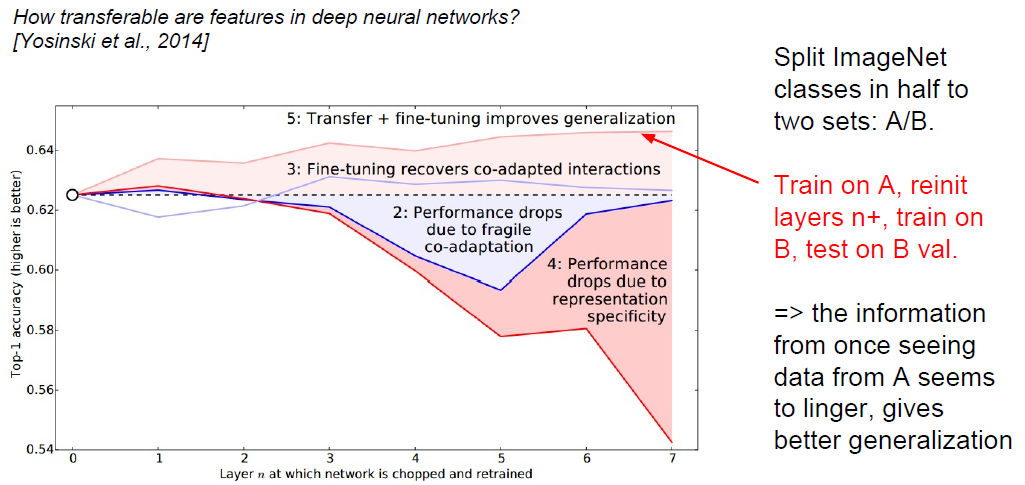
(2).先训练A部分,训练完A后重新初始化n+层后面的参数,再在B上进行训练,最后在B的验证集上验证:
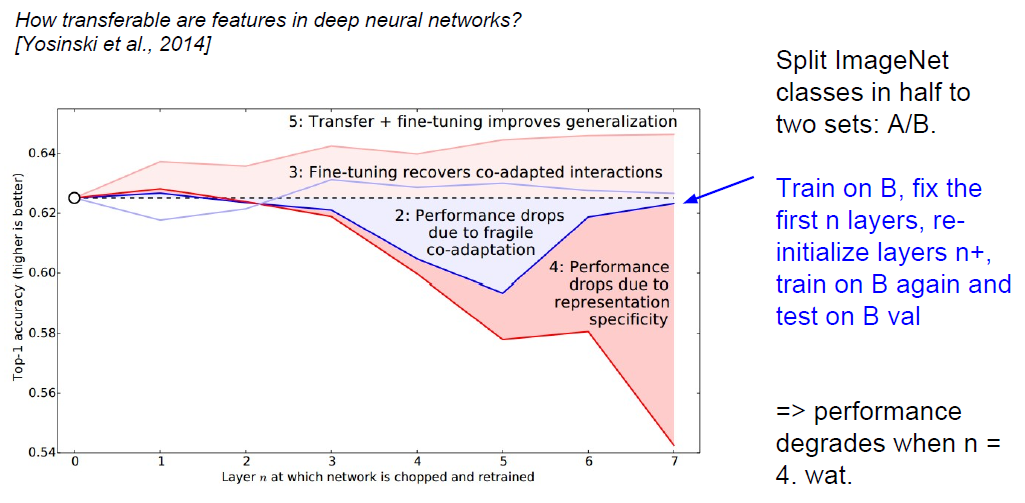
(3).先训练B部分,固定并保存前n层的参数;再重新初始化后n+层的参数,再次在B上进行训练;最后将前面保存好的前n层参数,与重新训练B的后n+层参数结合,在B的验证集上验证:
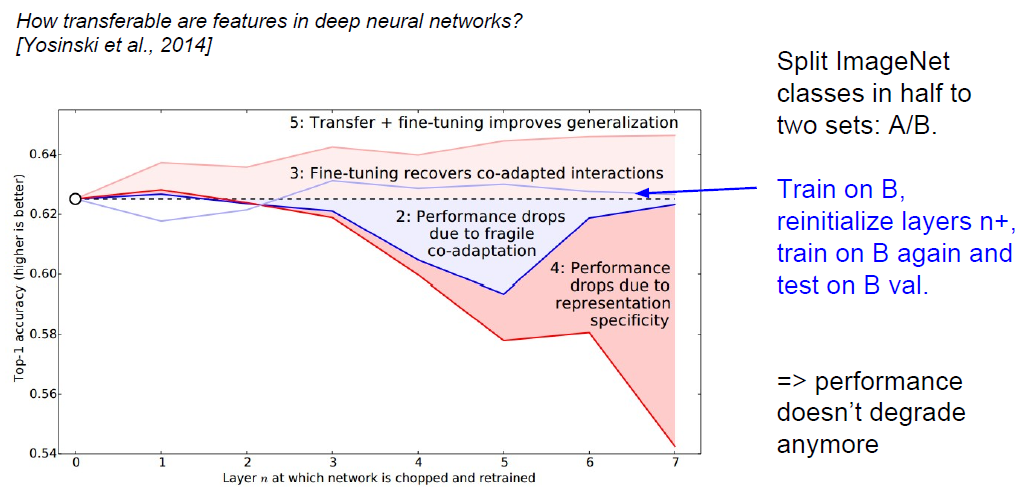
(4).先训练B部分,再重新初始化后n+层的参数;再次在B上重新训练;最后在B的验证集上验证:
3.总结一下上面的实验结果:
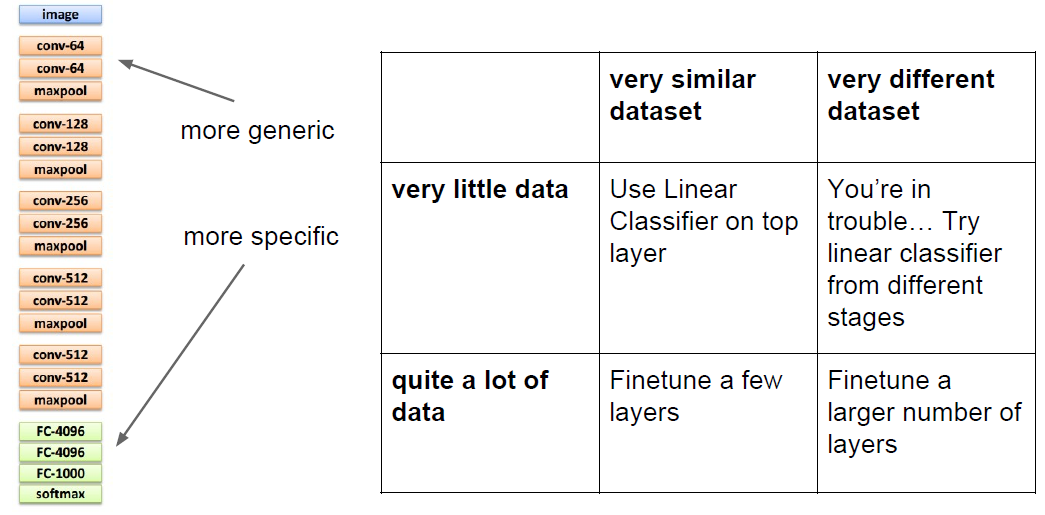
4.下面应该是李飞飞老师TED演讲内容的原理:
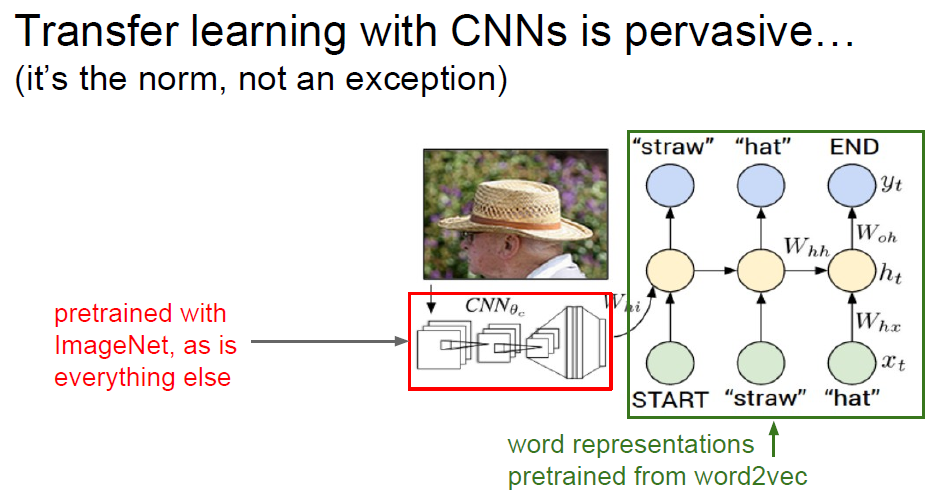
5.处理小数据集的一些建议:

五:Squeezing out the last few percent
1.使用小size的filter比使用大size的filter的效果要好得多,小size的filter能够增加non-linearities数,并且能减少需要训练的参数(试想一个7*7的patch,用一个7*7的filter卷积,和用三层的3*3的filter卷积,得到的结果都是一个scalar)—more non-linearities and deeper gives better results:

2.也可以试试在pool上下功夫:

3.Data Augmentation:
数据集不够的话,也可以试试用下面的几种方式扩大你的数据集:
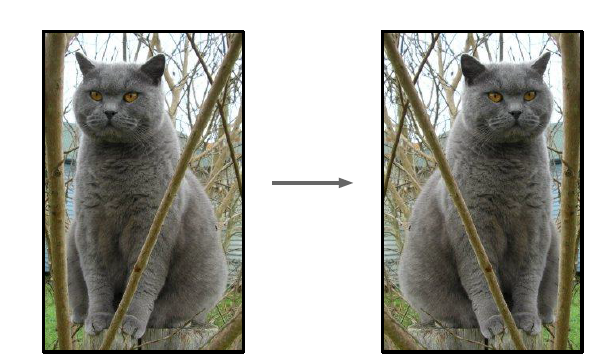
(1)Flip horizontally:可以通过旋转图片来扩大数据集,如果原图像是正方形的话则更好:
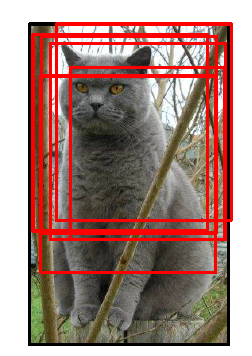
(2)多尺度切割:多尺度切割不仅能增大数据集,还能提高实现效果,一幅图切割150次都很常见:
(3)各种随机组合:

(4)Color jittering:

接着上一讲的内容















 7286
7286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









