







 第八章 集成学习个体与集成BoostingBagging 与随机森林个体与集成个体与集成集成学习通过构建并结合多个学习器来完成学习任务,也被称为多分类器系统。集成学习的一般结构:先学习一组个体学习器,再用某种策略将他们结合起来。若集成中只包含同种类型的个体学习器,则这样的集成是同质。同质集成中的个体学习器亦称为基学习器。相应的学习算法称为基学习算法。不同的称为异质,称为组件学习器。那么集成学习如何获得比最好的单一学习器更好的性能呢?集成学习器的结果通过投票法产生,少数服从多数。因此,要获得好的
第八章 集成学习个体与集成BoostingBagging 与随机森林个体与集成个体与集成集成学习通过构建并结合多个学习器来完成学习任务,也被称为多分类器系统。集成学习的一般结构:先学习一组个体学习器,再用某种策略将他们结合起来。若集成中只包含同种类型的个体学习器,则这样的集成是同质。同质集成中的个体学习器亦称为基学习器。相应的学习算法称为基学习算法。不同的称为异质,称为组件学习器。那么集成学习如何获得比最好的单一学习器更好的性能呢?集成学习器的结果通过投票法产生,少数服从多数。因此,要获得好的
个体与集成
集成学习通过构建并结合多个学习器来完成学习任务,也被称为多分类器系统。
集成学习的一般结构:先学习一组个体学习器,再用某种策略将他们结合起来。
若集成中只包含同种类型的个体学习器,则这样的集成是同质。同质集成中的个体学习器亦称为基学习器。相应的学习算法称为基学习算法。不同的称为异质,称为组件学习器。
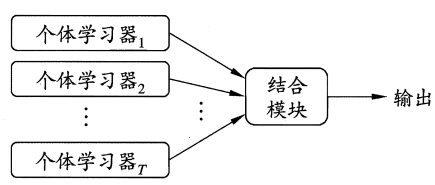
那么集成学习如何获得比最好的单一学习器更好的性能呢?
集成学习器的结果通过投票法产生,少数服从多数。因此,要获得好的集成,个体学习器应该好而不同。即个体学习器要有一定的准确性,并且有多样性。而因为训练数据相同,多样性和准确性相斥。
根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类。即个体学习器问存在强依赖关系、必须串行生成的序列化方法,以及个体学习器
间不存在强依赖关系、可同时生成的并行化方法;前者的代表是 Boosting ,后者的代表是 Bagging 和"随机森林"。
Boosting
Boosting是一族可以将弱学习器提升为强学习器的算法。这族算法的工作机制类似:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续收到更多的关注,然后基于调整后的样本分布来训练下一个基学习器,如此重复直到基学习器数目达到事前指定的T,最终将这T个基学习器进行加权结合。
Boosting族算法中最著名的是AdaBoost。
AdaBoost算法有多种推导方式,比较容易理解的是基于加性模型,即基学习器的线性组合:
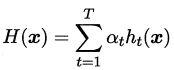 来最小化指数损失函数:
来最小化指数损失函数:
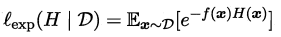
看到这里回想一下之前的机器学习算法,不难发现机器学习的大部分带参模型只是改变了最优化目标中的损失函数:如果是Square loss,那就是最小二乘了;如果是Hinge Loss,那就
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1346
1346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









