







 本文介绍了K-means算法的基本概念,包括模型、损失函数和迭代策略,并详细解释了算法的迭代过程。K-means是一种无监督学习模型,通过最小化簇内点与中心点的距离平方和来寻找聚类中心。最后,文章提供了Python程序实现K-means算法的步骤。
本文介绍了K-means算法的基本概念,包括模型、损失函数和迭代策略,并详细解释了算法的迭代过程。K-means是一种无监督学习模型,通过最小化簇内点与中心点的距离平方和来寻找聚类中心。最后,文章提供了Python程序实现K-means算法的步骤。
一.算法介绍
1.模型
K-means算法并没有显式的数学模型,算法的目的是从数据集中得到k个中心点,每个中心点及其周围的点形成一个聚簇。K-means是一种无监督的学习模型。K-means的学习目标如下图所示:

2.策略
K-mean算法采用的损失函数是平方损失函数。每个簇的点距离中心的平方距离之和构成损失函数。
3.算法
首先给出原始数据{x1,x2,…,xn},这些数据没有被标记的。
初始化k个随机数据u1,u2,…,uk作为初始的聚类中心。这些xn和uk都是向量。
根据下面两个公式迭代就能求出最终所有的u,这些u就是最终所有类的中心位置。
公式一:
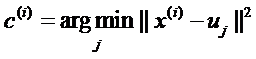
意思就是,对于每个数据点,都先求出其与当前所有聚簇中心的距离,然后把该点归到距离最近的那个中心所代表的簇。
公式二:
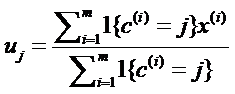
意思就是,在第一轮对所有数据点分配好了聚簇归属之后。针对每个簇,求解当前簇中所有数据点的中心,把这个中心数据点再作为新的聚簇中心。
然后不断迭代两个公式,直到所有的u都不怎么变化了,就算完成了。
K-means的这种求法可视为是一种启发式的算法,其最后的结果还是可能会收敛到局部最优值。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









