







论文题目:《Multi-animal pose estimation, identification and tracking with DeepLabCut》
发表期刊:Nature Methods

一、引言
1.背景
估计多个动物的姿态是一个具有挑战性的计算机视觉问题:频繁的交互会导致遮挡,并使检测到的关键点与正确个体的关联变得复杂,并且看起来高度相似的动物之间的互动比典型的多人场景中更为密切。
许多生物学实验——从养老鼠到鱼群行为——都需要测量多个个体之间的相互作用。这些任务可以用机器视觉技术来解决。一般来说,该过程需要三个步骤:姿势估计(即关键点定位)、组装(即将关键点分组为不同动物的任务)和跟踪。
2.研究目的
为了应对这一挑战,研究者以开源姿势估计工具箱 DeepLabCut 为基础,提供了多动物场景所需的高性能动物装配和跟踪功能。(个人理解:“组装”指的是将多个动物的识别和姿态估计数据整合在一起,以便于进行统一分析;而“跟踪”则是指对这些动物的运动轨迹进行记录和分析。)此外,还整合了预测动物身份的能力,以协助跟踪(在遮挡的情况下)。用四个复杂程度不同的数据集来说明这一框架的强大功能,并将其作为未来算法开发的基准。
介绍:DeepLabCut是什么?

https://www.mackenziemathislab.org/deeplabcut/ https://www.mackenziemathislab.org/deeplabcut/
https://www.mackenziemathislab.org/deeplabcut/
DeepLabCut 是一个基于深度学习的开源工具,专门用于精确标注和追踪动物行为。由Mackenzie Mathis及其团队开发,DeepLabCut在神经科学和行为研究中得到了广泛应用。 它的主要功能包括:
- 关键点标注:通过深度学习模型,自动标注动物身体的关键点(如关节、尾巴、头部等)。
- 多物体追踪:能够在同一视频中同时追踪多个个体。
- 多种动物支持:支持多种动物的标注和追踪,包括小鼠、鱼、鸟类、昆虫等。
用户需要提供一小部分带有手动标注的训练数据,DeepLabCut提供了一个可视化界面,允许用户在每个帧中标记关键点或身体部位。这些标记将用于训练深度学习模型。标注的关键点作为模型的训练样本。利用卷积神经网络(CNN),DeepLabCut对标注的数据进行训练,生成能够自动标注关键点的模型。训练好的模型可以应用于新的视频中,自动检测和标注动物的行为关键点并输出其位置和姿态信息。
通过深度学习,DeepLabCut在各种复杂背景下依然能够准确标注和追踪动物行为。极大减少了手动标注的工作量,提高了研究效率。支持用户自定义的标注方案,适应不同的研究需求。
3.本研究贡献
本研究扩展了DeepLabCut,这是一个用于动物姿势估计的开源工具箱。具体贡献如下:
- 4个不同难度的数据集,用于对多动物姿态估计网络进行基准测试。
- 多任务架构,可预测多个条件随机场,因此可以预测关键点、肢体以及动物身份。
- 一种数据驱动的动物装配方法,在不需要用户输入的情况下找到最佳骨架,这是最新技术(与标准计算机视觉基准 COCO 的顶级模型相比)。
- 将跟踪问题转化为一个网络流优化问题,旨在寻找全局最优解。
- 监督的动物ID跟踪:我们可以预测动物的身份并重新识别它们;当基于时间的跟踪失败时(由于间歇性遮挡),这对于跨时间链接动物特别有用。
- 用于关键点注释、细化和半自动轨迹验证的图形用户界面(GUI)。
二、数据集描述
作者考虑使用四项多动物实验来广泛验证他们的方法:
- 露天场地老鼠数据集:记录三只老鼠在开放场地中的互动行为,处理频繁接触和遮挡问题
- 老鼠亲子行为数据集:记录成年老鼠和其幼崽的互动,处理幼崽与背景难以区分的问题
- 成对狨猴数据集:记录两只猴子在大型围栏中的行为,处理遮挡、非静止行为和运动模糊问题
- 鱼群数据集:记录14条鱼在流动水箱中的行为,处理遮挡和视野外的问题
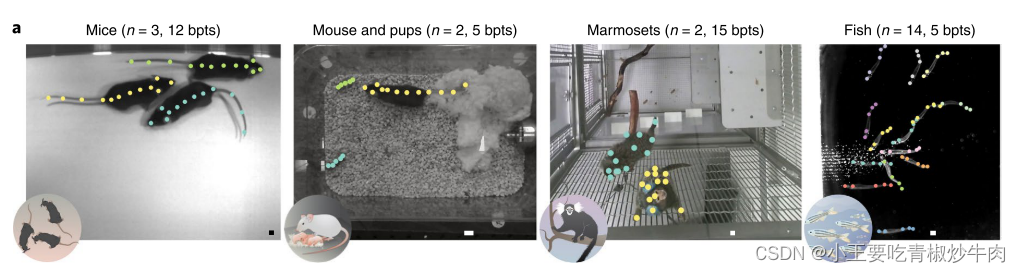
这些数据集涵盖了广泛的行为,给姿势估计和跟踪带来了困难和独特的计算挑战。三只小鼠经常相互接触和遮挡。育儿数据集包含一只具有独特关键点的成年小鼠,它与两只幼鼠密切互动,很难从背景或棉花巢中区分开来,这也会导致遮挡。狨猴数据集包括遮挡期、密切互动、非稳态行为、运动模糊和比例变化。同样,鱼群沿着水箱的各个维度游动,在杂乱的场景中相互遮挡,偶尔还会离开摄像机的视野。
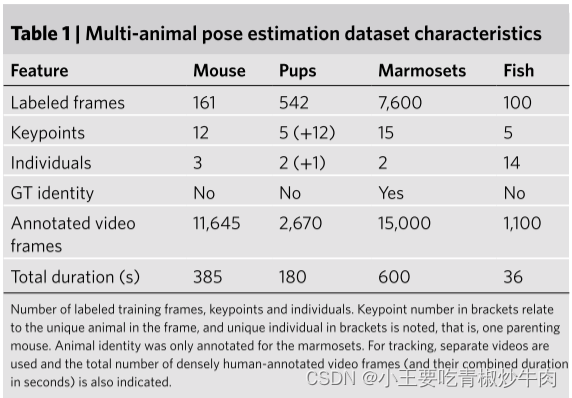
作者根据数据集在多个帧中标注了 5-15 个感兴趣的身体部位,用于交叉验证姿势估计和组装性能,还半自动地标注了几个视频,用于评估跟踪性能。为了进行分析,我们将图像和注释随机分成 70% 的训练集和 30% 的测试集。
多动物姿态估计数据集特征表如下:
三、方法
1.关键点检测与组装
(1)DLCRNet_ms5架构
(a)网络介绍
DLCRNet_ms5是由经过 ImageNet 训练的 ResNets、EfficientNets开发得到的一种多尺度架构。
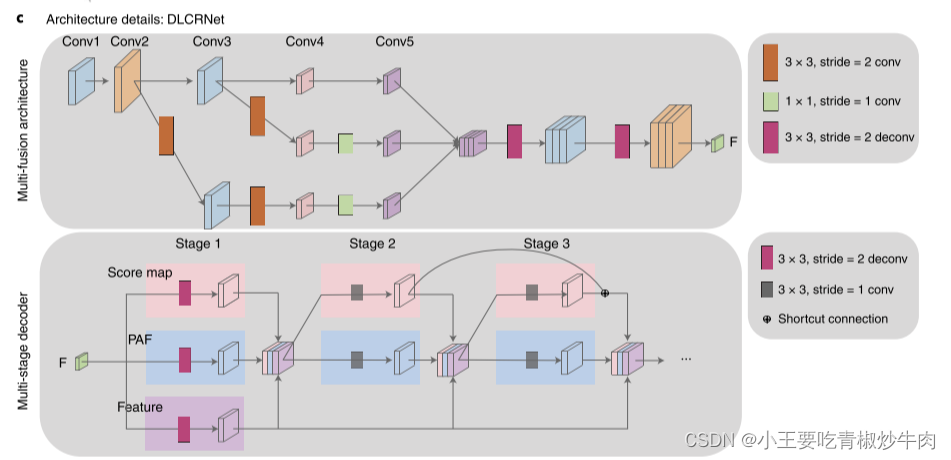
这幅网络图详细展示了DeepLabCut中DLCRNet架构的细节,包括多融合模块(Multi-fusion module)和多阶段解码器(Multi-stage decoder)。
图的上部分表示多融合模块,Conv1 到 Conv5 是一系列的卷积层,用来从图像中提取不同层次的特征。每个卷积层使用不同的卷积操作,比如 3x3 卷积(stride=2),1x1 卷积等。这些操作帮助提取不同尺度的特征。特征从 Conv2 和 Conv3 层被分别下采样(减小尺寸),然后通过 1x1 卷积层减少计算量。这些特征接着被融合(结合在一起),并经过一系列 3x3 卷积和反卷积操作(deconvolution),最终生成一个综合的特征图。
图的下部分表示多阶段解码器,通过多阶段解码器逐步处理特征图。初始特征图由多融合模块生成,然后传递到多阶段解码器进行处理。在第一阶段中,解码器生成两个输出:分数图(Score Map) 和 部件关联场(PAF)。分数图用于预测图像中动物关键点的位置。部件关联场用于预测连接关键点的向量场,帮助识别和理解两个关键点之间的关系。在第二、第三阶段中继续处理特征图,并生成新的分数图和 PAF。在每个阶段,分数图和 PAF 都会与特征图结合,进一步细化预测结果。这些阶段之间有 快捷连接(Shortcut Connection),确保信息能有效地在各阶段之间传递和融合。
经过多阶段处理,网络最终生成精确的分数图和 PAF,标注出动物的关键点及其相互关系。该网络的工作流程可以总结为以下四个阶段:
- 输入图像:网络接收并处理包含动物的图像。
- 特征提取:图像经过一系列卷积层提取不同层次的特征,融合多个卷积层的特征,生成综合特征图。
- 多阶段解码:多阶段解码器逐步处理特征图,每个阶段生成分数图和 PAF,逐步细化和提升预测精度。
- 输出结果:网络最终输出精确的动物关键点标注和连接关系,帮助研究人员追踪和分析动物行为。
(b)性能评估
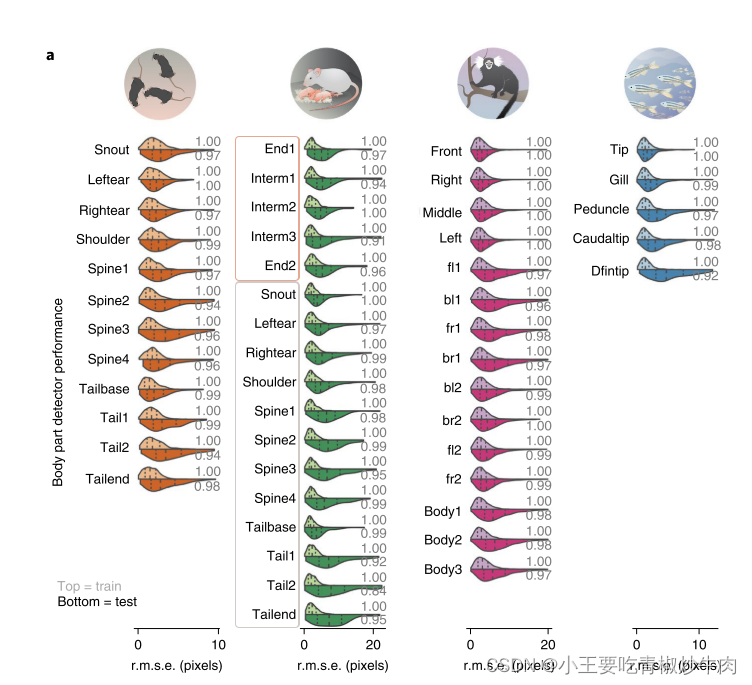
研究者为每个数据集和每个分割训练了独立的网络,并评估了它们的性能。对于每个帧和关键点,都计算了检测结果与其最接近的地面实况邻居之间的均方根误差(r.m.s.e.)。
如图,是步幅为 8 的 DLCRNet_ ms5 的关键点预测误差分布,数据集拆分为70% 训练集和 30% 测试集。小提琴图顶部表述训练误差,底部表示测试误差。垂直虚线是第一、第二和第三个四分位数,灰色数字表示PCK,关键点正确估计的比例。图示数据集的误差中值依次为 2.69、5.62、4.65 和 2.80 像素,说明所有关键点检测器均表现良好。
(2)部件关联场(PAF)
检测之后,需要将关键点分配给个体。使用PAF来决定两个身体部位是否属于同一个动物。PAF是一组二维向量场,表示图像中不同部位之间的关联和方向信息。其目的是在图像中识别和连接各个关键点,从而重建完整的姿态。
其原理是:首先,使用卷积神经网络(CNN)检测图像中的关键点。每个关键点对应一个特定的部位。生成一组PAFs,每个PAF表示一个部位对之间的向量场。这些向量场描述了两个关键点之间的关系,如方向和关联性。利用PAF,连接相应的关键点,以重建出骨架结构。这一步涉及到通过计算向量场的方向和强度来确定哪些关键点应该连接在一起。
12 个小鼠身体部位可以形成 66 条不同的边缘,下图由多个小图组成,每个小图展示了两个小鼠身体部位之间的分布情况,纵坐标表示“边的可分离性能力”(Edge separability power),即区分正确连接与错误连接的能力。
每个小图顶部的数字是AUC分数,表示区分这两种分布的能力,分数越高表示区分能力越强。图中以饱和颜色标识的子图是选择出的11条边,组成最小且最优的部件亲和图。这些边具有较高的AUC分数,表示它们在区分同一小鼠的关键点连接和不同小鼠的关键点连接时,具有很强的区分能力。

(3)数据驱动的骨架选择
传统方法需要用户手动定义关键点之间的连接,这既费时又复杂。为了减轻用户负担,研究人员开发了一种完全基于数据驱动的方法。
模型在一个包含所有可能身体部位连接的完整图上进行训练,以学习这些连接的特征。研究人员测试了将完整的狨猴骨架随机修剪到其原始大小的25%、50%和75%(对应26、52、78条边或52、104、156个PAF)是否仍能产生可接受的结果。结果表明,训练前将大图修剪到四分之一会显著降低性能(mAP损失15-20点)。但如果修剪到一半或75%的大小,性能几乎与完整图相当,仅比最大mAP得分低约1.5点。
在训练集上,根据边缘的辨别力修剪图。具体做法是评估动物内部和动物之间的部件亲和成本分布,并根据这些分布的分离能力对边缘进行排序。使用auROC曲线评估边缘的分离能力,保留最能分离的边缘,形成一个最大生成树,这个生成树覆盖所有关键点并且边数最少。
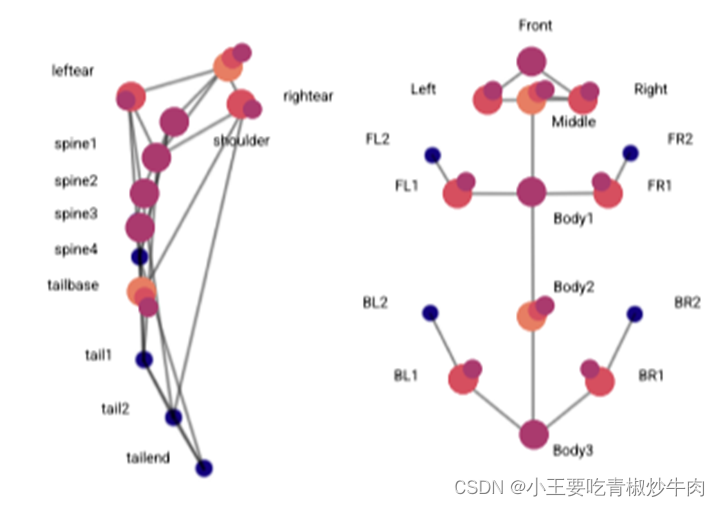
2.跟踪与身份预测
(1)轨迹拼接
在轨迹追踪中,重要的一步是将同一动物在不同帧中的关键点关联起来,形成连续的轨迹。由于动物之间的交互、遮挡、快速移动或环境变化等原因,长时间的连续追踪可能会中断,形成多个短片段,这些短片段就是tracklets。
tracklets通常被视为中间步骤,它们可以是自下而上方法的结果,也可以是更复杂追踪算法的输入。在更复杂的追踪算法中,tracklets可能会被用来构建更长的时间轨迹,或者与其他tracklets合并,以创建更加连贯和完整的动物轨迹。总的来说,tracklets是分析视频序列中对象运动的重要工具,尤其是在处理复杂或动态场景时。
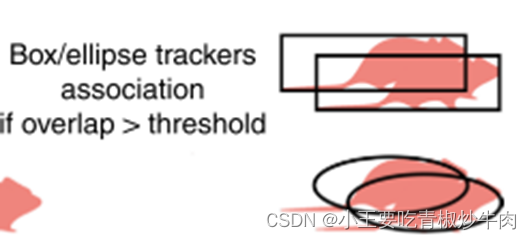
研究人员实现了一个轻量级的“追踪器”来预测动物在下一帧中的位置。他们特别实现了一个矩形和椭圆形追踪器。椭圆形追踪器是研究人员为动物追踪而开发的更先进的追踪器。它考虑了动物的实际形状,通常使用椭圆形来表示动物的身体轮廓。与矩形追踪器相比,椭圆形追踪器提供了对动物几何形状更精细的参数化,使其更适合动物追踪任务。椭圆形追踪器在多对象追踪准确性(MOTA)上表现得更好,并减少了假阴性,即在追踪过程中错误地将动物排除在外的情况。
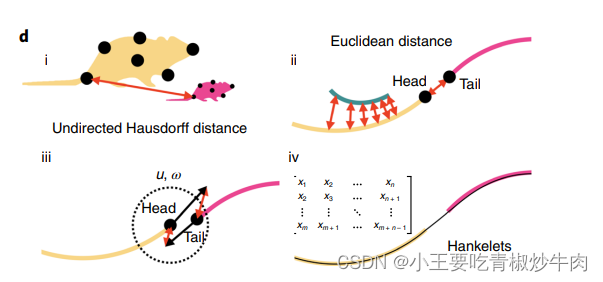
研究者将稀疏的tracklets缝合任务视为一个全局最小化问题。连接两个候选tracklets的成本与它们属于同一条轨迹的可能性成反比,换句话说,连接两个tracklets的成本越低,它们越有可能属于同一条轨迹。并在拼接时考虑多种时空线索。
使用优化算法,在图中找到最优路径,将候选tracklets连接起来,以形成连续的轨迹。这些优化算法考虑了多个成本函数:
- 使用有限关键点集之间的无向豪斯多夫距离的形状相似性
- 欧几里得空间中的空间邻近性
- 使用轨迹位置双向预测的运动亲和力
- 通过 Hankelets 和 tracklet 质心的延时嵌入的动态相似性
通过优化拼接方法,减少了tracklets之间的错误连接和身份交换次数,即使在复杂的场景中也是如此。在鱼类和狨猴等具有挑战性的数据集中,这种拼接方法显著减少了交换次数,改善了追踪精度。
在这个动物追踪问题中,研究人员使用了图和亲和力模型。图中的节点代表tracklets,边代表可能的连接。每条边都有一个权重,表示连接两个tracklets的成本。亲和力模型用于计算tracklets之间的相似性和连接成本。这个模型结合了多种线索(形状、接近度等)来评估两个tracklets是否应该连接。
(2)动物身份预测
动物有时在视觉上不同,例如由于不同的皮毛图案,因为它们有标记,或者携带不同的工具。所以利用图像对动物身份进行预测。
一个卷积神经网络被训练来预测每个个体的所有关键点的总分数图。看哪个输出类别的可能性最大(对于给定的关键点),并将该身份分配给关键点。
为了对 ID 输出进行基准测试,我们将重点放在狨猴的数据上,其中(对于每一对狨猴) ,一只狨猴的绒毛上涂抹了浅蓝色染料。对于最接近狨猴头部的关键点,测试图像上的 ID 预测准确性范围从 > 0.99到更远端关键点的0.95。
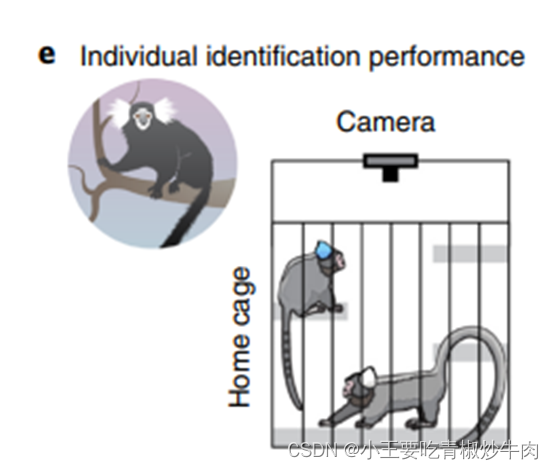
(3)利用动物ID和重新识别(reID)进行追踪
当动物可能消失在视野中时,仅依靠时间关联无法进行追踪,这时需要外观线索。实际上,对于狨猴,通过监督学习的方式结合视觉外观,进一步减少了26%的切换次数。此外,我们还考虑了人类注释者无法清晰区分的动物情况,因此无法轻易提供地面真实值。为了解决这一挑战,我们引入了一种基于变换器(transformers)的无监督方法,通过度量学习来学习动物ID。这在非常具有挑战性的鱼类数据中,特别是在困难的序列中,将MOTA性能提高了多达10%。
研究人员开发了一种基于变换器的无监督学习方法。变换器是一种深度学习模型,通过度量学习来学习和识别动物的ID。度量学习是一种方法,旨在将相似的对象拉近,而将不同的对象拉远。这里,度量学习用于区分不同个体的动物ID。
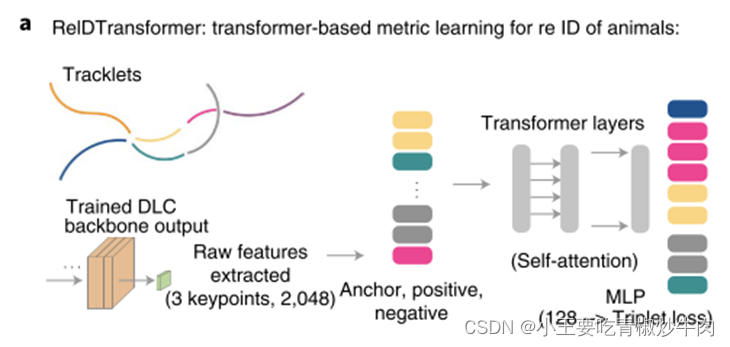
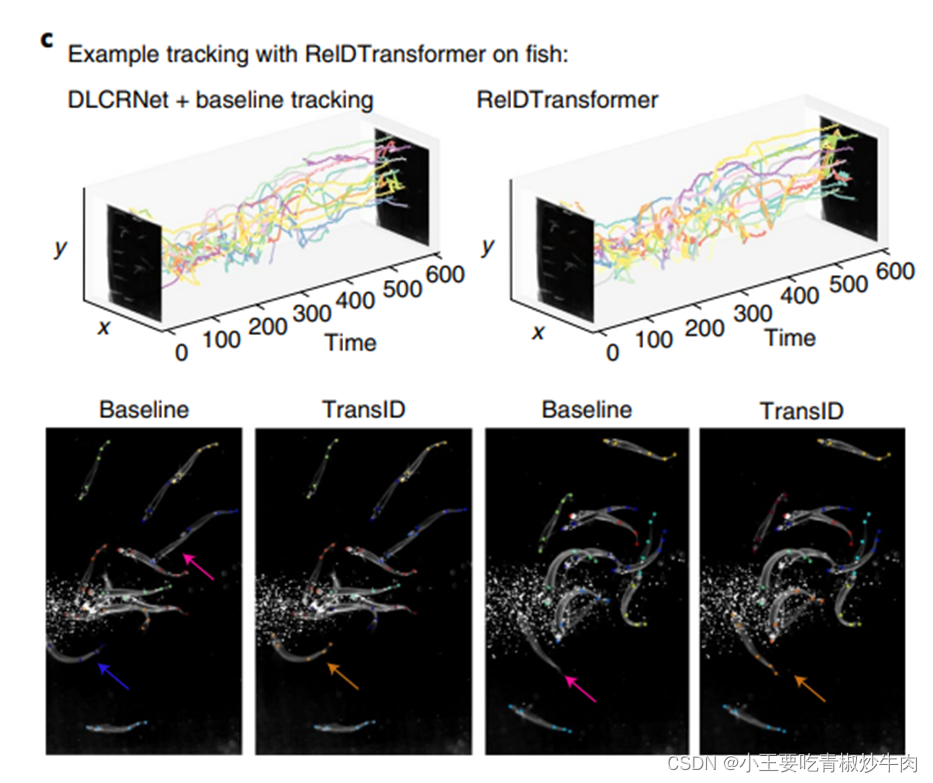
四、应用示例
通过分析成对长尾绒猴9小时(824,568帧)的家笼行为,展示了该方法在长时间、多动物行为跟踪中的应用效果。
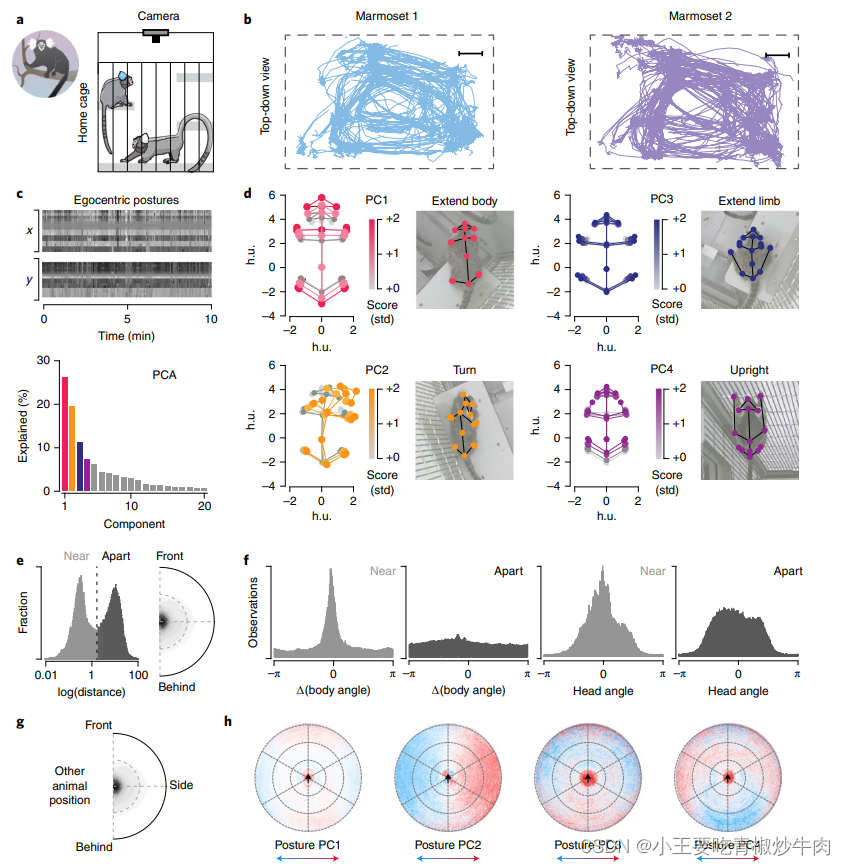
a、狨猴记录装置示意图。
b, 每只狨猴 30 分钟的轨迹示例。比例尺为 0.2 米。
c、以自我为中心的姿势数据示例,其中 “Body2 ”点为(0,0),“Body1 ”和 “Body3 ”形成的角度旋转为 0°。我们对两只狨猴的所有数据进行了主成分分析。
d、每个主成分的平均姿态;注意图像中只显示了分布的一边(即 0 到 2,而不是 -2 到 2)。
e, 一对狨猴之间的对数距离直方图,以耳中心距离归一化。
f、计算的身体角度与观察次数的关系。
g, 另一只狨猴相对于狨猴 1 的位置密度图。
h、姿势主成分(来自 d)与另一只狨猴相对位置的函数关系。因此,每个点代表狨猴 1 在狨猴 2 处时的姿势主成分平均得分。
五、总结
开发了一种扩展DeepLabCut的方法,实现了高效的多动物姿态估计和跟踪,验证了其在多种复杂场景中的适用性和高性能。


















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









