









在软件开发的不同阶段,测试工程师需要利用各种测试工具来确保代码的质量和性能。本文将介绍一些主流的软件测试工具,它们适合的测试类型,以及基本的使用方法和操作流程。
1. Selenium:自动化Web测试
Web自动化测试是现代软件开发过程中至关重要的一环。Selenium是一个强大的自动化测试工具,可以模拟用户在Web浏览器中的操作,实现自动化的测试流程。本文将介绍如何使用Selenium进行Web自动化测试,并附带代码示例,帮助读者快速上手。
- 环境准备
在开始之前,需要安装Selenium库和Web浏览器驱动程序。可以通过命令行来安装Selenium:
pip install selenium
另外,还需要下载对应浏览器的驱动程序。不同浏览器的驱动程序下载地址如下:
Chrome:https://sites.google.com/a/chromium.org/chromedriver/downloads
Firefox:https://github.com/mozilla/geckodriver/releases
Edge:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
Safari:https://webkit.org/blog/6900/webdriver-support-in-safari-10/
选择适合自己的浏览器驱动程序下载并保存在本地。
- 常见API详解
#防止乱码
#coding = utf-8
#想使用selenium的webdriver里面的函数,首先需要把包导进来
from selenium import webdriver
import time
#我们需要操作的浏览器,这里使用的是谷歌浏览器,也可以是IE、Firefox
driver =webdriver.Chrome()
#访问百度首页
driver.get('http://www.baidu.com')
#停3秒钟
time.sleep(3)
#百度输入框的id为kw,我们需要在输入框中输入Selenium,用send_keys进行输入
driver.find_element_by_id("kw").send_keys("Selenium")
time.sleep(3)
#百度搜索框按钮id叫su,找到后调用click函数模拟点击操作
#和click有相同效果的是submit(),都可以用来点击按钮,submit主要是用于提交表单
driver.find_element_by_id("su").click()
time.sleep(3)
#退出并关闭窗口的每一个相关的驱动程序
driver.quit()
注意:关闭窗口主要有两种方法,分别是close和quit。close是关闭当前浏览器窗口,quit不仅关闭窗口,还会彻底的退出webdriver,释放driver server之间的连接,所以quit的关闭比close更彻底,它会更好的释放资源。
元素的定位
对页面元素进行定位是自动化测试的核心,我们要想操作一个对象,首先应该识别这个对象。在一个页面中,每个对象属性是唯一的我们需要用一系列的方式去定位我们要操作的对象。WebDriver提供了以下几种方法定位元素:
- id
- name
- class name
- link text
- partial link text
- tag name
- xpath
- css selector
下面我将对每种定位方法进行举例。
#coding = utf-8
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
######################百度输入框的定位方式#################
#通过id定位
driver.find_element_by_id("kw").send_keys("selenium")
#通过name定位
driver.find_element_by_name("wd").send_keys(u"CSDN博客") #u表示以utf-8的格式输入
#通过tag name定位
driver.find_element_by_tag_name("input").send_keys("Python") #不能成功,因为input在这个页面有多个不唯一,无法定位到底是哪一个
#通过class name定位
driver.find_element_by_class_name("s_ipt").send_keys("Java")
#通过CSS定位
driver.find_element_by_css_selector("#kw").send_keys("C++")
#通过xpath定位
driver.find_element_by_xpath("//*[@id=kw]").send_keys(u"C语言")
#通过link test定位
driver.find_element_by_link_text("hao123").click()
#通过partial link test定位
driver.find_element_by_partial_link_text("hao").click()
driver.find_element_by_id("su").click()
time.sleep(3)
driver.quit()
智能等待
前面说过等待可以引入time包,从而在脚本中自由的添加休眠时间 。但是有时候我们不想等待一个固定的时间,于是可以通过implicitly_wait()方法方便的实现智能等待,它在一个时间范围内智能等待。
selenium.webdriver.remote.webdriver.implicitly_wait(time_to_wait)隐式等待一个元素被发现或一个命令完成,这个方法每次会话只需要调用一次time_to_wait
具体用法:
# coding = utf-8
from selenium import webdriver
import time #调入time 函数
browser = webdriver.Chrome()
browser.get("http://www.baidu.com")
browser.implicitly_wait(30) #智能等待30秒
browser.find_element_by_id("kw").send_keys("selenium")
browser.find_element_by_id("su").click()
browser.quit()
打印信息
使用print打印title和URL
#coding = utf-8
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
print driver.title # 把页面title 打印出来
print driver.current_url #打印url
driver.quit()
浏览器的操作
浏览器的最大化
调用启动的浏览器不是全屏的,这样虽然不影响脚本的执行,但有时会影响我们观看脚本执行的变化。使用maximize_window()
#coding=utf-8
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get("http://www.baidu.com")
print "浏览器最大化"
browser.maximize_window() #将浏览器最大化显示
time.sleep(2)
browser.find_element_by_id("kw").send_keys("selenium")
browser.find_element_by_id("su").click()
time.sleep(3)
browser.quit()
设置浏览器的宽高
最大化不够灵活,所以我们可以随意的设置浏览页面的宽高,使用set_window_size(宽,高)
#coding=utf-8
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get("http://www.baidu.com")
time.sleep(2)
#参数数字为像素点
print "设置浏览器宽480、高800显示"
browser.set_window_size(480, 800)
time.sleep(3)
browser.quit()
浏览器的前进、后退
我们也可以实现浏览器的前进和后退
#coding=utf-8
from selenium import webdriver
import time
browser = webdriver.Chrome()
#访问百度首页
first_url= 'http://www.baidu.com'
print "now access %s" %(first_url)
browser.get(first_url)
time.sleep(2)
#访问新闻页面
second_url='http://news.baidu.com'
print "now access %s" %(second_url)
browser.get(second_url)
time.sleep(2)
#返回(后退)到百度首页
print "back to %s "%(first_url)
browser.back()
time.sleep(1)
#前进到新闻页
print "forward to %s"%(second_url)
browser.forward()
time.sleep(2)
browser.quit()
控制浏览器滚动条
#coding=utf-8
from selenium import webdriver
import time
#访问百度
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
#搜索
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
time.sleep(3)
#将页面滚动条拖到底部
js="var q=document.documentElement.scrollTop=10000"
driver.execute_script(js)
time.sleep(3)
#将滚动条移动到页面的顶部
js="var q=document.documentElement.scrollTop=0"
driver.execute_script(js)
time.sleep(3)
driver.quit()
#excute_script(script,*args),在当前窗口同步执行JavaScript
键盘事件
键盘键用法
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys #需要引入keys 包
import os,time
driver = webdriver.Chrome()
driver.get("http://demo.zentao.net/user-login-Lw==.html")
time.sleep(3)
driver.maximize_window() # 浏览器全屏显示
driver.find_element_by_id("account").clear()
time.sleep(3)
driver.find_element_by_id("account").send_keys("demo")
time.sleep(3)
#tab 的定位相当于清除了密码框的默认提示信息,等同上面的clear()
driver.find_element_by_id("account").send_keys(Keys.TAB)
time.sleep(3)
#通过定位密码框,enter(回车)来代替登陆按钮
driver.find_element_by_name("password").send_keys(Keys.ENTER)
time.sleep(3)
driver.quit()
键盘组合键用法
实现Ctrl+a,Ctrl+x
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
#输入框输入内容
driver.find_element_by_id("kw").send_keys("selenium")
time.sleep(3)
#ctrl+a 全选输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'a')
time.sleep(3)
#ctrl+x 剪切输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'x')
time.sleep(3)
#输入框重新输入内容,搜索
driver.find_element_by_id("kw").send_keys("webdriver")
driver.find_element_by_id("su").click()
time.sleep(3)
driver.quit()
鼠标事件
操作鼠标需要使用到ActionChains类
- context_click()右击
- double_click()双击
- drag_and_drop()拖动
- move_to_element()移动
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import time
driver = webdriver.Chrome()
driver.get("http://news.baidu.com")
qqq =driver.find_element_by_xpath(".//*[@id='s_btn_wr']")
ActionChains(driver).context_click(qqq).perform() #右键
ActionChains(driver).double_click(qqq).perform() #双击
#定位元素的原位置
element = driver.find_element_by_id("s_btn_wr")
#定位元素要移动到的目标位置
target = driver.find_element_by_class_name("btn")
#执行元素的移动操作
ActionChains(driver).drag_and_drop(element, target).perform()
#ActionChains(driver)生成用户的行为。所有的行动都存储在actionchains 对象。通过perform()存储的行为。
#move_to_element(menu)移动鼠标到一个元素中,menu 上面已经定义了他所指向的哪一个元素
#perform()执行所有存储的行为
多层框架/窗口定位
- switch_to_frame()多层框架定位
- switch_to_window() 多窗口定位
switch_to_frame()的功能是把当前定位的主体切换到frame里,即frame中实际上嵌入了另一个页面,而webdriver每次只能在一个页面识别,因此才需要用switch_to_frame方法去获取frame中嵌入的页面,对那个页面里的元素进行定位。
switch_to _default_content:从frame中嵌入的页面跳出,跳回到最外面的原始页面中。
#coding=utf-8
from selenium import webdriver
import time
import os
browser = webdriver.Chrome()
file_path = 'file:///' + os.path.abspath('D:\\Users\\320S-15\\seleniumTestHTML\\frame.html')
browser.get(file_path)
browser.implicitly_wait(30)
#先找到到ifrome1(id = f1)
browser.switch_to_frame("f1")
#再找到其下面的ifrome2(id =f2)
browser.switch_to_frame("f2")
#下面就可以正常的操作元素了
browser.find_element_by_id("kw").send_keys("selenium")
browser.find_element_by_id("su").click()
time.sleep(3)
browser.quit()
多层窗口定位:switch_to_window用法与switch_to_frame相同,如:driver.switch_to_window(“windowname”)
层级定位
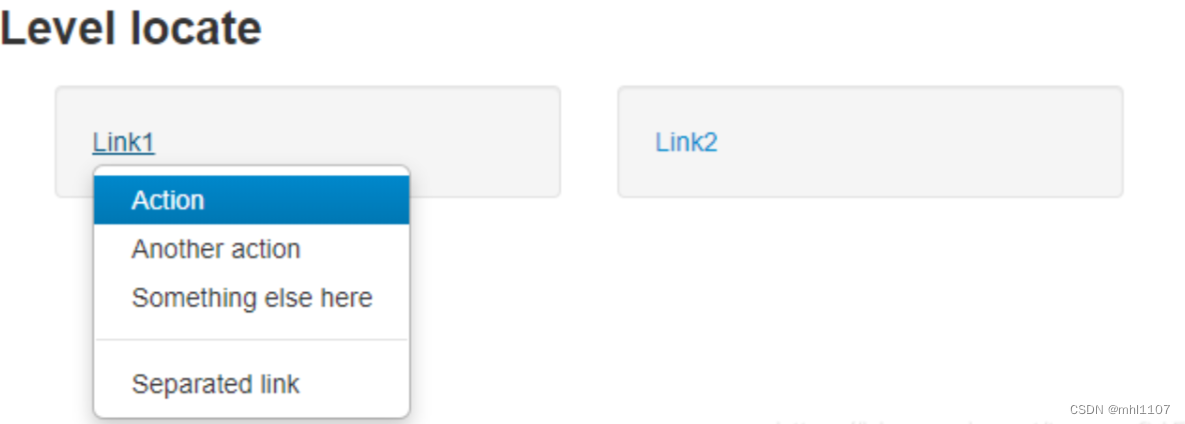
对于这种定位的思路是:先点击显示出1个下拉菜单,然后再定位该下拉菜单所在的ul,再定位这个ul下的某个具体的link,如果要定位第一个下拉菜单中的Action选项:
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
import time
import os
dr = webdriver.Chrome()
file_path = 'file:///' + os.path.abspath('D:\\Users\\320S-15\\seleniumTestHTML\\level_locate.html')
dr.get(file_path)
#点击Link1链接(弹出下拉列表)
dr.find_element_by_link_text('Link1').click()
#找到id为dropdown1的父元素
WebDriverWait(dr,10).until(lambda the_driver:#10秒内每隔500毫秒扫描1次页面变化,当出现指定的元素结束
the_driver.find_element_by_id('dropdown1').is_displayed())#is_displayed()表示是否用户可见
#在父亲元件下找到link 为Action 的子元素
menu = dr.find_element_by_id('dropdown1').find_element_by_link_text('Action')
#鼠标定位到子元素上
webdriver.ActionChains(dr).move_to_element(menu).perform()
time.sleep(2)
dr.quit()
下拉框处理
对于下拉框里的内容我们需要两次定位,先定位到下拉框,再定位到下拉框内的选项
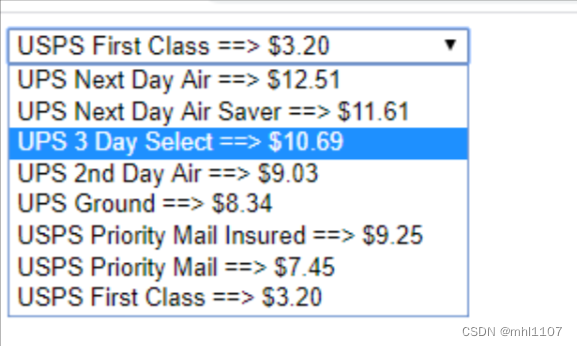
#coding=utf-8
from selenium import webdriver
import os,time
driver= webdriver.Chrome()
file_path = 'file:///' + os.path.abspath('D:\\Users\\320S-15\\seleniumTestHTML\\drop_down.html')
driver.get(file_path)
time.sleep(2)
#先定位到下拉框
m=driver.find_element_by_id("ShippingMethod")
#再点击下拉框下的选项
m.find_element_by_xpath("//option[@value='10.69']").click()
time.sleep(3)
driver.quit()















 3475
3475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









