







论文题目–《对图神经网络的注意力和泛化能力的理解》
摘要
我们旨在更好地了解图神经网络(GNN)中节点的注意力机制,并确定影响其有效性的因素。我们特别关注attention GNNs推广到更大、更复杂或有噪声的图的能力。受图同构网络研究的启发,我们设计了简单的图推理任务,使我们能够在受控环境中研究注意力机制。我们发现,在典型条件下,注意力的影响可忽略不计甚至是有害的,但是在某些条件下,注意力在我们的某些分类任务中的表现获得了超过60%的出色提升。在实践中满足这些条件是具有挑战性的,并且通常需要最优的初始化或有监督的注意力训练。我们提出了一种替代方法,并以弱监督的方式训练attention,以接近监督模型的性能,并且与无监督模型相比,改进了在多个合成数据集和真实数据集上的结果。
1.图神经网络中的注意力于池化操作
注意力机制再、在深度学习里面占有重要的地位,在图神经网络里面注意力机制存在于边上,和节点上。在本文中,我们主要关注的是基于节点上的注意力机制。现在,我们首先应该建立注意力和池化之间的一个联系。在卷积里面定义的池化操作一般是基于一个规则的网格内,在一个区域里面取出一个值(平均,加权平均,最大值,随机等)。然后注意力机制在CNN里面一般用以下公式表达:

其中X是输入,α是注意力系数,Z是注意力机制之后的输出。
在图神经网络之中,池化的方法和CNN里面类似,但是池化的区域是一系列点的集合。也就是聚合邻居节点的信息。
根据公式1,我们很容易的推导出在GNN里面的注意力机制:

其中P是这个池化区域节点的数量。有:
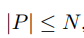
空集表示该数据在注意力机制的过程之中被选择遗弃。
在公式二之中,输出节点的数量会比输入少,然后呢在形式上存在这样一个比率:
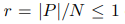
作者利用以上的方法将池化操作和注意力机制相结合利用到GNN里面。基于注意力得池化操作让我们的预测更加有说服力,以前的网络都是仅仅根据池化节点做出预测。
受到最近提出的新的图同构网络(GIN),作者设计出了2个简单的实验一个是颜色实验,一个是三角形实验。GIN是最近提出的一种强大的图神经网络。作者也在MNIST数据集上面做了相应的实验。
2.模型

作者主要用的是新提出的GIN。GIN的主要思想是利用一个新定义的聚合器去替代以前GCN里面的平均聚合器,然后在聚合了邻居节点的特征之后,再添加更多的全连接层。这样得到的模型比之前的模型能够区分范围更广的图形结构。
2.1注意力阈值
之前说过池化节点的范围是有一个比率r。但是由于图的大小不同,池化的节点数就或多或少。所以,作者提出了一个阈值α。
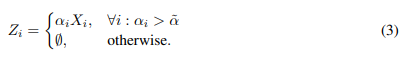
在选着池化的邻居节点的时候,作者们通过观察每个节点的α值,来判定对该节点的取舍。
2.2注意力子网
为了训练注意力模型去预测节点的注意力系数,作者用了2种方法。
1.线性的投影,训练映射函数:
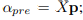
2.训练一个单独的GNN
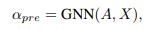
2.3ChebyGIN
ChebyNET就是图卷积的谱域方法,作者结合了GIN和 ChebyNet,提出了一个更强的模型, ChebyGIN。为了增强ChebyGIN的聚合效果,作者将节点的度和节点的特征相乘,以增强特征的重要性。而且作者也在聚合特征之后添加了更多的全连接层。
3.实验
作者在实验中介绍了颜色计数实验和三角形计数实验,而且也在MNIST数据集上做了实验。在实验的最开始初始定义一个α系数,然后通过训练调整α至最好,得到最好的注意力系数之后,该注意力模型就训练完成了。
3.1数据集
颜色实验:为每个节点分配一个独热编码:【1,0,0】红色,【0,1,0】绿色,【0,0,1】蓝色。然后任务的目的就是计数出绿色节点的个数。然后初始α系数的值为:
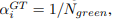
因为训练过程是有监督的所以我们可以知道绿色节点的个数,计算出初始α的值。
三角形实验:该任务的目的是计数该图里面包括多少个三角形。其中α系数的值用以下公式计算:
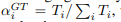
其中T是值节点i包括的三角形的个数。
MNIST数据集。该任务的目的是识别出图片代表的数字是多少,其中图片为0-9的数字。具体方法是先用SLIC算法生成超像素快,然后构建图。每个节点对应一个超像素块。然后α系数的初始值的计算公式为:
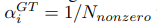
其中N代表所有超像素块的数量。
如图:

3.2泛化到更大更复杂的图结构
为了验证注意力机制的健壮性,作者将颜色实验和三角形实验引入到更大的网络之中。如图:

在颜色实验中添加了另外一个通道变成4个通道【c1,c2,c3,c3】,然后其中【0,1,0,0】的时候代表绿色,其他的时候【c1,0,c2,c3】其中c1,c2,c3,可以使0-1之间的数值,代表红色,蓝色,透明色的三种颜色的混合。
在三角形计数实验中,也引入了更多的节点数。
在MNIST数据集的实验中,加入了高斯噪音,是的模型的识别度更高。
在三种实验的拓展中,都取得了不错的效果。
3.3网络结构的训练
损失函数:
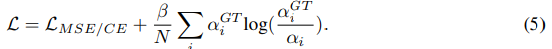
其中前一部分代表回归损失和交叉滴损失,后面一部分用来计算注意力系数的损失。
注意力得正确性:
为了评估注意力系数的正确性,遵循CNN的方式,我们在训练完一个模型之后呢,移除这个节点,再计算预测一个标签,计算与原始标签的差异,这样来计算出一个评估的α系数:
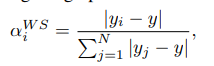
通过以上的一个启发,作者由此想到了一个弱监督的训练方式。
3.4弱监督训练模型
训练过程可以描述为,如果想训练一个模型A,那么我们需要去训练一个和A具有相同结构的模型B,然后用上面公式6,来计算B的评估注意力系数α,有了这个评估注意力系数之后,对于A就不需要初始系数阿尔法了,用这个评估系数α进行替代,然后,用于训练模型A。
4.实验结果

5.结论
证明了注意力对于图神经网络是非常强大的,但是由于初始注意力系数的敏感性,要达到最优是很困难的。特别是在无监督的环境中,由于不能确定初始注意力系数的值,使得这样的训练更加困难。我们还表明,注意力可以使GNN对更大,更嘈杂的图形有更强的能力。同时本文提出的弱监督模型和有监督模型具有相似的优势性。















 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









