







2019-NeurIPS-Understanding Attention and Generalization in Graph Neural Networks

Paper: https://arxiv.org/abs/1905.02850
Code: https://github.com/bknyaz/graph_attention_pool
Video:
Blog:
理解图神经网络中的注意和泛化
作者受图同构网络工作的启发,我们设计了简单的图推理任务,使我们能够在受控环境中研究注意力。我们发现,在典型条件下,注意力的影响可以忽略不计甚至有害,但在某些条件下,它在我们的一些分类任务中提供了超过 60% 的性能提升。在实践中满足这些条件具有挑战性,通常需要优化初始化或注意力的监督训练。我们提出了一种替代方案,并以一种接近监督模型性能的弱监督方式训练注意力,并且与无监督模型相比,改进了几个合成数据集和真实数据集的结果。
在GNN中,池化方法通常遵循与cnn相同的模式,但池化区域通常是基于聚类找到的,因为没有网格可以在数据集中的所有示例中以相同的方式均匀划分为区域。
最近,top-k池化被提出,与其他方法不同:它只传播输入的一部分,而不是对“相似”节点进行聚类,并且这部分不是从输入中均匀采样。
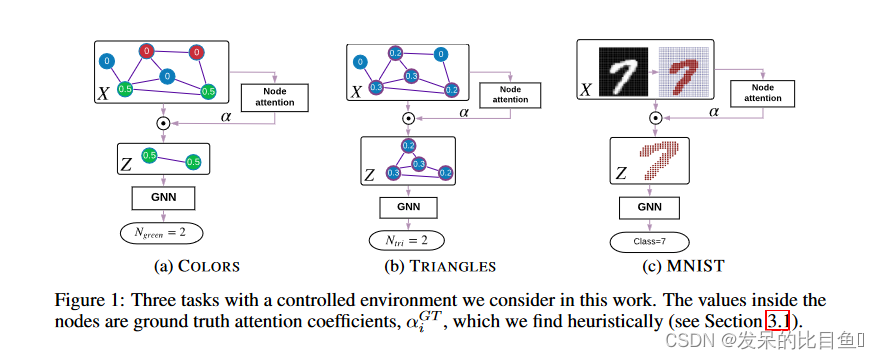
作者研究了GNN的两个变体:图卷积网络(GCN)和图同构网络(GIN)。
GIN的主要思想之一是用SUM聚合器替换节点上的MEAN聚合器,例如GCN中的一个,并在聚合相邻节点特征之后添加更多完全连接的层。与之前的模型相比,生成的模型可以区分更广泛的图形结构。
在一些实验中,发现GCN和GIN的性能都很差,因此,注意力子网络也很难学习。通过将GIN与ChebyNet结合,作者提出了一个更强的模型ChebyGIN。
ChebyNet是GCN的多尺度扩展,因此对于第一尺度,K=1,节点特征本身就是节点特征,对于K=2,在一跳邻居上对特征进行平均,对于K=3,在两跳邻居上,以此类推。为了在ChebyGIN中实现SUM聚合器。

实验
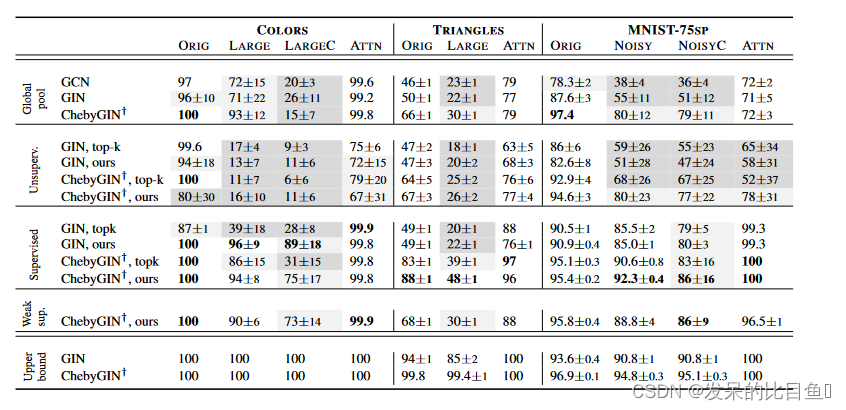
根据表 1 中的结果,需要对注意力进行监督以揭示其力量。弱监督方法与数据集和模型的选择无关,不需要地面实况注意标签,但可以提高模型的泛化能力。
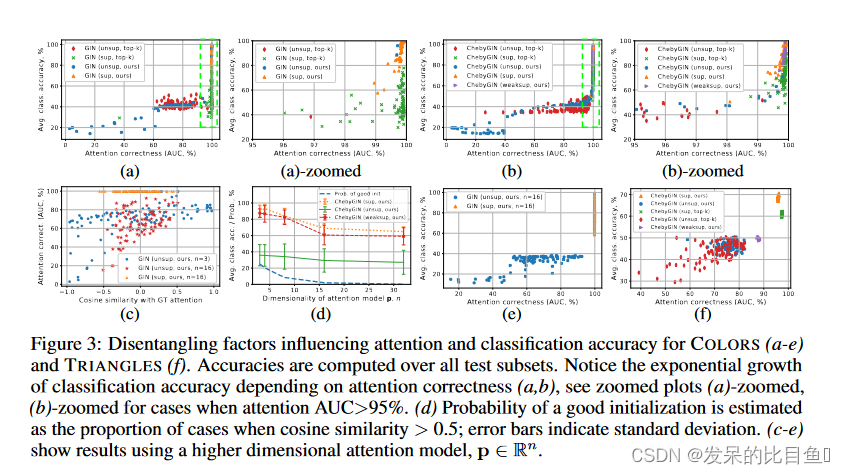
图3表明,具有监督注意力(GIN、sup)的相似模型超过 60%。对于 TRIANGLES-LARGE,这个差距是 18%,对于 MNIST-75SP-NOISY,这个差距超过 12%。如果与上限情况相比,这个差距甚至更大,监督模型可以进一步调整和改进。

图4表明:从未观察到注意力初始化不佳的模型的恢复。
















 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











