







以下摘录自《深度学习轻松学》冯超
为 了能够尽可能地提高训练速度, DataLayer 采用了异步准备数据的形式,数据
读人的工作和模型训练的工作在各自的线程中进行,相互独立并不依赖 。 当模型
需要数据时,只需要将数据复制到指定的内存中即可。
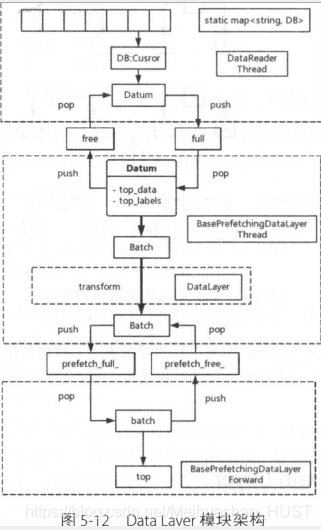
从lmdb数据库中,Cusror逐一获取数据,然后构成batch,经过transform变换后,是实际训练用的data.
最上面的虚线框是DataReader类,负责从DB中读取数据,如果模型配置中设置了多个数据源,那么 Caffe 会为每个数据源创建一个线程分别读取数据,以实现数据的高效独立读取 。如果模型采用多 GPU 的模式训练,那么训练过程中程序中将拥有多个 Solver 类, i卖取数据的线程将同时为这些 Solver 服务,并保持线程间数据的独立 。最终在每一个 Solver 里的 Data Layer 都会有一个自己的 DataReader 对象,它采用生产者一消费者的形式读取线程中准备好的数据。 这其中会有一对关键的线程安全队列 BlockingQueue-free_和 full_:

其中 free 队列中保存着空闲的数据对象 Datum , full 中保存了已经装有数据的对象 。 在 DataReader 的线程中,每一轮迭代将为所有 So lver 从数据库读取数据并存放在队列中:
void DataReader:: Body :: read_one (db :: Cursor* cursor, QueuePair* qp)
{
Datu皿* datum = qp->free_. pop();
datum->ParseFromString (cursor->value ()) ;
qp->full_.push(datum);
cursor->Next() ;
}
Datum作为数据对象,cursor从db中读取数据,加载到datum中,这时候为full;datum再被prefetch取走,这时候为free,依次循环下去。
上面的 DataReader 已经把数据读出来了,而 BasePrefetchingDataLayer 类要做的就
是数据的加工。 这一部分主要完成两件事 。
1.确定数据层最终的输出形式(可以不输出 labe l 的)。
2.完成数据层预处理(调用 Data Transformer 完成一些自 化数据的简单工作,例如
减均值、乘系数)。
BasePrefetchingDataLayer 是 Caffe 中的一个抽象层,它拥有前面提到的 Layer 的一
切属性与功能 。 它的内部有一个线程,也拥有一对阻塞队列模拟生产者一消费者模型 :
BlockingQueue<Batch> prefetch_free_;
BlockingQueue<Batch> prefetch_full_;
其中 prefetch_free一保存已经消费完的数据, prefetch_full_保存准备就绪等待消费
的数据 。 这个线程负责把数据从 DataReader 中读出并进行数据处理,然后将处理好的
数据放入准备队列中:


看上去 BasePrefetchingDataLayer 完成了所有的任务, 那为什么还说它是一个抽象
层呢?实际上在上面的线程代码中,第 2 句调用的 load_batch 在BasePrefetchingDataLayer中是一个虚函数 。 它把这个函数留给子类去实现一一又是一个模板设计模式 的例子 。实现这个虚函数的是我们的正主一一-Data Layer以下是 Data Layer 实现的 load_batch方法 :、
void DataLayer : : load_batch(Batch* batch) {
Datum& datum = (reader_ . full( ). peek()) ;
Dtype top_data = batch->data_ .mutable_cpu_data();
Dtype* top_label = batch->label_ . mutable_cpu_data () ;
for (int item_i d = O; item_id < batch_size ; ++item_id) {
Datum& datum = *(reader_.fullO .pop()) ;
int offset= batch->data_.offset(item_id);
this - >trans formed_data_.set_cpu_data(top_data +offset);
this->data_transformer_->Transform(datum, &(this->transformed_data_));
top_label[item_id] = datu皿 .label();
reader_.free().push(const_cast<Datu皿*>(& datu皿));
}
}
可以看出,在 Data Layer 中,数据从 DataReader 读出,并完成了数据的预处理工
作 。 如果未来我们想对数据进行更多、更复杂的操作,就可以在子类中实现自己的 load
batch 方法控制流程 。
Data Layer 的整体结构到这里就介绍得差不多了 。 通过 3 个类的交互, Caffe 实现
了异步读取数据和处理数据的过程,同时如果需要定制不同的数据结构,只需要在架
构中增加新的数据结构和操纵方法就可以复用整个框架了 。
C++的transformer
proto中有定义
Python中的transformer
Caffe他的 Python 接口同样拥有 DataTransformer 的功能,这部分的形式与 C++很不
一样 。 Python 的接口中实现了一个全新的 Transform,它使用了 Python 中常用的图像
处理库 scikit- image , 它的主要功能如下 。
Resize : 将输入图像数据缩放到指定的长宽比例 。
Transpose : 转换输入数据的维度 。 因为经过 scikit-im age 读入后数据的维度是 Height× Width × Channel ,需要将数据的维度转换到 Channel × Height × Width 。
Channelswap :主要针对彩色图的输入,不同的图像处理库对 channel 的处理顺序有所不同 。 对于 Caffe C++端使用的图像处理库 OpenCV 来说,它的默认装载顺序是
BGR,而 scikit-image 读入的是 RGB ,为了保证和 C++训练的模型一致,这一步也是很必要的 。
Raw scale• Mean• Input scale : 这里是将每个像素乘以一个 Raw scale ,减去一个Mean ,再乘以一个 Input scale。














04-24
 421
421
421
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









