









一.决策树算法简介
《统计学习方法》书中提到:统计学习=模型+策略+算法。接下来对于每个机器学习的算法,我都尝试从模型,策略,算法三个角度进行归纳。针对决策树算法:
1.模型
决策树算法实质上是从训练数据集中归纳出一组分类规则,也可以理解为对特征空间(超平面)的一种线性划分。决策树算法并没有一个参数化的模型,但是拥有条件概率的解释。如下图所示:
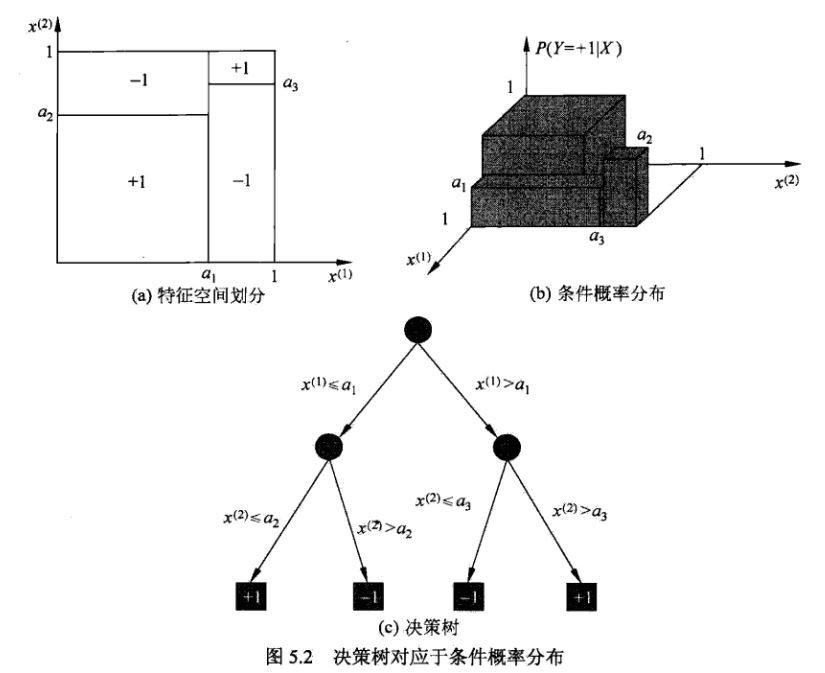
2.策略
由于决策树模型并没有一个参数化的模型,那么在初始时候也就无法写出显示的损失函数表达式。在现实中决策树模型采取的策略是启发式的学习:即先直接针对训练数据,利用相应的算法得到一组分类规则,然后再写出损失函数,并进行剪枝。假定依据某种算法,我们得到了一组规则,也得到了一颗决策树,那么这时候我们就可以写出参数化的损失函数:
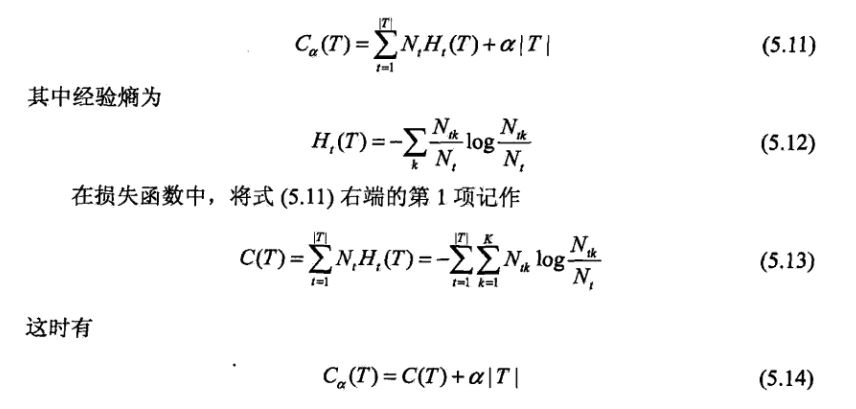
3.算法
决策树模型采用的算法有两部分:生成决策树的算法和剪枝的算法。
生成决策树的算法:算法的思想是每次选择具有最好分类能力的特征来进行分类,利用该特征将数据集分割成子集,每个子集再递归进行分类。详见ID3,C4.5,CART算法。这种算法思想有些像贪心的策略:我的目的是对训练数据进行分类,现在训练数据有n个特征,那么依据贪心的策略,我每次都是选取分类效果最好的特征进行分类。至于如何评价一个特征分类效果的好坏,而需要信息增益相关的知识,可参考《统计学习方法》。
剪枝的算法:从叶子节点自下而上进行剪枝,可视为利用了DP的思想。
二.python实现
《机器学习实战》中实现的是ID3算法,没有进行剪枝的操作,创建决策树的函数程序如下:
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]//取数据集中类别标签,生成一个list
if classList.count(classList[0]) == len(classList):
return classList[0]#stop splitting when all of the classes are equal
if len(dataSet[0]) == 1: #stop splitting when there are no more features in dataSet
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)//利用信息增益最大化的准则选取当前进行划分的特征
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}//建立字典,bestFeatLabel的含义是最佳分类特征的实际名称
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]//取当前最佳分类特征的取值向量
uniqueVals = set(featValues)
for value in uniqueVals://对当前最佳分类特征的每个取值,递归构建子树
subLabels = labels[:] #copy all of labels, so trees don't mess up existing labels
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree 三.C++实现
shark2.4.5库中没有决策树,因此找了其他博主写的博客http://blog.csdn.net/yangliuy/article/details/7322015
程序如下:
#include <iostream>
#include <string>
#include <vector>
#include <map>
#include <algorithm>
#include <cmath>
using namespace std;
#define MAXLEN 6//输入每行的数据个数
//多叉树的实现
//1 广义表
//2 父指针表示法,适于经常找父结点的应用
//3 子女链表示法,适于经常找子结点的应用
//4 左长子,右兄弟表示法,实现比较麻烦
//5 每个结点的所有孩子用vector保存
//教训:数据结构的设计很重要,本算法采用5比较合适,同时
//注意维护剩余样例和剩余属性信息,建树时横向遍历考循环属性的值,
//纵向遍历靠递归调用
vector <vector <string> > state;//实例集
vector <string> item(MAXLEN);//对应一行实例集
vector <string> attribute_row;//保存首行即属性行数据
string end("end");//输入结束
string yes("yes");
string no("no");
string blank("");
map<string,vector < string > > map_attribute_values;//存储属性对应的所有的值
int tree_size = 0;
struct Node{//决策树节点
string attribute;//属性值
string arrived_value;//到达的属性值
vector<Node *> childs;//所有的孩子
Node(){
attribute = blank;
arrived_value = blank;
}
};
Node * root;
//根据数据实例计算属性与值组成的map
void ComputeMapFrom2DVector(){
unsigned int i,j,k;
bool exited = false;
vector<string> values;
for(i = 1; i < MAXLEN-1; i++){//按照列遍历,对于每一个属性
for (j = 1; j < state.size(); j++){//遍历每一个样本
for (k = 0; k < values.size(); k++){//统计每种属性所拥有的不同取值的数目
if(!values[k].compare(state[j][i])) exited = true;
}
if(!exited){
values.push_back(state[j][i]);//注意Vector的插入都是从前面插入的,注意更新it,始终指向vector头
}
exited = false;
}
map_attribute_values[state[0][i]] = values;
values.erase(values.begin(), values.end());
}
}
//根据具体属性和值来计算熵
double ComputeEntropy(vector <vector <string> > remain_state, string attribute, string value,bool ifparent){
vector<int> count (2,0);
unsigned int i,j;
bool done_flag = false;//哨兵值
for(j = 1; j < MAXLEN; j++){
if(done_flag) break;
if(!attribute_row[j].compare(attribute)){
for(i = 1; i < remain_state.size(); i++){
if((!ifparent&&!remain_state[i][j].compare(value)) || ifparent){//ifparent记录是否算父节点
if(!remain_state[i][MAXLEN - 1].compare(yes)){
count[0]++;
}
else count[1]++;
}
}
done_flag = true;
}
}
if(count[0] == 0 || count[1] == 0 ) return 0;//全部是正实例或者负实例
//具体计算熵 根据[+count[0],-count[1]],log2为底通过换底公式换成自然数底数
double sum = count[0] + count[1];
double entropy = -count[0]/sum*log(count[0]/sum)/log(2.0) - count[1]/sum*log(count[1]/sum)/log(2.0);
return entropy;
}
//计算按照属性attribute划分当前剩余实例的信息增益
double ComputeGain(vector <vector <string> > remain_state, string attribute){
unsigned int j,k,m;
//首先求不做划分时的熵
double parent_entropy = ComputeEntropy(remain_state, attribute, blank, true);
double children_entropy = 0;
//然后求做划分后各个值的熵
vector<string> values = map_attribute_values[attribute];
vector<double> ratio;
vector<int> count_values;
int tempint;
for(m = 0; m < values.size(); m++){
tempint = 0;
for(k = 1; k < MAXLEN - 1; k++){
if(!attribute_row[k].compare(attribute)){
for(j = 1; j < remain_state.size(); j++){
if(!remain_state[j][k].compare(values[m])){
tempint++;
}
}
}
}
count_values.push_back(tempint);
}
for(j = 0; j < values.size(); j++){
ratio.push_back((double)count_values[j] / (double)(remain_state.size()-1));
}
double temp_entropy;
for(j = 0; j < values.size(); j++){
temp_entropy = ComputeEntropy(remain_state, attribute, values[j], false);
children_entropy += ratio[j] * temp_entropy;
}
return (parent_entropy - children_entropy);
}
int FindAttriNumByName(string attri){
for(int i = 0; i < MAXLEN; i++){
if(!state[0][i].compare(attri)) return i;
}
cerr<<"can't find the numth of attribute"<<endl;
return 0;
}
//找出样例中占多数的正/负性
string MostCommonLabel(vector <vector <string> > remain_state){
int p = 0, n = 0;
for(unsigned i = 0; i < remain_state.size(); i++){
if(!remain_state[i][MAXLEN-1].compare(yes)) p++;
else n++;
}
if(p >= n) return yes;
else return no;
}
//判断样例是否正负性都为label
bool AllTheSameLabel(vector <vector <string> > remain_state, string label){
int count = 0;
for(unsigned int i = 0; i < remain_state.size(); i++){
if(!remain_state[i][MAXLEN-1].compare(label)) count++;
}
if(count == remain_state.size()-1) return true;
else return false;
}
//计算信息增益,DFS构建决策树
//current_node为当前的节点
//remain_state为剩余待分类的样例
//remian_attribute为剩余还没有考虑的属性
//返回根结点指针
Node * BulidDecisionTreeDFS(Node * p, vector <vector <string> > remain_state, vector <string> remain_attribute){
//if(remain_state.size() > 0){
//printv(remain_state);
//}
if (p == NULL)
p = new Node();
//先看搜索到树叶的情况
if (AllTheSameLabel(remain_state, yes)){
p->attribute = yes;
return p;
}
if (AllTheSameLabel(remain_state, no)){
p->attribute = no;
return p;
}
if(remain_attribute.size() == 0){//所有的属性均已经考虑完了,还没有分尽
string label = MostCommonLabel(remain_state);
p->attribute = label;
return p;
}
double max_gain = 0, temp_gain;
vector <string>::iterator max_it = remain_attribute.begin();
vector <string>::iterator it1;
for(it1 = remain_attribute.begin(); it1 < remain_attribute.end(); it1++){
temp_gain = ComputeGain(remain_state, (*it1));
if(temp_gain > max_gain) {
max_gain = temp_gain;
max_it = it1;
}
}
//下面根据max_it指向的属性来划分当前样例,更新样例集和属性集
vector <string> new_attribute;
vector <vector <string> > new_state;
for(vector <string>::iterator it2 = remain_attribute.begin(); it2 < remain_attribute.end(); it2++){
if((*it2).compare(*max_it)) new_attribute.push_back(*it2);
}
//确定了最佳划分属性,注意保存
p->attribute = *max_it;
vector <string> values = map_attribute_values[*max_it];
int attribue_num = FindAttriNumByName(*max_it);
new_state.push_back(attribute_row);
for(vector <string>::iterator it3 = values.begin(); it3 < values.end(); it3++){
for(unsigned int i = 1; i < remain_state.size(); i++){
if(!remain_state[i][attribue_num].compare(*it3)){
new_state.push_back(remain_state[i]);
}
}
Node * new_node = new Node();
new_node->arrived_value = *it3;
if(new_state.size() == 0){//表示当前没有这个分支的样例,当前的new_node为叶子节点
new_node->attribute = MostCommonLabel(remain_state);
}
else
BulidDecisionTreeDFS(new_node, new_state, new_attribute);
//递归函数返回时即回溯时需要1 将新结点加入父节点孩子容器 2清除new_state容器
p->childs.push_back(new_node);
new_state.erase(new_state.begin()+1,new_state.end());//注意先清空new_state中的前一个取值的样例,准备遍历下一个取值样例
}
return p;
}
void Input(){
string s;
while(cin>>s,s.compare(end) != 0){//-1为输入结束
item[0] = s;
for(int i = 1;i < MAXLEN; i++){
cin>>item[i];
}
state.push_back(item);//注意首行信息也输入进去,即属性
}
for(int j = 0; j < MAXLEN; j++){
attribute_row.push_back(state[0][j]);
}
}
void PrintTree(Node *p, int depth){
for (int i = 0; i < depth; i++) cout << '\t';//按照树的深度先输出tab
if(!p->arrived_value.empty()){
cout<<p->arrived_value<<endl;
for (int i = 0; i < depth+1; i++) cout << '\t';//按照树的深度先输出tab
}
cout<<p->attribute<<endl;
for (vector<Node*>::iterator it = p->childs.begin(); it != p->childs.end(); it++){
PrintTree(*it, depth + 1);
}
}
void FreeTree(Node *p){
if (p == NULL)
return;
for (vector<Node*>::iterator it = p->childs.begin(); it != p->childs.end(); it++){
FreeTree(*it);
}
delete p;
tree_size++;
}
int main(){
Input();
vector <string> remain_attribute;
string outlook("Outlook");
string Temperature("Temperature");
string Humidity("Humidity");
string Wind("Wind");
remain_attribute.push_back(outlook);
remain_attribute.push_back(Temperature);
remain_attribute.push_back(Humidity);
remain_attribute.push_back(Wind);
vector <vector <string> > remain_state;
for(unsigned int i = 0; i < state.size(); i++){
remain_state.push_back(state[i]);
}
ComputeMapFrom2DVector();
root = BulidDecisionTreeDFS(root,remain_state,remain_attribute);
cout<<"the decision tree is :"<<endl;
PrintTree(root,0);
FreeTree(root);
cout<<endl;
cout<<"tree_size:"<<tree_size<<endl;
return 0;
}














 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









