







5.1.6 Automatic Tracking of Surgical Instruments with a Continuum Laparoscope Using Data-Driven Control in Robotic Surgery
Key Words: Surgical video analysis, Unsupervised video retrieval, Disentangled representation, Learning-based hashing
Authors: Ziyi Wang, Bo Lu, Xiaojie Gao, Yueming Jin, Zerui Wang, Tak Hong Cheung, Pheng Ann Heng, Qi Dou, Yunhui Liu
Source: Medical Image Analysis 75 (2022) 102296

摘要: 本文提出了一种新颖的无监督场景和动作解缠(UDSM)方法,用于大型数据库中的微创手术视频检索,有望推动智能高效的外科教学系统的发展。 为了提取更具辨别力的视频表示,我们设计了两个编码器,分别使用三元排名损失和对抗学习机制,分别捕捉空间和时间信息,以实现从每帧中获得具有良好可解释性的解缠特征。 此外,通过时间聚合模块改进了整合视频层面上的长程时间依赖性,然后生成一组紧凑的二进制码,携带代表性特征,实现快速检索。整个框架在无监督方案中进行训练,即纯粹从原始外科手术视频中学习,不使用任何注释。 构建了两个大规模的微创手术视频数据集,基于公共数据集Cholec80和我们的内部腹腔镜子宫切除数据集,以建立学习过程,并在外科手术视频检索任务上定性和定量验证提出的方法的有效性。 大量实验证明,方法在两个数据集上明显优于最先进的视频检索方法,展示了在下一代外科教学系统中注入智能的有希望的未来。
背景
计算机辅助手术已成为现代手术室中广泛采用的范式,使外科医生能够在微创手术中进行复杂的操作。在微创手术中进行复杂的操作。如今,对于微创手术技能培训,学徒制是培养外科专家的标准模式。 初级外科医生和学生需要通过观察经验丰富的高级外科医生进行的整个或重要的外科手术过程,从现场手术操作中学习,或从传统的外科视频中学习来培养他们的熟练程度。 最近,设计了各种类型的外科教学系统来协助外科医生进行离线操作。
为了开发这样的教学系统,外科手术录像被视为术前培训和术中指导的有力工具,在其中,旧视频可以作为参考并投影在外科医生面前的屏幕上,提供专业演示并进一步提高他们在微创手术中的表现。考虑以下场景:当向新手解释特定的外科手术过程时,例如子宫切除术中切割子宫韧带,应该从数据库中挑选出包含此指定动作的类似视频。 然而,目前最大的困境在于手动从大量外科手术录像中选择所需片段所花费的时间,这导致系统实施的低效率。为了解决这个问题,然而,对于手术视频检索,迫切需要方法,但目前非常有限。Schoeffmann等人提出了一种名为运动强度和方向描述符(MIDD)的视频内容描述符,用于检索MIS视频片段。Chittajallu等人使用预训练的3D卷积神经网络(CNN)模型提取视频特征,并采用迭代查询优化(IQR)策略与用户反馈一起迭代地优化搜索结果。 然而,这些依赖手工特征或在线反馈的方法无法提取代表性的视觉特征和实现高效的检索。对于手术视频检索任务,大量的视频数据带来了处理和分析的困难,标记手术视频耗时且需要特定领域的知识或专业技能。 此外,如何正确高效地处理这些视频信息是一个重要问题。 针对这些挑战,无监督的基于哈希的检索方法是一种有前景的解决方案,已经在自然数据集上广泛研究用于图像和视频检索任务。 早期的图像检索哈希算法主要关注哈希函数优化或量化损失最小化以提高检索性能。 在这些传统方法之上,基于深度学习的哈希方法在哈希领域取得了巨大进展。
Song等人提出了自监督视频哈希(SSVH)方法,其中精心设计了一个分层长短期记忆(LSTM)网络来建模时间依赖关系(Song等人,2018)。最近,Li等人提出了一种保持邻域的哈希(NPH)方法,在自然无监督视频检索任务上取得了最先进的性能。通过将邻域注意机制整合到基于RNN的重构方案中,它可以捕捉视频中的时空结构(Li等人,2019)。
尽管上述无监督哈希方法成功地将时间信息嵌入模型中,但它们并没有明确地研究空间和时间通道中的特征,这可以为可变视频检索中的场景或动作子空间相似性提供一种控制手段。
为了充分利用外观和时间信息并开发更可解释的网络,研究人员最近研究了将视频属性分配到空间特征和时间特征中,并成功应用于几个任务,如双流网络,时间段网络(TSN),分组空间-时间聚合(GST),SlowFast网络等等。对于无监督的分解表示学习,Denton等和Tulyakov等提出了通过生成对抗网络学习分解的运动和内容特征的方法。Hsieh等设计了基于变分自动编码器的DDPAE方法,用于分解表示和视频组件。 与这些无监督方法不同,这些方法侧重于学习和分解视频序列中的视觉特征,如何分析视频之间的区别对于视频检索任务还需要进一步探索。
Methodology
提出的用于MIS视频检索的无监督特征解缠框架的概述如图3所示。具体而言,每帧的场景特征和运动特征通过两个解码器进行解缠,采用设计的三元组排序损失和对抗学习机制,然后组合和转换为二进制码进行帧重建和特征增强。 此外,为了进一步融入帧之间的长程依赖关系并为整个视频剪辑生成二进制码,设计了一个具有解缠特征序列输入的时间聚合模块。
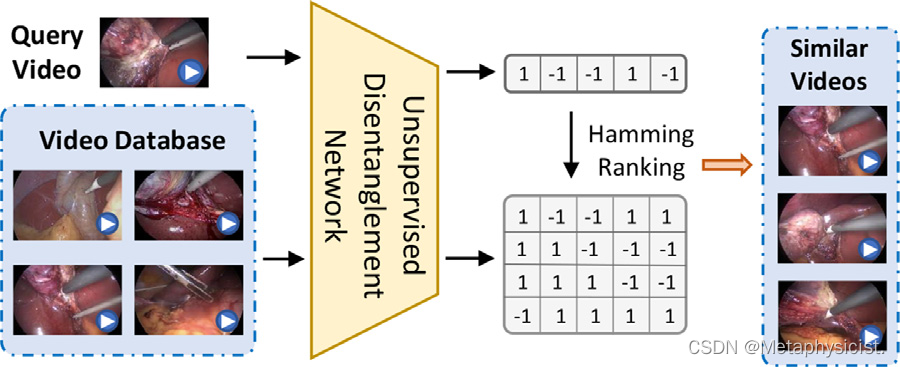
图1. 提出的无监督分解场景和运动(UDSM)网络对外科手术视频检索进行了说明。查询视频和整个视频数据库被输入到网络中,生成每个视频的二进制码,通过计算汉明距离来衡量相似性和排序。
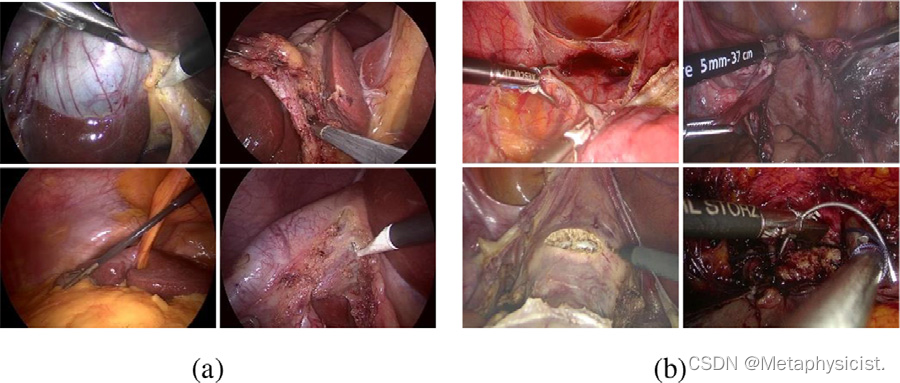
图2. 采用的(a)公共Cholec80数据集和(b)内部数据集的视频外观示例。
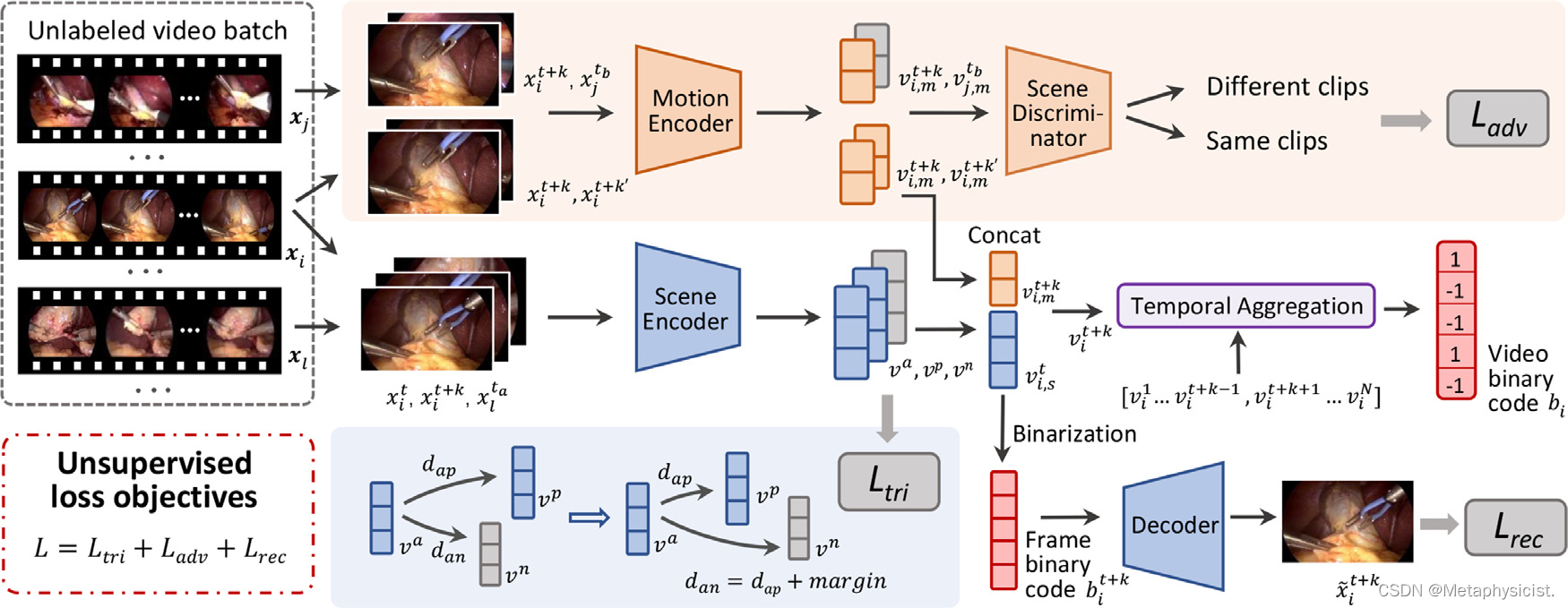
图3. 手术视频检索中提出的无监督场景和运动特征解缠模型的概述。开发了两个编码器,分别提取和解缠场景和运动特征,并设计了三元组排序损失和对抗学习机制。. 然后,解缠的场景和运动特征被合并和转换为帧级二进制码,这是输入到解码器的输入,用于重建帧并产生重建损失。此外,为了进一步整合整个视频剪辑的长程依赖关系,设计了一个时间聚合模块,通过输入一组帧特征到一个剪辑中,并生成视频级二进制码,最终用于检索。
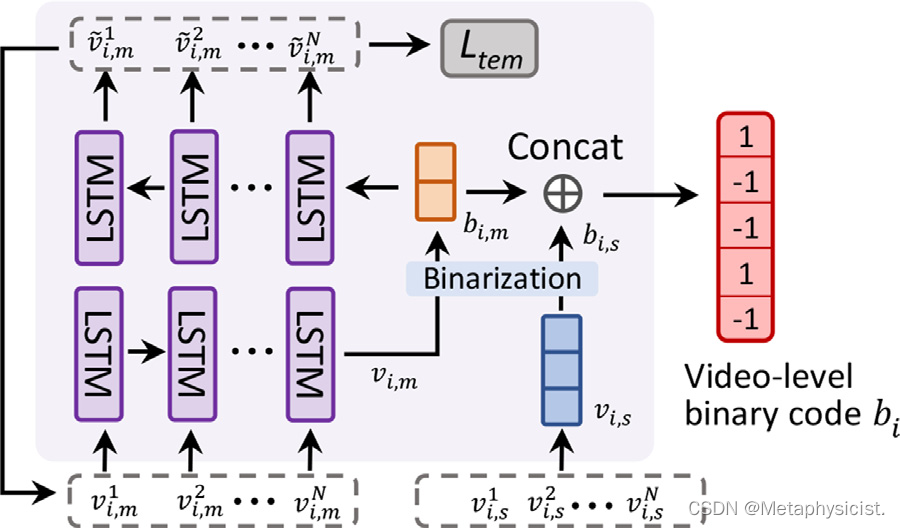
图4. 时间聚合模块的示意图。 该模块的输入是剪辑中所有帧的解缠场景和运动特征序列,它生成一个具有长程依赖的表达性视频级二进制码来表示每个剪辑。
A. 无监督解缠学习
无监督特征解缠模型,分别提取视频片段中的场景特征和动作特征。首先通过设计一个模块来学习未标记视频的场景特征,通过捕捉相似性信息并保留它们之间的相似性顺序。 在短视频片段中,可以合理地假设同一片段中的主要场景信息几乎是一致的。 相反,不同视频片段中的帧在外观上差异很大。 因此,可以确信同一片段中帧的特征向量之间的距离要远小于不同片段中的帧。 基于此,开发了一个三元组网络,以学习输入帧的更具辨别力的场景表示,并进一步实现更好的场景特征分离。
B. 通过对抗损失进行运动特征嵌入
从每个帧中的运动特征中观察到整个视频的动态信息。 换句话说,帧级运动特征(即图像中倾向于移动或改变的部分)可以被视为特定帧上视频运动模式的表现,而不同于场景特征(即操作环境和仪器的外观),后者在剪辑中几乎保持一致。 因此,开发了一个运动编码器 Em,其学习策略是专注于提取动态信息的潜在表示,而不关心场景信息。 在运动编码器 Em和场景鉴别器 Ds之间设计了一种对抗学习机制,用于判断运动特征是否包含场景信息。
通过设计的对抗学习机制,当场景鉴别器无法从Em提取的特征中捕捉到同一剪辑内帧对的场景相似性时,可以说运动编码器成功地通过过滤场景信息提取了时间动态。 这意味着,例如,剪辑和切割阶段的运动特征不应包含有关手术场景中组织背景的任何信息,而应强调执行动作的工具运动。 因此,运动编码器 Em被训练为最大化鉴别器对于这些对的输出熵。
C. 通过重构损失进行特征增强
为了获得更强大的帧特征,利用解缠的场景和运动表示通过重构原始帧,并学习一个更具区分性的用于检索的二进制码。运动特征被连接到场景特征上,形成一个帧级特征。
进一步构建一个解码器 Dr来通过循环一致性正则化重构帧。 在这种情况下,场景编码器和运动编码器都得到增强,以获得更具代表性的帧特征,可以携带足够的帧信息。
整个模型(包括属性编码器 {Es, Em},场景判别器 Ds和重构解码器Dr)在建立的数据集上以无监督的方式进行训练,不使用任何视频剪辑的注释。 通过这种方式,获得了用于帧级特征和二进制码生成的解耦场景和运动特征。 生成的码明确地结合了场景的空间信息和运动的时间信息,具有良好的可解释性。
D. 具有长程依赖性的视频级哈希
尽管从上述无监督的场景和运动特征解耦中获得的二进制码能够高质量地表示每个单帧的信息,但如何在更综合的视频层面上生成哈希码仍然需要解决。 一个重要问题是加强基于运动的表示,以捕捉整个视频帧序列的长程依赖性。 在这方面,进一步开发了一个时间聚合模块,如图4所示,该模块输入剪辑中所有帧的场景和运动特征序列,并学习生成一个具有长程依赖性的表达性视频级二进制码来表示剪辑。 具体而言,对于输入的场景特征 ,提出使用平均场景特征生成一个稳健的视频级场景特征表示,然后将其映射为一组二进制码。 对于运动模式建模,设计了基于LSTM的自编码器,其中运动特征序列是LSTM编码器的输入。编码器的最后一个单元的输出被视为携带剪辑中所有时间信息的增强运动表示。 然后, 二值化,不仅用于输入运动特征重构,还用于最终检索。LSTM模块通过使用均方误差(MSE)计算的时间重构损失
L
t
e
m
L_{tem}
Ltem进行自监督训练。最后,整个剪辑的二进制码通过连接场景和动作码获得。
总之,整个模型可以被视为一个哈希函数,以无监督的方式将原始视频剪辑转换为高质量的哈希码,同时还能保持在汉明空间中的距离顺序。 采用哈希码排序方法,通过XOR操作计算汉明距离,然后根据查询视频与数据库中所有视频之间的距离进行排序。
E. 训练过程和实现细节
提出的UDSM网络的训练过程总结如算法1所示。 整个模型分为两个步骤进行训练。

第一步是训练无监督的解缠模型。
对于每个训练迭代,构建一个三元组集和两对帧,对于每个视频剪辑,然后将其馈送到相应的模块中,以训练场景编码器 Es,运动编码器Em,场景鉴别器 Ds和解码器 Dr。 然后,时间模块被训练以学习长程依赖性,并使用第一步中经过良好训练的编码器提取的输入特征序列生成视频级二进制码。
实验
为了评估提出的UDSM模型,将其与三种检索方法在两个数据集上进行比较:1)基于CNN的模型,使用在帧级特征上进行均值池化得到的视频级特征,这些特征是由预训练的VGG网络生成的。
在重新组织的Cholec80数据集(D1)和内部数据集(D2)上评估使用256位二进制码进行检索的mAP@K结果和时间成本,比较了基于CNN的、NPH、SSVH和提出的UDSM方法。
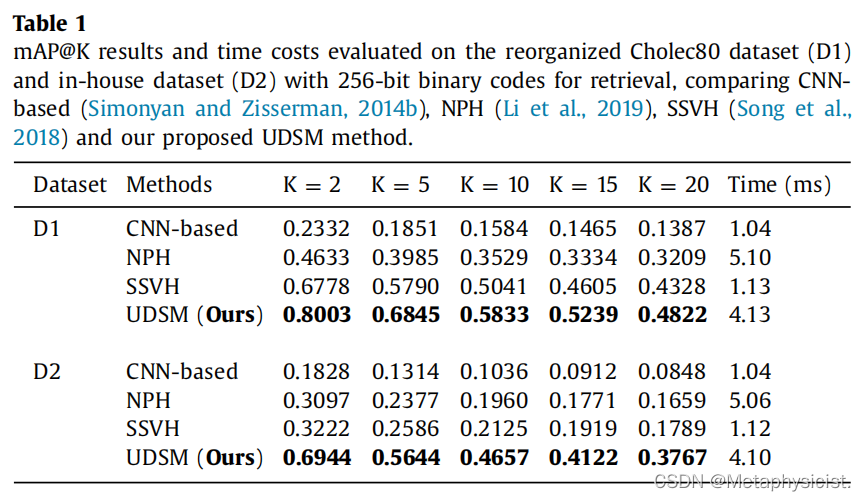
并利用层次二进制自编码器或邻域保持策略进行模型设计,以便在重新组织的Cholec80数据集上与基于CNN的模型相比具有更好的性能。 然而,在对内部数据集进行测试时,上述两种方法都没有取得令人满意的结果。 与胆囊切除术的视频数据相比,子宫切除术的视频数据在不同阶段之间具有类似的外观,导致训练中邻域相关场景的效用较弱。 子宫切除术数据的固有复杂性导致了表1、数据集2中列出的结果。 值得注意的是,UDSM模型通过利用设计的适当损失准确提取的具有区分性的场景和动作特征,在两个数据集上都取得了显著的改进。 此外,值得注意的是,模型在K相对较小的情况下表现出优越的性能,这适用于实施到外科教学系统中,因为即时相关的几个剪辑的精确性主导重要。
此外,由于手术视频检索中的效率也是一个重要问题,使用1个NVIDIA TITAN XP GPU评估和计算了所有方法的时间成本,并将结果列在表1中。 值得注意的是,对于提出的方法,平均只需要约4毫秒来获取一个查询的排名列表,这表明模型可以实现实时视频检索,并有望在手术教学系统中得到应用于手术技能培训。
此外,还针对两个数据集进行了三种相似度度量的实验,并在前20个检索到的剪辑上绘制了结合了VGG余弦相似度、SSIM和PSNR的平均相似度得分,如图5所示。 可以注意到,UDSM方法在所有方面都明显优于这三种比较方法,并且性能随着检索视频索引k的增加而合理地呈现下降趋势,这证明了架构的可靠性。定性结果在图6中呈现,其中从不同数据集中选择了两个视频作为查询视频,并使用不同的方法提供了前5个检索结果作为视觉示例。 直观地注意到模型在检索视频的准确性和外观相似性方面都具有更高的性能。
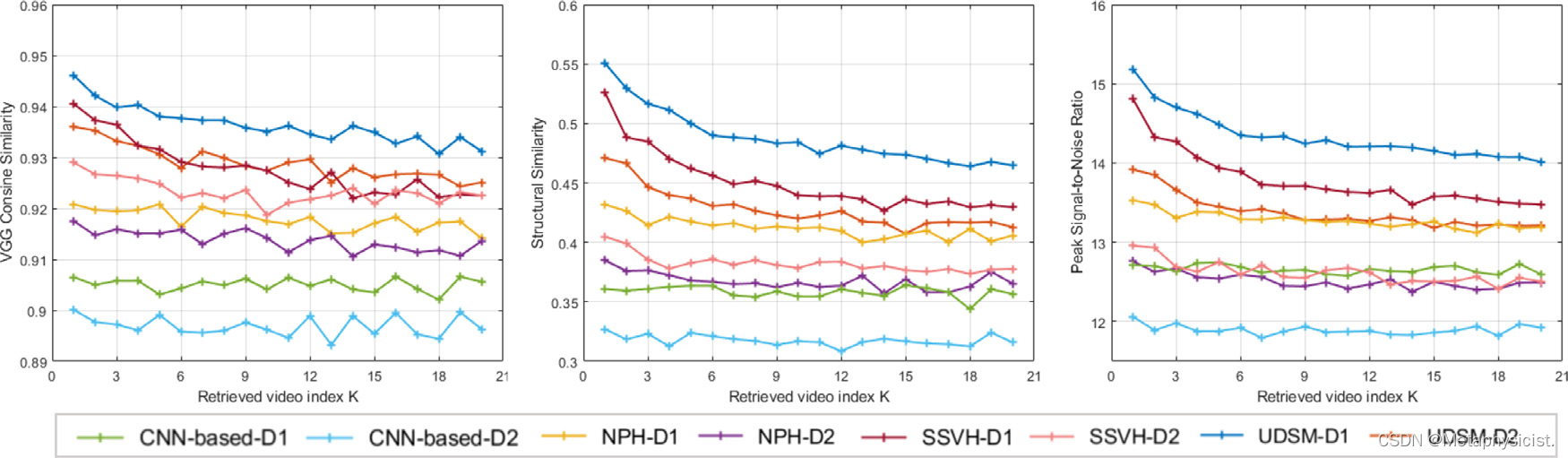
图5. 在重新组织的Cholec80数据集(D1)和内部数据集(D2)上,使用三种逐帧相似性评估指标(VGG余弦相似度、SSIM和PSNR)对CNN-based方法、NPH、SSVH和UDSM方法进行定量结果比较。. 在三个指标中,较高的分数都表示更好的性能。
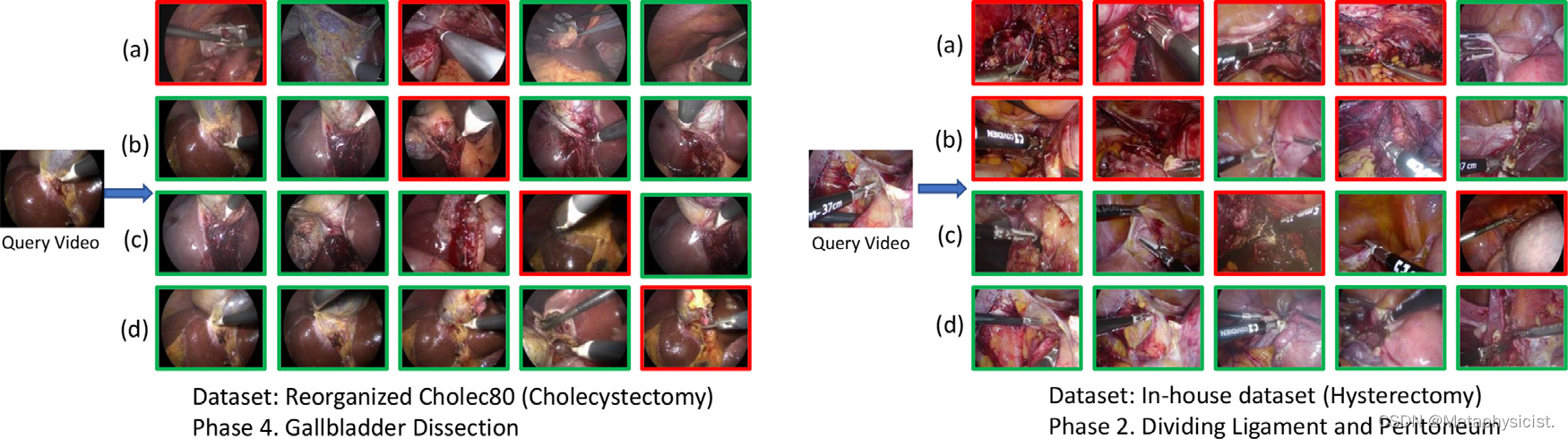
图6. 使用256位二进制码的前5个检索结果,使用(a)基于CNN的方法 (b) NPH © SSVH (d)UDSM方法。 左侧:重新组织的Cholec80数据集中的典型查询视频和检索到的视频。 右侧:内部数据集中的典型查询视频和检索到的视频。 正确和错误的结果分别用绿色和红色边框标注。
表2. 提出的UDSM模型在重新组织的Cholec80数据集上的mAP@K结果。
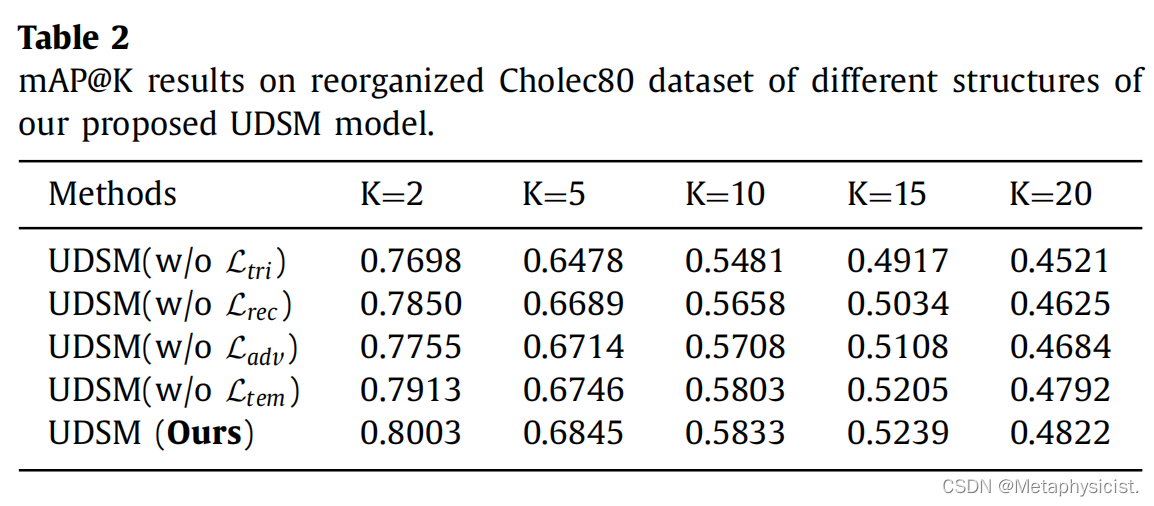
表3. 每个手术阶段在重新组织的Cholec80数据集上的训练视频剪辑数量和mAP@K检索结果。
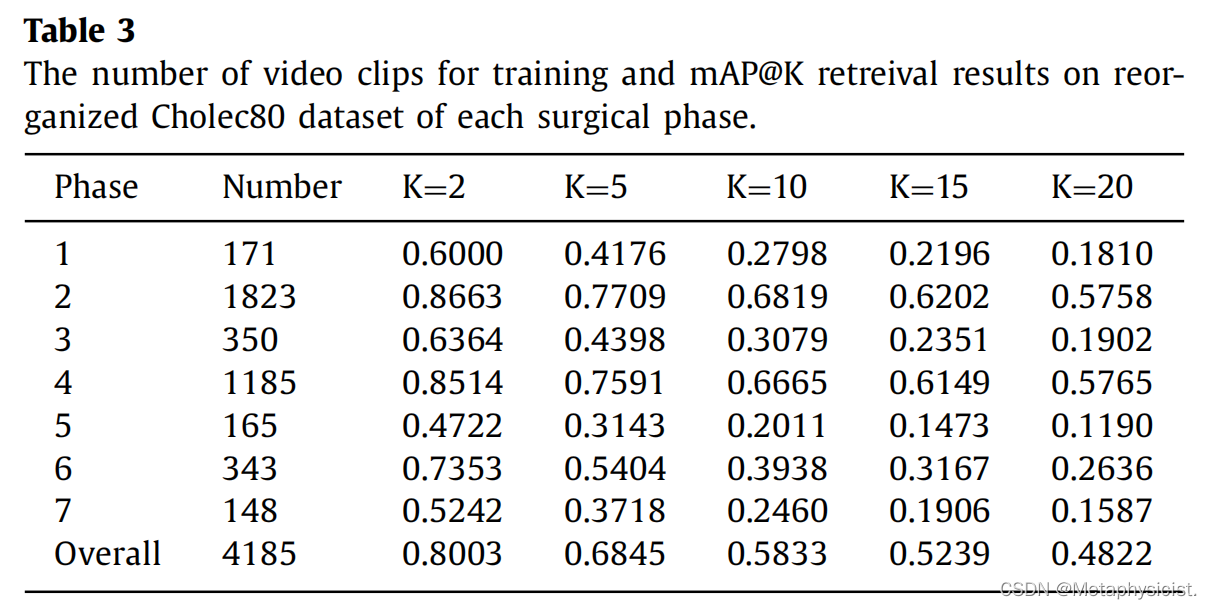
表4. 在重新组织的Cholec80数据集上,不同长度的视频剪辑(即20、60和120秒)的mAP@K结果。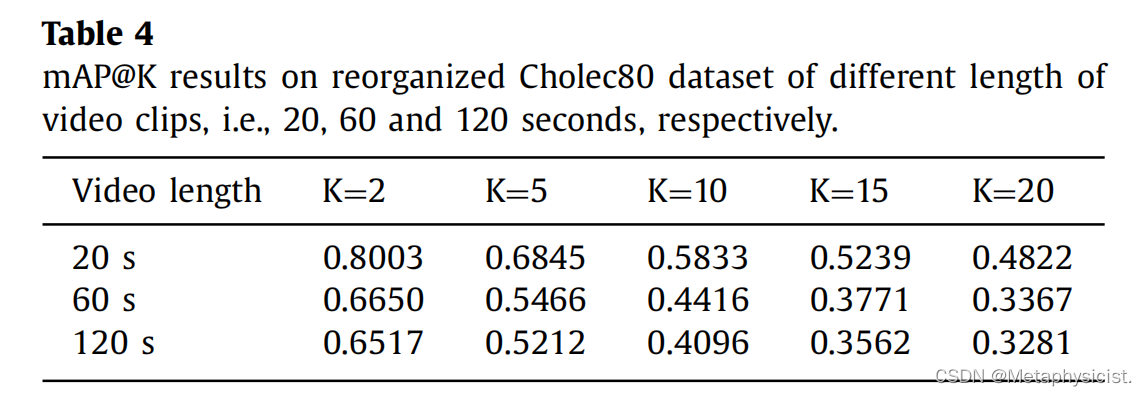
表5. 在重新组织的Cholec80数据集上,不同长度的二进制编码的mAP@K结果和平均时间成本如下。
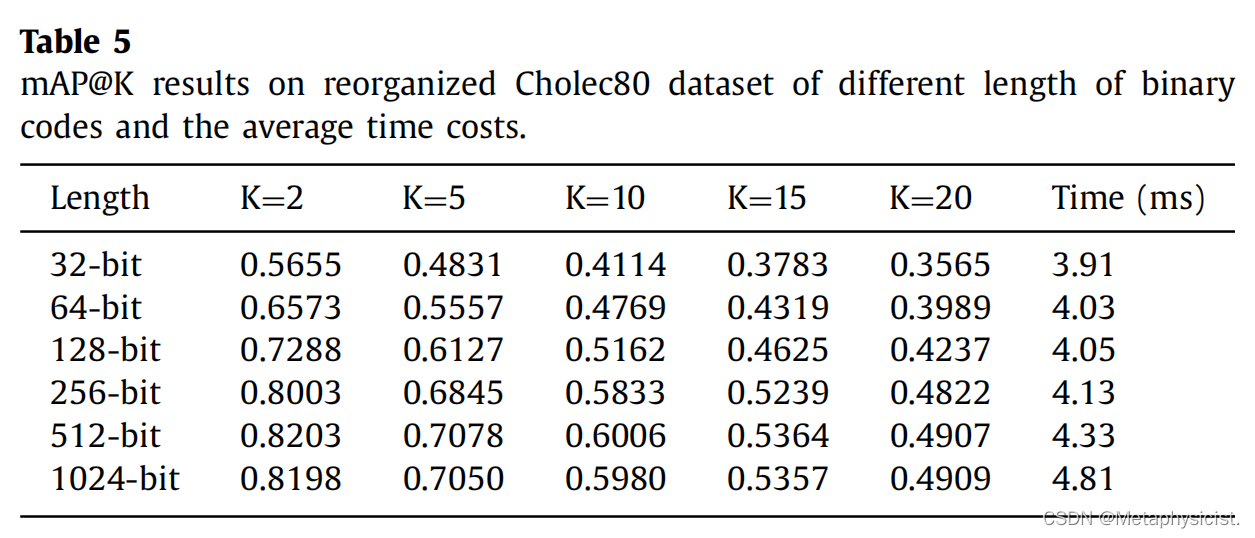
表6. 使用256位二进制代码,对不同场景和动作(s/m)特征长度比例在重新组织的Cholec80数据集上进行mAP@K结果评估。
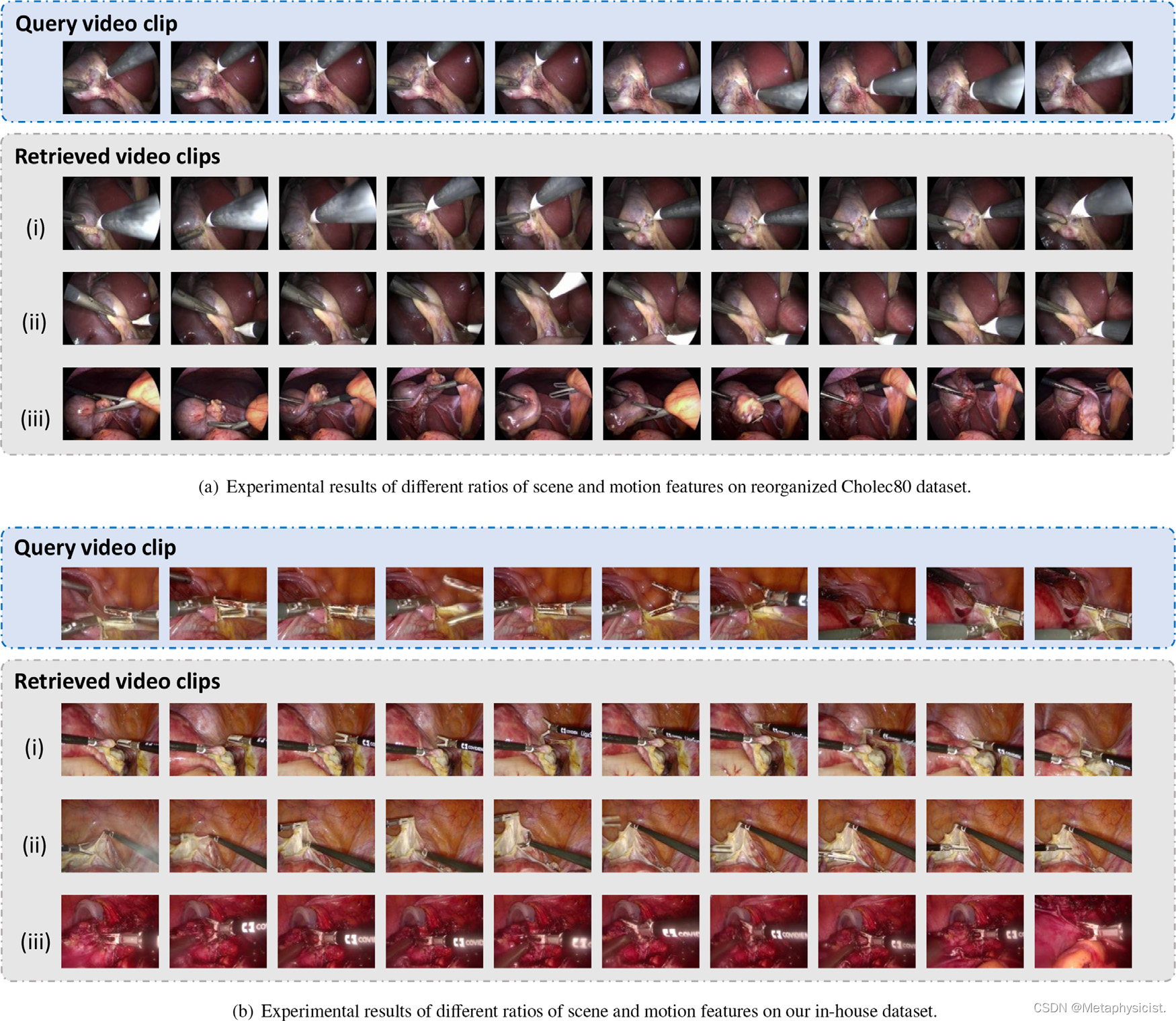
图7. 基于场景和动作特征之间不同代码长度比例的外科手术视频检索的定性结果,分别基于重新组织的Cholec80数据集和我们的内部数据集。场景/动作特征比例设置为:(i) 7:1 (ii) 1:1 (iii) 1:7。 每行代表一个20秒的视频片段,每个片段中均均匀选择10帧以便清晰观察。
不足与展望
我们的工作的局限性在于我们使用每个剪辑的相位信息进行定量评估,遵循常用的评估指标,根据自然视频检索任务中的类别标签。 手术阶段注释最初是为手术工作流识别任务设计的,但我们的检索任务旨在搜索与查询视频在语义上最相似的剪辑,因此超出了视频分类。 因此,我们使用这种评估指标,基于合理的假设,即属于相同阶段的剪辑在外观和时间模式方面具有相似的信息,而不同阶段的信息则较不相似。此外,在本文中,为了弥补上述不足的指标并对我们的方法进行详细观察,我们还提供了图像相似性的定量结果和检索视频的定性结果。 在未来的工作中,我们将通过设计更全面的注释和评估指标来增强数据集,以进行细粒度的手术视频检索。
Reference
[1] Wang, Z., Lu, B., Gao, X., Jin, Y., Wang, Z., Cheung, T. H., … & Liu, Y. (2022). Unsupervised feature disentanglement for video retrieval in minimally invasive surgery. Medical Image Analysis, 75, 102296.
















 1990
1990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











