



ACM国际多媒体会议(ACM International Conference on Multimedia,简称ACM MM)是由美国计算机协会(ACM)主办的国际多媒体领域顶级盛会,也是中国计算机学会(CCF)推荐的A类会议。该会议始于1993年,每年举办一次。会议专注于多媒体技术领域的最新研究成果、技术创新和行业趋势,涵盖多媒体内容的创建、处理、传输和交互等多个方面,旨在促进学术界和工业界在多媒体技术应用和产品开发方面的交流与合作。

2025年的第33届会议于10月27日至31日在爱尔兰都柏林举行,总计收到有效投稿4711篇,最终成功录用1251篇,录用率达26.6%。与前一年相比,录用率有所上升,但总体而言仍维持在较为稳定的水平,对于广大作者来说,该会议依旧值得投稿。
| 年份 | 投稿量 | 录取量 | 录取率 |
|---|---|---|---|
| 2025 | 4711 | 1251篇 | 26.6% |
| 2024 | 4385 | 1149篇 | 26.20% |
| 2023 | 3072 | 902篇 | 29.40% |
| 2022 | 2473 | 690篇 | 27.90% |
| 2021 | 1942 | 542篇 | 27.90% |
会议热门方向有大规模图像视频分析、社会媒体研究、多模态人机交互、计算视觉、计算图像方向。小编今天给大家介绍一下本次大会的两篇Best Papers 工作!
最佳论文:Open-Vocabulary 3D Affordance Understanding via Functional Text Enhancement and Multilevel Representation Alignment

机构:英国格拉斯哥大学
作者:Lin Wu,Wei Wei,Peizhuo Yu,Jianglin Lan∗
研究方法:提出Aff3DFunc框架,基于信息瓶颈原理设计功能文本增强模块,通过双编码器架构提取点云几何特征与文本语义特征,结合多级表示对齐策略和监督对比学习,实现3D开放词汇可用性理解,支持零样本场景泛化并通过真实机器人验证。
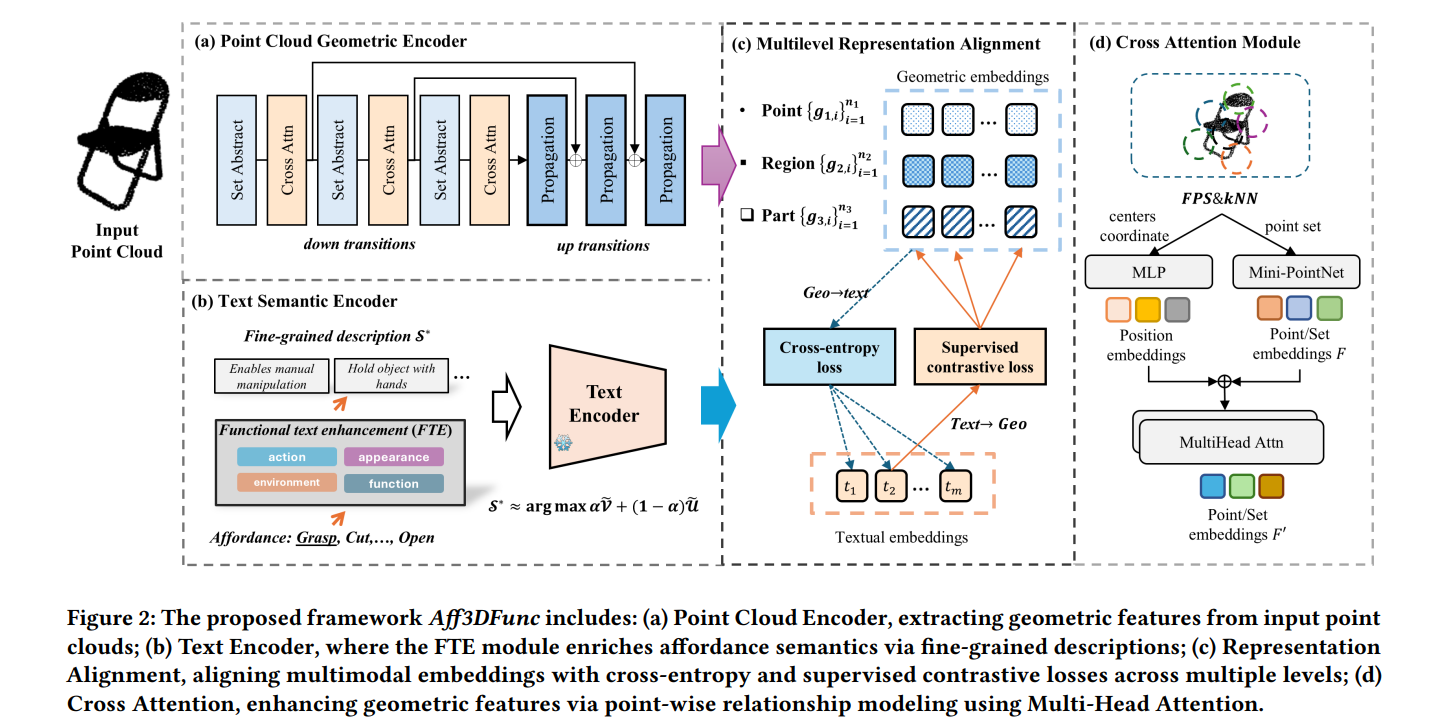
创新点:
- 提出轻量级开放词汇框架Aff3DFunc,联合建模可用性语义与物体几何特征,适配未见过的可用性类别。
- 设计基于信息瓶颈原理的功能文本增强(FTE)策略,平衡类内多样性与类间可分性,系统构建语义空间。
- 开发多级表示学习方案,融合交叉熵损失与监督对比损失,建立模态间一致对应关系。
- 通过真实机器人实验验证,在零样本场景下显著提升3D可用性理解的有效性与泛化能力。
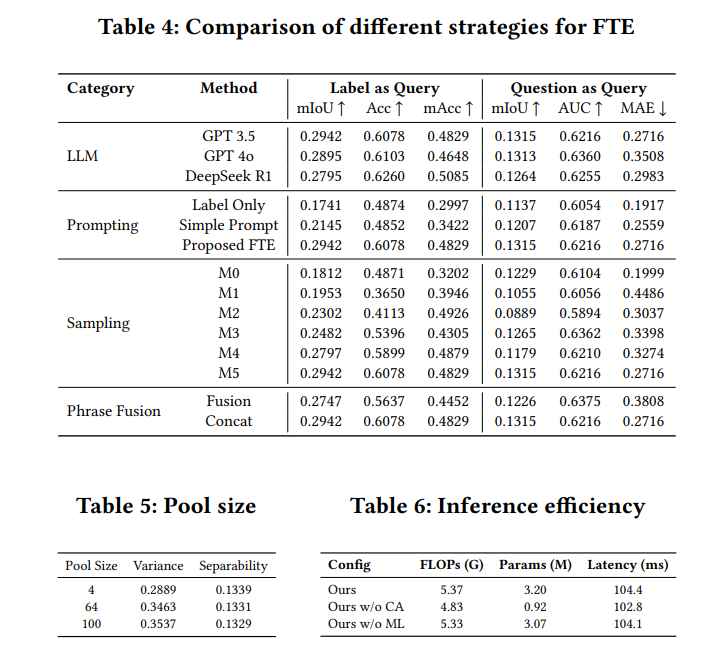
论文网址:https://dl.acm.org/doi/pdf/10.1145/3746027.3755239
代码网址:https://github.com/wulin97/Aff3DFunc
最佳学生论文:Building Embodied EvoAgent : A Brain-inspired Paradigm for Bridging Multimodal Large Models and World Models

机构:中国科学院自动化研究所、中国科学院大学人工智能学院、联想集团研究院、鹏城实验室
作者:Junyu Gao、Xuan Yao、Yong Rui、Changsheng Xu
研究方法:提出脑启发的Embodied EvoAgent框架,借鉴人类大脑左右半球功能分工,构建包含三个核心模块的统一范式。通过具身上下文增强多模态大语言模型(EC-MLLM)模拟左半球语言处理与逻辑分析能力,基于循环状态空间模型的感知上下文引导世界模型(PC-WM)模拟右半球空间感知与整体思维功能,再以动态通信槽(DCS)模拟胼胝体的信息传递机制,实现两模块高效双向交互与在线进化,提升智能体在具身任务中的执行能力与零样本泛化能力。
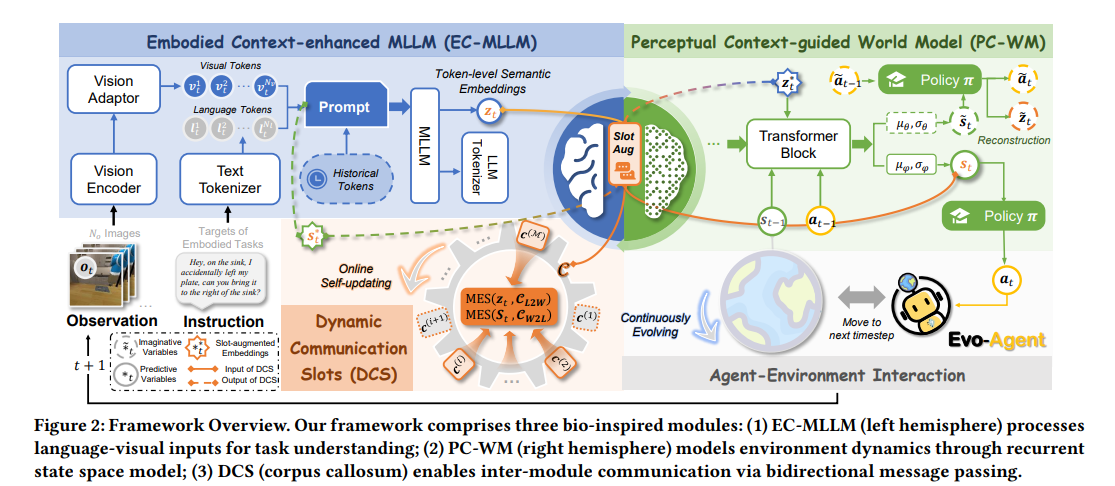
创新点:
- 提出脑启发的具身智能进化范式,将EC-MLLM与PC-WM有机融合,分别模拟大脑左右半球功能,实现多模态理解与环境动态建模的协同。
- 设计动态通信槽(DCS)模块,模拟胼胝体的信息传递机制,通过注意力基动态更新策略,实现两核心模块的高效双向信息交互与快速适配。
- 无需针对域外任务进行监督训练,依托具身探索经验与在线进化机制,显著提升智能体在零样本域外具身任务中的泛化能力与空间理解能力。
- 支持参数高效微调,在冻结主模型核心参数的同时保持其原有推理能力,仅优化新增模块即可实现性能提升,降低部署成本。
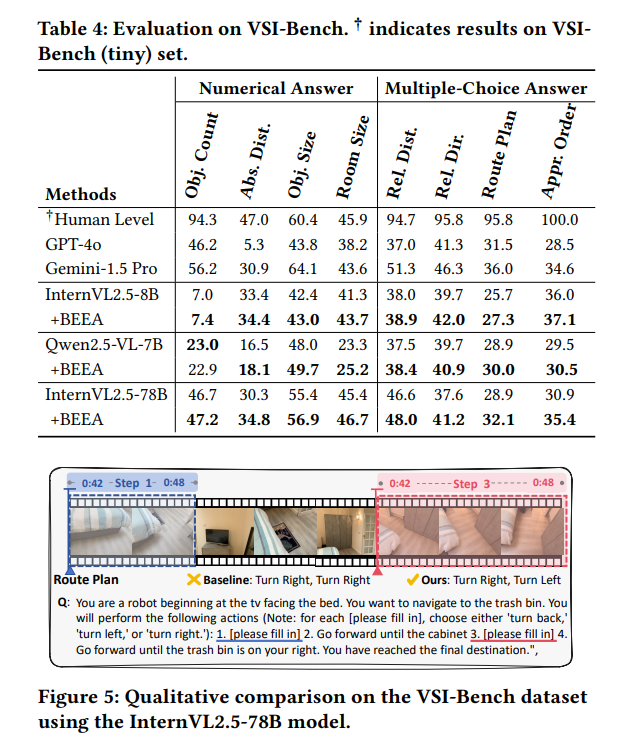
论文网址:https://dl.acm.org/doi/pdf/10.1145/3746027.3754880
代码网址:https://feliciaxyao.github.io/EvoAgent/


















 1631
1631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









