 Ubuntu下Darknet+YoloV3实战
Ubuntu下Darknet+YoloV3实战








ubantu下darknet的yolov3运行以及训练
ubuntu18.04环境下的darknet+yolov3
参考链接
环境
ubuntu18.04
cuda:10.0.120
cudnn:7.6.5.32
opencv:3.2.0
darknet的安装及测试
1、下载代码
git clone https://github.com/pjreddie/darknet.git
cd darknet
make
2、下载权重
下载权重,保存在darknet的目录下
wget https://pjreddie.com/media/files/yolov3.weights
3、测试
在darknet目录下打开终端,输入:
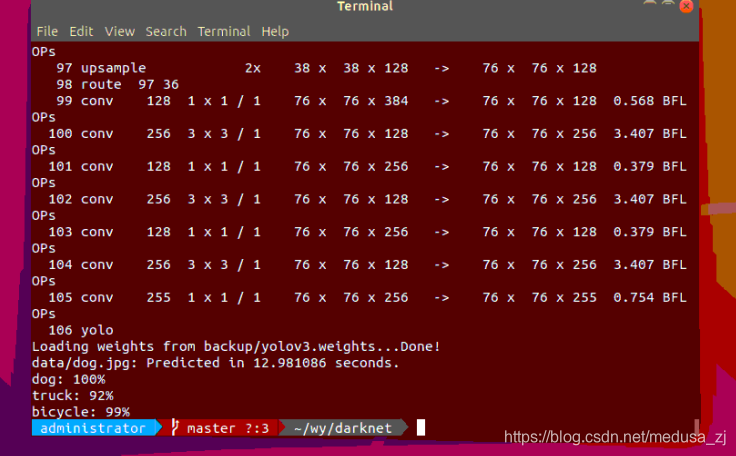
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
结果如下:
附
下面是对darknet目录下的Makefile文件进行的一些修改,每次修改完都需要重新编译。
(1)如需使用gpu运算,修改如下,然后保存。
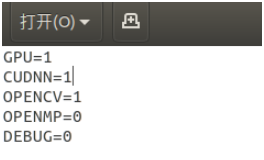
修改完后一定要重新编译,在darknet目录下打开终端,输入:
make clean
make -j8
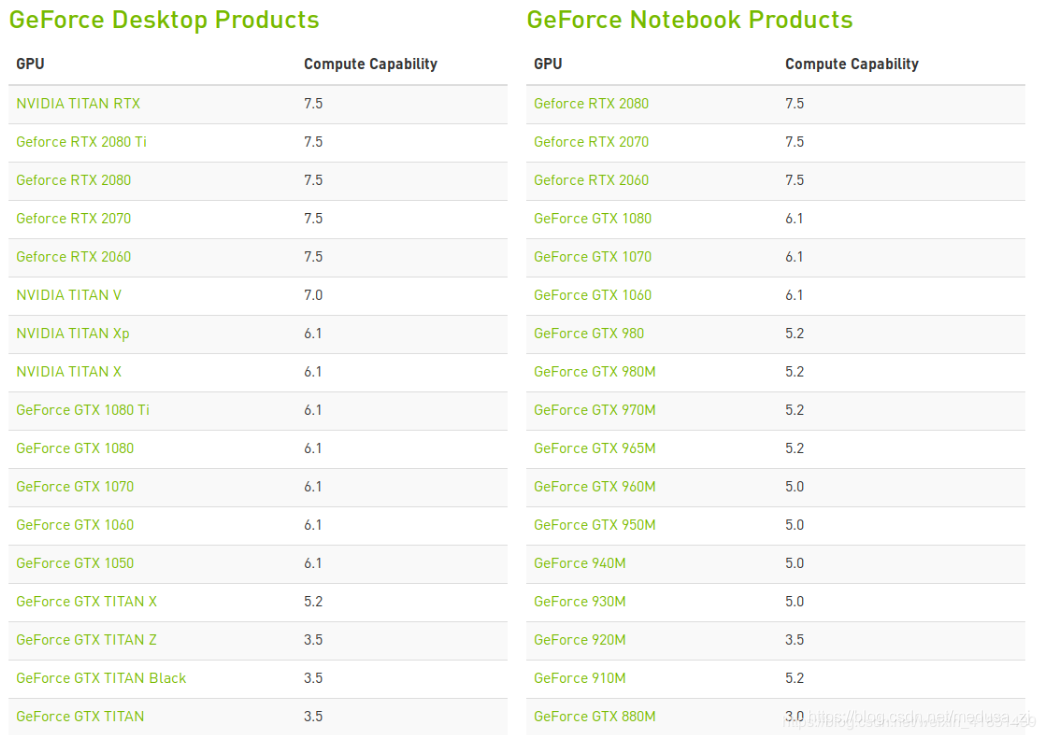
(2)根据自己电脑的硬件可在Makefile中对ARCH进行修改。例如显卡是GTX1060,算力为6.1(具体算力nvidia官网可查)。
https://developer.nvidia.com/cuda-gpus
修改如下:

显卡算力:
(3)在Makefile文件的第46行,修改为cuda的安装路径。

测试自己数据集
一、数据集标注
标记数据的可以从这里下载,提取码:m3dt。注意该工具的路径要没有中文,否则闪退。
1、打开标记工具
如图:
红色方框处选择yolo,而非默认的PascalVOC(我们在标注的时候就让每张图片生成的是txt文件,而不是xml文件,这样就省去了xml转txt这个步骤)如下图:
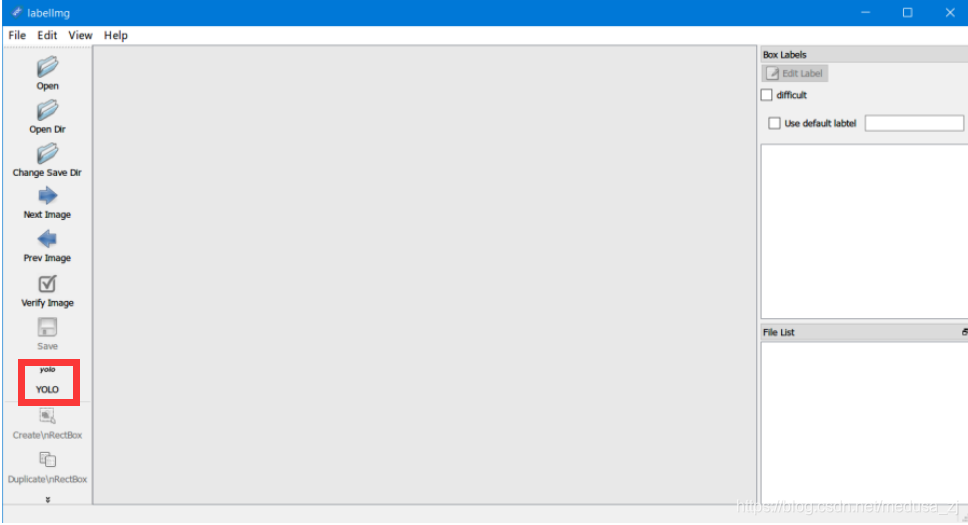
2、标注过程
点击界面上的 Open Dir,打开图片存放文件夹,图片将显示在界面中:

在图片上点击鼠标右键,选择“Create RectBox”,之后从左上至右下拖动鼠标画出一方框,标出待识别物体(快捷键:W)。
松开鼠标后,会弹出一个对话框,此时选择框出物体所属的类别,之后点击 OK。
确认右侧出现标注内容后点击 save 保存标注信息(快捷键:Ctrl+S)。
点击 Next Image,重复上述过程直至每张图片都完成标注(快捷键:D)。
3、标注后的文件
标注过后,就会生成对应的图片名的txt文件,以及一个所有类别的文件。
其中对于每个标注后生成的txt文件,其格式是如下所示(网上存):

二、VOC2019数据集的制作
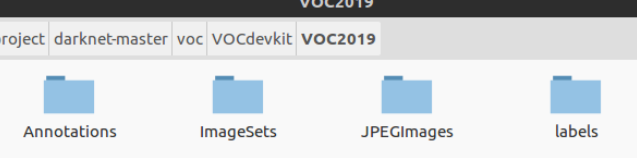
1、建立文件夹
在darnet-master下建立voc/VOCdevkit/VOC2019层次目录,然后在VOC2019目录下建立三个文件夹:Annotations、ImageSets、JPEGImages。
其中:
Annotations 存放使用labelImg软件标注所有数据集图片时生成的txt标注文件,labels存放Annotations中相同的内容;(第一步已有)
ImageSets用来存放训练和测试数据的名称,其里面存放的是Main文件夹,Main文件夹中存放的是4个txt文件,分别是存训练集图片名的train.txt、存验证集图片名的val.txt、存测试集图片名的test.txt、存测试和验证集图片名的trainval.txt;(需要生成)
JPEGImages用于存放数据集中的图片,后期还要将labels中的txt全部放到其中。
2、生成ImageSets中的txt
我们需要ImageSets/Main目录下的train.txt和val.txt,代码make_train_val.py如下:
import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder='/*****(自己的路径)/darknet-master/voc/VOCdevkit/VOC2019/JPEGImages/'#地址是所有图片的保存地点
dest='/*****(自己的路径)/darknet-master/voc/VOCdevkit/VOC2019/ImageSets/Main/train.txt' #保存train.txt的地址,对于train.txt(在ImageSets/Main/下)和2019_train.txt(在VOCdevkit下)是不同的路径
dest2='/*****(自己的路径)/darknet-master/voc/VOCdevkit/VOC2019/ImageSets/Main/val.txt' #保存val.txt的地址,对于val.txt(在ImageSets/Main/下)和2019_val.txt(在VOCdevkit下)是不同的路径
file_list=os.listdir(source_folder) #赋值图片所在文件夹的文件列表
train_file=open(dest,'a') #打开文件
val_file=open(dest2,'a') #打开文件
for file_obj in file_list: #访问文件列表中的每一个文件
file_path=os.path.join(source_folder,file_obj)
#file_path保存每一个文件的完整路径
file_name,file_extend=os.path.splitext(file_obj)
#file_name 保存文件的名字,file_extend保存文件扩展名
file_num=int(file_name)
if(file_num<620): #保留620个文件用于训练
train_file.write(file_name+'\n') #用于训练前620个的图片路径保存在train.txt里面,结尾加回车换行/////////生成train.txt是file_name;生成2019_train.txt是file_path
else :
val_file.write(file_name+'\n') #其余的文件保存在val.txt里面/////////生成val.txt是file_name;生成2019_val.txt是file_path
train_file.close()#关闭文件
val_file.close()
生成的train.txt文件和val.txt文件是图片名字
3、生成VOCdevkit同级目录下的txt
生成代码make_2019_train_val.py如下:
import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder='/*****(自己的路径)/darknet-master/voc/VOCdevkit/VOC2019/JPEGImages/'#地址是所有图片的保存地点
dest='/*****(自己的路径)/darknet-master/voc/2019_train.txt' #保存train.txt的地址,对于train.txt(在ImageSets/Main/下)和2019_train.txt(在VOCdevkit下)是不同的路径
dest2='/*****(自己的路径)/darknet-master/voc/2019_val.txt' #保存val.txt的地址,对于val.txt(在ImageSets/Main/下)和2019_val.txt(在VOCdevkit下)是不同的路径
file_list=os.listdir(source_folder) #赋值图片所在文件夹的文件列表
train_fil 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1796
1796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









