







原文:https://arxiv.org/pdf/1710.03958.pdf
代码:http://github.com/feichtenhofer/detect-track
摘要:
本文主要做出了三个贡献,1)提出全卷积网络,借助多任务的单帧检测和帧间回归跟踪同时处理检测和跟踪问题,2)提出表征帧间目标相关性的相关特征帮助跟踪,3)将帧间的轨迹片段关联起来得到高精度的检测结果。最终方法在VID数据集上获得state-of-art的结果,并且整体结构相对简单,同时指出增加步长可以提高跟踪速度
1.引言
最近的视频的检测跟踪方法一般是,首先对单帧进行检测,然后做后处理,通过跟踪将检测的结果沿着时间轴传播。这是“tracking by detection”的变种,这种范式的主体是单帧目标的检测。视频目标检测挑战赛(VID)比图像目标检测挑战赛(DET)的困难之处在以下几个方面。1)数据集规模大,VID有130万张图片,DET有40万张,COCO有10万张。2)运动模糊。3)视频图像质量一般。4)部分遮挡。5)物体不常见的姿势
本文的目标是用一个全卷积网络在多帧之间生成一个轨迹片段,同时进行检测和跟踪。为了完成这个目标,本文扩展了R-FCN,受[1,13,25]的启发,加入了相关用作跟踪。多帧图像,首先进入一个卷积模块比如resnet-101用以提取深度提升,供后面的检测和跟踪任务使用。本文计算相邻帧的卷积特征的相关系数用来估计局部平移量。深度特征最终被送入ROI Pooling得到类型和box,同时送入ROI tracking得到box的变化量(平移、尺度、边比)。最终将轨迹片段关联得到整个视频的检测结果。
本文在VID数据集上的评估结果要优于2016年VID比赛的冠军,同时简单高效,另外需要指出的是,本文提出的跟踪损失,对于静态图像的检测也是有益的,同时增加输入帧的时间步长可以得到D&T更快速的版本。
2. 相关工作
目标跟踪:
基于回归的跟踪器[13]与本文工作比较相关。基于一个孪生网络预测第一张图片中的目标在第二张图片中的位置,他可以适应跟踪模板的尺度和边比的变化。这种方法的缺点在于只能处理单个目标,为了适应尺度和边比的变化需要数据增广,去学习可能的变化。[1]是一个相关跟踪的例子,也是用孪生网络,输入模板图和待搜索图,最终的输出的特征图做相关去预测目标的位置,很多相关滤波的缺点是只能单目标跟踪。
视频检测:
[16,17,18]sensetime的T-CNN系列,[42]msra的光流系列误差主要产生与光流预测的误差和关键帧特征传播的误差。
3. D&T
3.1 总览
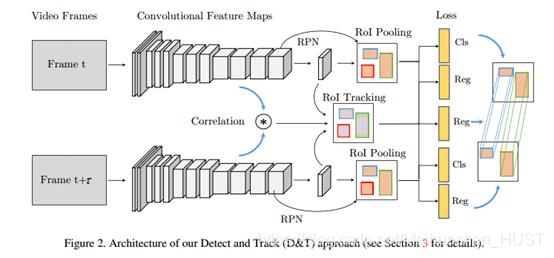
整个网络框架如Figure2所示。首先,给定一个图像对,通过一个特征提取网络(Res-101)提取深度特征供后序任务使用。一个RPN网络根据目标性大小输出候选区域,这些候选区域是对anchor的回归。ROI Pooling从中间的卷积层中生成位置敏感的特征图,用于最终的分类和回归。上述其实是R-FCN的框架,本文对上述框架进行了拓展,将两个PSROI Pooling得到的特征图,连同一个相关特征图,输入ROI tracking层,这个层输出的是框从前帧到后帧的变换。两帧之间的相关性,通过两帧之间PSROI Pooling之间计算得到。ROI tracking的训练,通过帧间的框的坐标回归得到。回归的损失是跟踪预测框与ground truth之间计算soft L1 norm得到。
这样的跟踪框架其实可以看做是[13]的单目标跟踪器的扩展,[13]的问题是必须学习所有的变换,平移尺度等,这需要大量的数据增广。而基于相关的滤波器天然具有好的平移适应性,最近的相关跟踪器也是使用高层的卷积特征[1,25]。相关响应图可以表征模板和搜索区域相似性,这种相似性其实包含了二维的循环移位在里面(循环矩阵相关理论具体可见KCF论文)。与之不同的是,我们不是计算单目标的相关,而是同时计算多目标。
3.2 R-FCN中的检测与跟踪
R-FCN接受图像输入,经过卷积层得到不同尺度的深度特征,这里与原本的R-FCN不同的是,最终输出的特征图的步长为16而不是32,这是将Conv5的卷积步长改为1,同时使用卷积核膨胀扩大了感受野。R-FCN的检测原理不再赘述,
输入两个图像It,It+k,得到两个特征图,将他们concat起来,得到F[t,t+k],对这个concat的特征图使用PSROI Pooling,预测每个ROI从t帧到t+k帧的delta x,delta y,delta h,delta w,这个预测通过回归器实现,回归器的输入还有相关图。
3.3 多任务的检测与跟踪目标函数
扩展了Fast RCNN的目标函数,增加了跟踪项
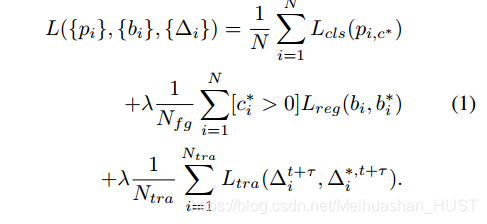
N个ROI,对于每个ROI都计算类别的损失,对于前景ROI,计算位置的损失,对于需要跟踪的ROI,计算跟踪的损失。其中分类为交叉熵损失,回归为smooth L1损失。只有ROI与某个ground truth的IoU大于0.5,才给这个ROI设定为前景,就是Nfg,只有目标两帧都出现的时候,才设定为跟踪目标,就是Ntra。对于跟踪的真值定义如下
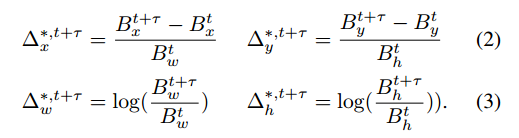
其中t+k和t为分别在两帧中的ground truth的值
3.4 特征相关跟踪
和单目标的模板相关不同的是,本文要跟踪多目标,所以要计算所有位置的相关,然后进行ROI Pooling,最后进行回归。如果考虑全图的偏移量将导致输出的维度过高,所以本文只在局部进行相关计算。类似的做法[5]中估计光流的时候,就有特征图中点的匹配。相关层进行两个特征图的点与点的比较

这里-d<=p<=d,-d<=q<=d,d为预定义的最大平移量,输出的相关图的维度为HW((2d+1)(2d+1))。本文在conv3,conv4,conv5这三层进行相关(conv5的i,j的步长为2,使得在conv3中的相关图也和conv4与conv5中的一致)

上图为上述流程

ab之间有个向左上角的位移,在cde中,中间的小图表示偏移量为0,往上往下往左往右,分别对应不同的偏移量,这时候就发现响应最大点存在的图为左上角的一幅图。fg中鹿出现了模糊、向上移动了,而且前腿动了下,所以在corr conv3的图中上方一幅图腿的位置出现了较大响应。
将两个输入图像的最终的特征图与相关图concat起来,做回归得到跟踪偏移量。
4. 连接轨迹片段形成管道
由于内存限制的原因,不可能输入较长时间的序列。对于t与t+k帧的检测结果Dt,Dt+k还有t对于t+k帧的跟踪结果Tt,t+k,本文定义连接分数来刻画帧间的两个box是否需要连接

其中p为box概率,i,j分别为c类的不同box,最后一项取1的条件是跟踪框T,与两个检测框的IoU都大于0.5
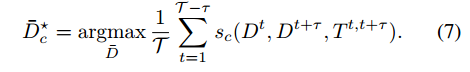
最优的路径可以通过最大化上式得到,最大化的算法为维特比算法(Viterbi)这样就得到一个管道,将这个管道删除,然后继续操作。得到这样一个管道之后,所有的这个管道上的置信度+最大置信度的50%,做一个rescore,这样做的目的是提高正例的置信度,然后对这个管道上的box,附近做nms。
5.实验
5.1 数据集
这里提到了数据集VID还有跟踪的id。从VID DET数据集中使用30类的子集,每一类采样2K张图像,克服样本不平衡。同时,在VID数据集上,每个视频只采样10帧,因为有的视频很长
5.2 训练和测试
RPN:
每个位置选取15个anchor 5个不同的尺度和3个不同的边比。使用NMS其中阈值为0.7,选取300个proposal。本文发现,在全部的DET数据集(200类)上进行预训练可以提高召回率,然后在再30类上进行fine-tune
R-FCN:
在conv5后面使用6倍的膨胀卷积增大感受野,减少步长,使用11的卷积进行类别和位置的预测,其中k=7.batch size =4 l earning rate =10−3 for 60K iterations followed by a learning rate of 10−4 for 20K iterations.testing NMS with IoU threshold = 0.3
D&T:
在训练的时候,从DET里面选一张图片,做了拉普拉斯模糊之后,传入网络,使得网络得到预训练,同时能适应较小的运动。d=8,conv3中的i,j的步长=2,learning rate of 10−4 for 40K iterations and 10−5 for 20K iterations at a batch size of 4. During testing sequence with temporal stride τ, predicting
detections D and tracklets T between them。使用检测输出box作为ROI-tracking 层的输入. 在轨迹片段连接之前,使用文献[8]的nms方法去除每张图检测框的数量,最终使用式7得到连接结果。
5.3 结果
使用D&T比只有D的R-FCN提高了5个点,将backbone从res-101换为inception v4提高3%,添加的ROI tracking使得时间多了14ms,这是可以接受的。轨迹连接由于不能用GPU加速,会使得CPU的耗时增大46ms,这个增加的有点多。














04-10
 4215
4215
4215
11-24
1311
1311
07-11
3438
3438
11-19
1049
1049
08-15
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









