






打开anaconda,打开cmd。
1.输入cd +DeeplabCut所在文件地址 UserWarning2.
cd C:\Users\hanhan\Documents\DeeplabCut\DeepLabCut-master2.conda activate +环境名字 //激活环境
3.然后打开ipython
![]()
4. 进入ipython后import deeplabcut as dlc

导入dlc的package后可能会出现futureWarning,这个不用管
5.用dlc.creat_new_project(r'freeexploration‘,r'hanhan’,[r'...\videos\m3v1mp4.mp4'],copy_videos=True)创建工程,工程名字为freeexploration,创建人为hanhan,...\videos\m3v1mp4.mp4表示视频地址。copy_videos=True很重要,如果不加,创建工程里面只有视频的快捷方式,将文件夹上传到google colab会出现视频不存在警告,这个主要是指明将这个文件拷贝到工程文件夹中。
![]()
这个是命令创建的配置文件,很重要 ,所有的配置参数都要在这个文件中指定,每一条命令中的第一个参数基本上都是指向这个配置文件。移动工程只需要更改这个文件路径。
打开文件config.yaml
 设置所需要检测的部分,四个不够可以自己加,注意:要英文
设置所需要检测的部分,四个不够可以自己加,注意:要英文
![]()
0表示视频起始,1表示视频结束
![]()
表示提取训练图片的数量
将识别部位连接组成骨架,如下图

![]() 表示一个连接
表示一个连接
 骨架颜色,概率阈值(dlc对每个部位预测都有概率,只有概率大于0.6才会被identify),各个部位给出点大小,点透明程度,点配色方案。
骨架颜色,概率阈值(dlc对每个部位预测都有概率,只有概率大于0.6才会被identify),各个部位给出点大小,点透明程度,点配色方案。
 模型训练参数,训练和测试比例(95%用来训练),迭代次数指一整个流程的迭代(第一次为0),采用深度网络类型,增加数据方案,不同index指向不同训练阶段的神经网络模型(-1表示最后保存的那个),测试的时候一个batch用到8个数据。
模型训练参数,训练和测试比例(95%用来训练),迭代次数指一整个流程的迭代(第一次为0),采用深度网络类型,增加数据方案,不同index指向不同训练阶段的神经网络模型(-1表示最后保存的那个),测试的时候一个batch用到8个数据。
cropping:false 是否用对原始数据裁剪的方式增加数据
croppedtraining:false 是否用这种裁剪方式训练
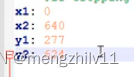 表示如果需要裁剪,裁剪的大小。
表示如果需要裁剪,裁剪的大小。
回到cmd![]() 输入config_path=之前创建的config.yaml的文件路径
输入config_path=之前创建的config.yaml的文件路径
 建立数据帧的提取
建立数据帧的提取
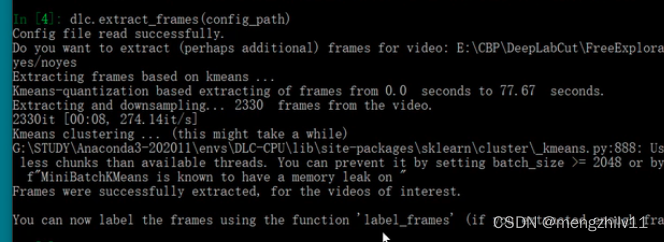 自动提取帧。
自动提取帧。
![]()
执行这个命令导入图片
执行后会出现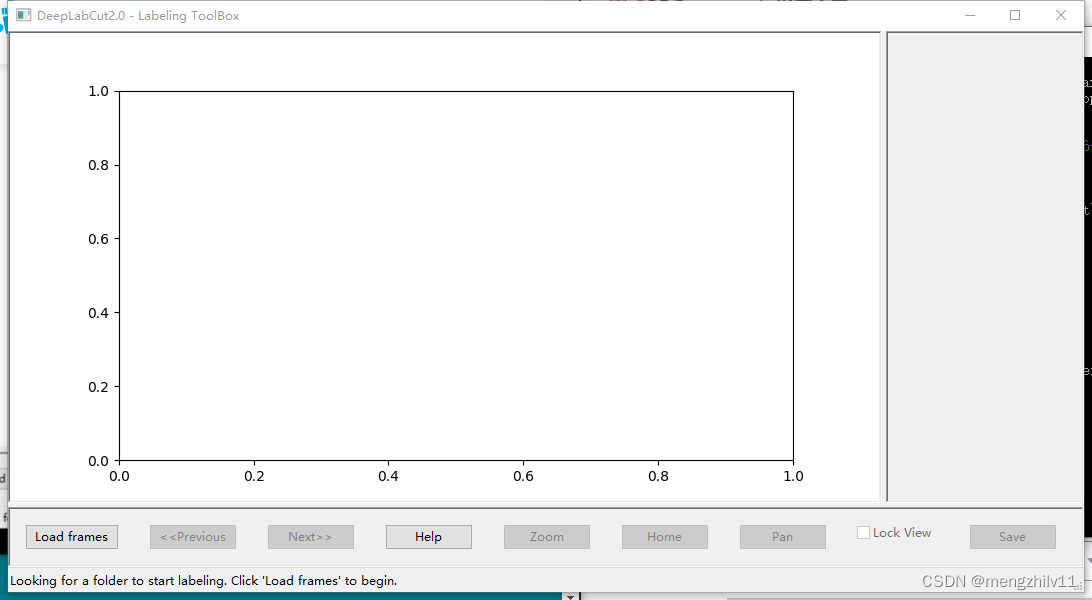
点击load frames选择路径载入图像。
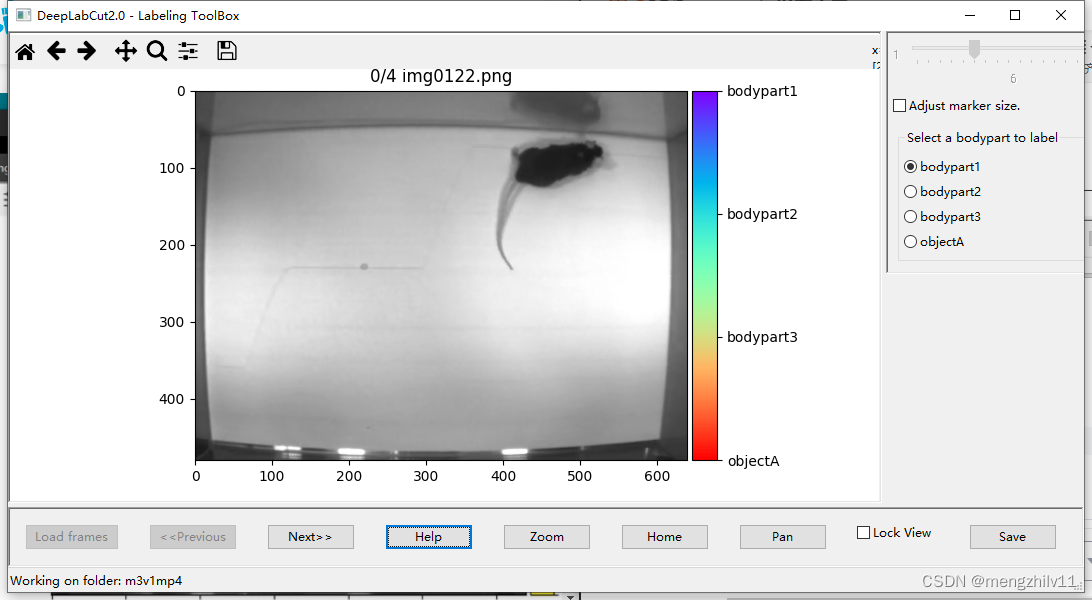
一共五张,对于每张图像都要给出label ,zoom放大选中区域,用右键选取点,选错了也没关系,可以左键按住点来拖动。选完一张next选下一张,全部选完后save 然后退出。

执行检查label对不对。
打开对应文件夹看对不对
![]()
随便打开一个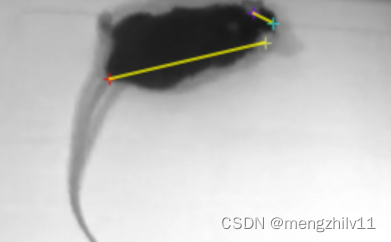
输入dlc.create_training_dataset(config_path,net_type='resnet_50', augmenter_type='imgaug')生成训练数据

打开路径...\dlc-models\iteration-0\fishJun14-trainset80shuffle1\train 里面的pose_cfg.yaml文件里面可以修改训练参数,修改完参数后输入dlc.train_network(path_config_file, shuffle=1, displayiters=100,saveiters=500)开始训练
原视频链接:2.5小时入门DeepLabCut (4) Coding on local PC_哔哩哔哩_bilibili
GitHub上的帮助文档:Multi-animal pose estimation with DeepLabCut: A 5-minute tutorial — DeepLabCushuru















 3766
3766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









