







卡尔曼滤波算法
乘客检测系统使用的DeepSort跟踪算法使用卡尔曼滤波算法进行未来帧状态预测,这个环节对目标跟踪算法非常重要,所以我们先来了解一下卡尔曼滤波算法的原理。
在理想的状态下,物体的运动状态在瞬时是匀速的直线运动,此刻我们在跟踪目标的时候只要计算出物体的中心就能完成目标的跟踪任务,但是在现实当中,跟踪的目标状态时常发生变化,目标遮挡、变速运动、背景干扰都会影响对物体状态的观测,如何能有效的过滤这些变量对目标状态的影响,直接影响到对目标的跟踪效果,卡尔曼滤波算法就能解决这个问题。
卡尔曼滤波本质上是通过观测值和估计值的数据对真实值进行再估计的过程。它是一种线性递归滤波器,主要由两个阶段组成,预测阶段和更新阶段。在预测阶段,算法根据上一时刻t-1物体的运动状态估计此刻t物体的运动状态;在更新阶段,算法对物体的预测状态和当前的观测状态通过协方差来进行加权计算,得到物体此刻真正的运行状态。
卡尔曼滤波的预测方程如下:
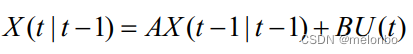
式中,A表示状态转移矩阵,将其定义为使用上一帧的位置通过最优化估计值预测当前帧的位置。在乘客检测系统中X(t-1|t-1)可以认为是上一帧被跟踪的乘客的位置,而X(t|t-1)被定义跟踪目标在当前帧预测的位置。
匈牙利算法
匈牙利算法,是图论中寻找最大匹配的算法。主要用于解决一些与二分图匹配有关的问题。
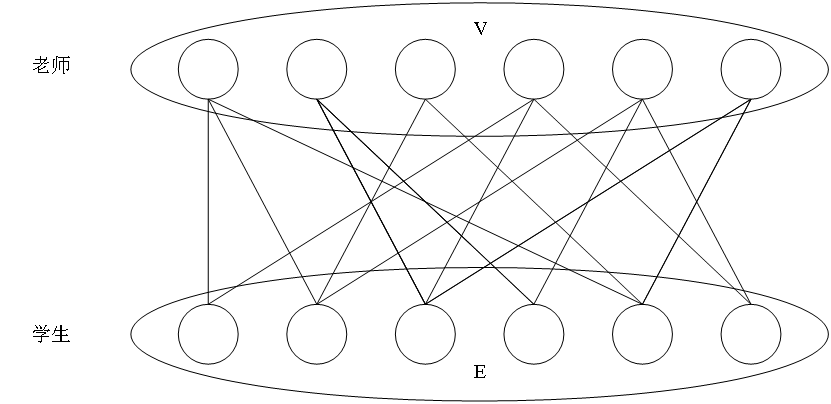
二分图(Bipartite graph)又叫做二部图,是一类特殊的图,它可以被划分为两个部分,每个部分内的点之间互不相连。如下图4所示,设图G=(V,E)是一个无向图,顶点V的集合代表老师,顶点E的集合代表学生,顶点V集合中的元素之间互不相连,顶点E集合中的元素也互不相连,每条线段的两个顶点分别属于V集合和E集合,则图G可以称为一个二分图。
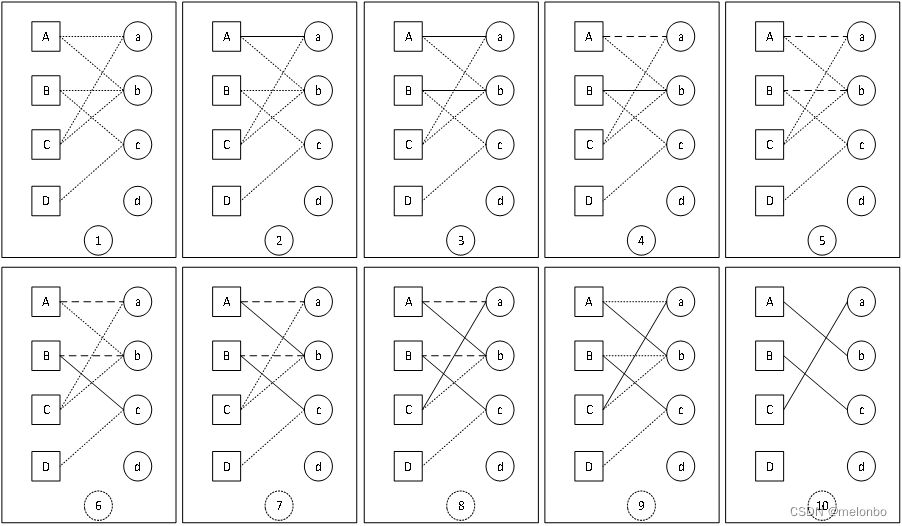
匈牙利算法的主要流程如下图所示:在①中,设左边和右边分别为目标检测结果和跟踪预测目标,分别用大小写字母进行标明,以虚线进行连接,中间点虚线的连线表示连接可能为同一目标的匹配,比如,A目标与a、c连接,表示A物体有可能与a或者c为同一目标。②中,先对A匹配,发现与A相连的a还没有匹配,因此使用实线进行连接,表示已经匹配;③中,对B进行匹配,发现与B匹配的右边第二个目标c没有匹配项,因此B与c使用实线连线连接,建立匹配关系;④中,对C匹配,发现最优先目标a已经有匹配对象了,需要将与a的匹配成功的关系先删除掉,使用划线连线表示,因为原先的匹配关系已经被删除,A无匹配项,因此需要给A重新匹配对象,此时需要去建立A与c的匹配关系;⑤中,由于与A相连的另一目标c已经有了匹配对象,于是将B、c之间的连接用划线代替,然后A就可以和c进行匹配;⑥中,A需要与c进行匹配,B与c或b都可以进行匹配,而且b没有匹配项,因此B与b之间用实线进行连接,匹配成功;⑦⑧⑨分别将最终匹配使用实线连线连接;⑩中为最终得到的最优匹配结果。
余弦距离
用于度量目标之间的外观相似性。余弦距离计算两个特征向量之间的夹角,从而评估它们的相似程度。在关联过程中,余弦距离可以有效地帮助区分外观相似但实际不同的目标。
余弦相似度(Cosine Similarity)是一种常用的度量两个向量之间相似性的指标,尤其在高维空间中非常有用。它通过计算两个向量夹角的余弦值来评估它们的相似程度。余弦相似度的取值范围在-1到1之间,其中1表示两个向量完全相同,-1表示两个向量完全相反,0表示两个向量正交(即不相似)。
余弦相似度的公式如下:
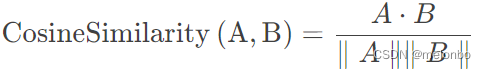
其中:
- A和B是两个向量。
- A⋅B表示向量A和B的点积。
- ||B||表示向量A的范数(即向量的长度或模)。
- ||B||表示向量B的范数。
余弦距离是余弦相似度的补数,即:

余弦距离的值范围在0到2之间,越接近0表示两个向量越相似,越接近2表示越不相似。
马氏距离算法
马氏距离是(Mahalanobis distance)是由印度统计学家马哈拉诺比斯(P. C. Mahalanobis)提出的。在DeepSort目标跟踪算法中会使用到,用于计算乘客目标检测框和乘客目标预测框之间的相似度。
在机器学习当中,我们经常会计算两个点、或一个点到一组点之间的距离,通常我们使用欧氏距离衡量两者之间的距离,判断两者的相似度。欧氏距离也叫做欧几里得(Euclidean distance)距离,它计算的是n维空间中两个点之间的绝对距离。
方差(variance)在概率论中用来衡量一组样本数据的离散程度。它是一个样本到样本集中每个样本之间距离的平方的和,再除以样本的总量。方差反映的是n维数据中一个维度的数据内部之间的关系,如果想要衡量一个维度和其它几个维度之间的关系,就不能使用方差了,这时候我们就需要协方差这个度量。协方差度量的多维空间中一个维度和其它维度之间的相关性的统计量。举个例子一个人的体重和一个人的饭量之间是否存在关系,就需要协方差来度量。如果体重和饭量之间的协方差是正值,说明这两者之间存在正相关的关系,如果这两者之间的协方差是负值,说明这两者之间存在负相关的关系,如果这两者之间的协方差是0,说明这两者之间的不存在关系。因此当数据维度超过一维后,就需要协方差矩阵来衡量这些数据维度之间的相关性了。
当协方差矩阵的逆矩阵为单位矩阵的时候,说明各个维度数据之间没有相关性,马氏距离就可以简化为欧氏距离。
马氏距离衡量的是数据之间的协方差距离,通过将不同维度特征的方差进行归一化处理,去除了量纲的影响,与单位无关,它能有效的度量两个数据集之间的相似度,更能反映真实环境中不同因素之间的关系。
非极大值抑制
非极大值抑制(Non-Maximum Suppression, NMS)是一种在目标检测任务中常用的后处理技术,用于去除重叠的检测框(bounding boxes),从而只保留最有可能包含目标的框。NMS通过抑制重叠度较高且置信度较低的检测框,提高了检测结果的准确性和可靠性。
非极大值抑制的步骤
-
置信度排序(Confidence Sorting):
将所有的检测框按置信度(confidence score)从高到低排序。置信度通常由目标检测器(例如,YOLO、SSD、Faster R-CNN等)提供,表示检测框包含目标的概率。 -
选择最高置信度框(Select the Highest Confidence Box):
从排序后的检测框列表中选择置信度最高的框,并将其加入最终保留的检测框集合。 -
计算重叠度(Compute Overlap):
对于剩余的检测框,计算它们与当前选择的最高置信度框之间的重叠度,通常使用交并比(Intersection over Union, IoU)来衡量。交并比的公式为: -
抑制重叠框(Suppress Overlapping Boxes):
将与当前选择的最高置信度框的重叠度超过设定阈值(例如0.5或0.3)的检测框移除,因为这些框被认为是重复检测。 -
重复步骤2-4:
从剩余的检测框中再次选择置信度最高的框,重复上述过程,直到没有剩余的检测框。















 778
778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









