







需求
根据文件某一列的数据,多线程并发执行代码,返回结果写入文件中,提升执行效率
Multiprocessing模块
Multiprocessing.Pool可以提供指定数量的进程供用户调用
当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来执行它。
流程图
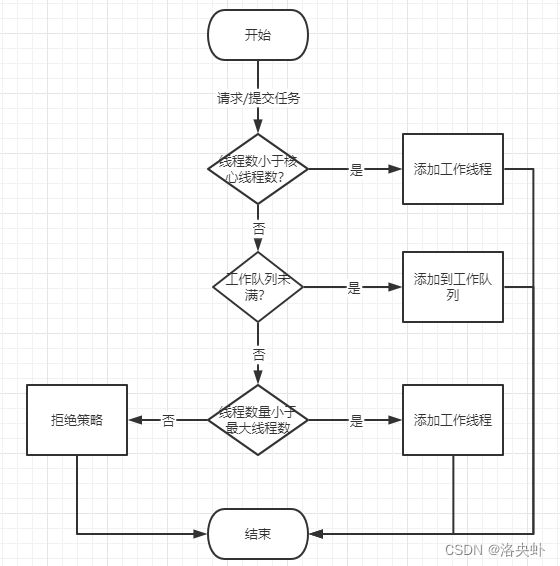
Pool类用于需要执行的目标很多,而手动限制进程数量又太繁琐时,如果目标少且不用控制进程数量则可以用Process类。
class multiprocessing.pool.Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]])
传参说明
processes: 是要使用的工作进程数。
如果进程是None,那么使用返回的数字os.cpu_count()。
也就是说根据本地的cpu个数决定,processes小于等于本地的cpu个数;
initializer: 如果initializer是None,那么每一个工作进程在开始的时候会调用initializer(*initargs)。
maxtasksperchild:工作进程退出之前可以完成的任务数,完成后用一个新的工作进程来替代原进程,来让闲置的资源被释放。
maxtasksperchild默认是None,意味着只要Pool存在工作进程就会一直存活。
context: 用在制定工作进程启动时的上下文,
一般使用 multiprocessing.Pool() 或者一个context对象的Pool()方法来创建一个池,
两种方法都适当的设置了context。
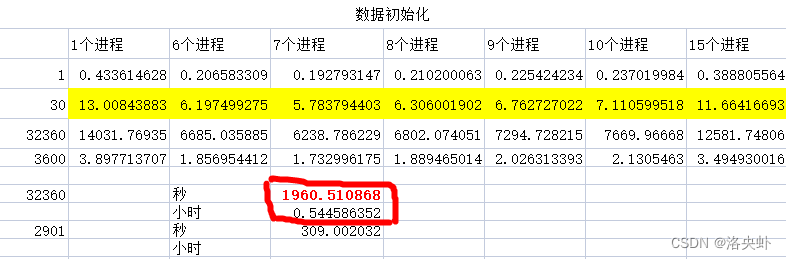
不同进程数耗时
机器配置:8C16G
传入不同进程数做数据化的请求耗时结果如下,可以看出,在进程7个的情况下耗时最小,实际7个线程跑3W的数据在0.5个小时就跑完了
代码如下
import time
from multiprocessing import Pool
import pandas as pd
class Generator_Login:
def __init__(self, result_path=None):
# result
self.result_path = result_path
# 账号
self.parent_result_path = self.result_path + 'login_parent.csv'
self.parent_login = None
self._index = 'account,ID'
self._field = ['account', 'ID']
def func1(self,*args):
start_1 = time.time()
login(args[0])
print('执行任务{}'.format(args))
end_1 = time.time()
print("单进程:", end_1 - start_1)
def deal_login(self, file,process: int = 1):
df = pd.DataFrame(pd.read_csv(file))
acccount_list = None
start_2 = time.time()
pool = Pool(processes=process)
acccount_list = df['phone']
self._write_raw_index(self.result_path, self._index )
for task in acccount_list:
#
pool.apply_async(self.func1, args=(task,))
pool.close()
pool.join()
print('主进程结束打印')
end_2 = time.time()
print("2进程:", end_2 - start_2)
# 在这段代码中,如果不加pool.close和 pool.join的话,会直接执行主进程的打印结束,同时进程池里的子进程也不会再运行
# 在加上pool.close和 pool.join之后,会将主进程阻塞,让子进程继续运行完成,子进程运行完后,再把主进程全部关掉。
if __name__ == '__main__':
login = Generator_Login()
login.deal_login(file='logs/user.csv', process=7)















 1251
1251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









