







![]()
基于云服务器的分片式集群部署及应用
文章目录
(应用部分我会放到下一期文章里面讲)
关于MongoDB
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数
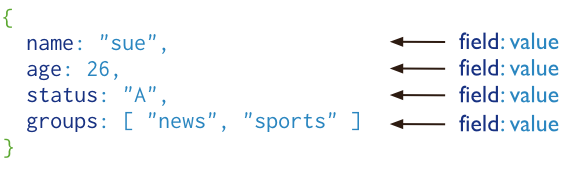
关于NOSQL
NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。
在现代的计算系统上每天网络上都会产生庞大的数据量。
这些数据有很大一部分是由关系数据库管理系统(RDBMS)来处理。 1970年 E.F.Codd’s提出的关系模型的论文 “A relational model of data for large shared data banks”,这使得数据建模和应用程序编程更加简单。
通过应用实践证明,关系模型是非常适合于客户服务器编程,远远超出预期的利益,今天它是结构化数据存储在网络和商务应用的主导技术。
NoSQL 是一项全新的数据库革命性运动,早期就有人提出,发展至2009年趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
环境配置:
实验环境
操作系统:CentOS7
Mongo版本:4.0.5
服务器:腾讯云+若干虚拟机
CentOS7上的mongoDB源码安装
初次使用CentOS前的一些学习和准备
VMware虚拟机
SSH连接软件例如Xshell
集群环境:
2个分片复制集
shard1(使用27017端口)
shard2(使用27018端口)
1个config复制集(使用28018端口)
1个mongos节点
初次使用CentOS,需要学习和认识一些指令,这里仅列出常用的指令,如果使用图形化界面当我没说
在linux中只需打出前缀字母再按Tab键,系统会将与前缀匹配的文件名/服务名自动补全
vim XXX使用vim编辑器打开文本文件XXX,若无该文件则创建
按下i进入编辑模式,可以自由输入文本,想要退出时先按下Esc再打出:wq即可
mkdir -p /menu1/menu2/使用递归方式创建目录,用于创建文件夹
rm -f filename删除某文件
systemctl stop firewalld.service关闭防火墙,由于端口放行比较麻烦,所以建议直接关闭
systemctl disable firewalld.service关闭防火墙服务的开机自启动
cd /menu1/menu2/进入文件夹
ls当前文件夹内容列表,可执行文件会用颜色标出
ll当前文件夹内容列表详细信息
ctrl+L清屏
ctrl+C退出进程
ip addr查看ip地址
netstat -nptl查看进程及其使用端口
kill (portid)杀死使用端口的进程
yum install -y wget使用yum下载wget,wget用于从url下载文件
yum install screen -y使用yum下载screen,screen用于在命令行界面守护多进程执行
screen的一些基本指令:
screen -ls #查看screen列表,可以看到窗口使用的端口号
screen -RU XXX #创建一个名为XXX的screen,创建成功自动跳转到该screen
screen -xU XXX #切换到名为XXX的screen
ctrl+A [D] #按住ctrl+A后再按D,将screen切换到后台并继续执行
想要关闭窗口只需查看窗口使用的端口号并kill
reboot重启,shutdown关机
搭建mongodb分片复制集
需要注意的是,与windows版本不同,如果是使用Linux进行源码安装,是没有默认配置文件的,必须由用户自行生成
安装步骤见Centos7安装mongoDB
配置文件xxx.conf,具体选项参照./bin/mongod --help说明
- 复制集1
(mongo.conf文件的配置信息)
# 数据路径
dbpath=/data/mongo/
port=27017
bind_ip=0.0.0.0
fork=true
# 日志路径
logpath = /data/mongo/mongodb.log
logappend = true
# 复制集的名字
replSet=elk_repl
smallfiles=true
# 分片集群的必须属性
shardsvr=true
# 取消身份验证
noauth=true
#建议如果是放在服务器上还是得打开身份验证
#auth=true
- 复制集2
(mongo2.conf文件的配置信息)
dbpath=/data/mongo2/
port=27018
bind_ip=0.0.0.0
fork=true
logpath = /data/mongo2/mongodb.log
logappend = true
replSet=elk_repl2
smallfiles=true
shardsvr=true
noauth=true
conf文件呈现为多级形式,其中systemlog为系统日志,设置输出为文件并确定文件路径,通常可以不显式设置(即去除这一段配置代码),那么将输出在standout中;processManagement为mongod的进程管理,设置fork: true则mongod将在后台运行。通常可以不显式设置这两者,即mongod在终端运行,同时系统日志在终端窗口输出。
net配置项与远程连接mongodb相关,在本机测试环境下无需显式配置(上述conf中net是默认配置)。
storage配置项主要与mongodb的运行状态相关,包括dbPath设置db文件路径,journal设置是否开启WAL,syncPeriodSecs设置mongodb刷数据文件点间隔(从一方面来说,代表了checkpoint的周期时长),engine修改存储引擎等。
集群节点启动以及配置
使用sharding模式布置集群至少需要3个节点
- 启动复制集
./bin/mongod -f mongo.conf
./bin/mongod -f mongo2.conf
- 登录复制集
./bin/mongo -port 27017
./bin/mongo -port 27018
- 初始化配置复制集
rs.initiate(
{
_id: "elk_repl", #对应的复制集名称
members: [ #分配成员ID以及节点和端口
{ _id : 1, host : "124.222.255.38:27017" }, #服务器的公网地址
{ _id : 2, host : "192.168.204.128:27017" }, #虚拟机1的内网地址
{ _id : 3, host : "192.168.204.129:27017" } #虚拟机2的内网地址
]
}
)
在这里你会发现一个问题,配置使用的host地址全部都是公网IP,而两台虚拟机使用的是192.168开头的内网IP,既然不在一个局域网内那么服务器肯定是无法连接到虚拟机的,如果直接在mongoDB中使用这串初始化指令必然会导致一个问题:外部地址无法访问。假设是三台同一局域网下的虚拟机或者三台都使用公网IP的服务器是不会出现这样的问题的。所以我们要访问内网地址。
如果要访问内网地址,能够采取两个方案:
1.内网穿透
2.端口映射
我们在此处选择的方案是端口映射,此方案如果ISP是移动的话无法使用,移动大内网的网络布局过于不合理,外部地址传入时很有可能不能正常的被你的路由器映射。
##端口映射原理及其步骤
假设现在有个快递要发到你家,那你填写的详细地址一定是xx省xx市xx县xx镇xx村xx小区215,因为物流方需要知道你的详细地址才能把[包]发到你家中。如果只写了xx小区而不写门牌号那人家当然不知道把[包]发到哪里了。现在这个门牌号就是你的端口号,物流方就是发送包的那方,现在外部有个包要发送到你的主机上,而且必须要发到正确的门牌号,比如主机上的215端口,但是物流方并不能直接发送到215端口,只是说了发送到菜鸟驿站。那要怎么拿到呢?当然是菜鸟驿站帮你放到合适的货架上,比如你住在215端口,那么菜鸟驿站就归类到货架1000,而另一个住户是213端口,菜鸟驿站归类是2000。菜鸟驿站就是我们现在的路由器,当然怎么归类完全由路由器的主人来设定。也就是说:
发送方发出包让215端口接收–》路由器某端口:如1000端口转发给主机的215端口–》215端口收到包

也就是说我们设置路由器的1000端口专门为我们转发215端口的包,这样就能实现【公网ip发包给内网端口】的效果了,将路由器作为转换的桥梁
因此我们的解决方法就很简单了,在浏览器中输入192.168.1.1打开路由器设置,登录路由器后在配置里选择虚拟服务器配置,设置你想要的转发端口和你本机的内网地址以及接收端口,这样就能在本机的215端口收到包了。

但是别忘了,需要收到包的并不是本机的215端口,而是192.168.204.128:27017端口,那应该怎么办?
如果一次转发收不到,那就不停的转发它,强迫它收到为止!将本机看作菜鸟驿站再次转发给虚拟机就行了,也就是说再来一次。我们在虚拟机里进行网络配置的设置,将宿主机的215端口作为虚拟机192.168.204.128的27017端口的映射,当215端口收到了路由器转发的包,我们再将其转发给虚拟机,这样就能让虚拟机收到了。也就是说,通过两级端口映射,通过公网发出的包就可以被内网的虚拟机接收到了。顺带一提,虽然我们已经关闭了服务器和虚拟机的防火墙,但是本机的防火墙还是开着吧,我们只需要对建立映射的215端口放行就好了。(不过还有一个问题,由于每次打开关闭路由器的时候ISP都会随机分配一个公网地址,所以对我们这种寝室会熄灯的主机而言可能今天是这个IP地址,明天就成了另一个IP地址了,只能删除之前的数据库信息重新再初始化,如果有条件可以向ISP申请一个固定的公网IP)

那么建立完映射之后,我们的代码就应该是这样
rs.initiate(
{
_id: "elk_repl", #对应的复制集名称
members: [ #分配成员ID以及节点和端口
{ _id : 1, host : "124.222.255.38:27017" }, #服务器的公网地址
{ _id : 2, host : "171.116.209.107:10022" }, #宿主机的公网地址,路由器转发端口是10022,对应虚拟机1的27017端口
{ _id : 3, host : "171.116.209.107:10024" } #宿主机的公网地址,路由器转发端口是10024,对应虚拟机2的27017端口
]
}
)
同样的操作对第二个数据库分片27018端口再来一次,这样三个节点,6个分片就全部布置完成了。
创建config节点配置文件
创建节点配置文件:mongo-cfg.conf
systemLog:
destination: file
# 日志存储路径
path: "/data/mongo/mongo-cfg/logs/mongodb.log"
logAppend: true
storage:
journal:
enabled: true
# 数据存储路径
dbPath: "/data/mongo/mongo-cfg/dbdata"
directoryPerDB: true
wiredTiger:
engineConfig:
# 最大使用cache
cacheSizeGB: 1
# 是否索引也按照数据库名单独存储
directoryForIndexes: true
collectionConfig:
# 表压缩配置
blockCompressor: zlib
indexConfig:
prefixCompression: true
net:
# IP地址
bindIp: 171.116.209.107
# 端口
port: 28018
replication:
oplogSizeMB: 2048
#配置节点的复制集名字
replSetName: configReplSet
sharding:
clusterRole: configsvr
processManagement:
fork: true
- 启动配置服务器
# 配置文件地址
./mongod -f /root/mongo/mongo-cfg.conf
- 登录配置节点
# 配置文件地址
# 指定IP和端口
./bin/mongo -host 192.168.204.128 -port 28018
- 初始化命令
rs.initiate(
{
_id: "configReplSet", #对应的复制集名称
configsvr: true
members: [ #分配成员ID以及节点和端口
{ _id : 1, host : "124.222.255.38:28018" }, #服务器的公网地址
{ _id : 2, host : "171.116.209.107:10026" }, #宿主机的公网地址,路由器转发端口是10026,对应虚拟机1的28018端口
{ _id : 3, host : "171.116.209.107:10027" } #宿主机的公网地址,路由器转发端口是10027,对应虚拟机2的28018端口
]
}
)
mongos节点配置文件
- 配置文件
systemlog:
destination: file
path: /root/mongo/logs/mongos.log
logAppend: true
net:
bindIp:171.116.209.107
port: 28017
sharding:
configDB: configReplSet/124.222.255.38:28018,192.168.204.128:28018,192.168.204.129:28018
#此处我填写的另外两个地址是虚拟机分配的子网IP,当然你可以同理再设置端口映射
#或者在配置文件命名host用于代表IP地址
#configDB: configReplSet/test201:28018,test202:28018,test203:28018
processManagement:
fork: true
- host配置文件
(三台都要配置)
#在命令行输入 cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
124.222.255.38 test201
192.168.204.128 test202
192.168.204.129 test203
- 启动mongos
./bin/mongos -config /root/mongo/mongos.conf
- 登录mongos节点
./bin/mongo 124.222.255.38:28017
添加集群中的分片节点
- 切换到admin: use admin
- 添加shard1复制集
db.runCommand({ addshard :
"elk_repl/124.222.255.38:27017,192.168.204.128:27017,192.168.204.129:27017",name:"shard1"})
- 添加shard2复制集
db.runCommand({ addshard :
"elk_repl2/124.222.255.38:27018,192.168.204.128:27018,192.168.204.129:27018",name:"shard2"})
- 查看分片
db.runCommand({ listshards : 1 })
- 查看分片状态
sh.status()
解释名词
在查看了一大串的配置指令之后可能会搞得有点稀里糊涂的。简单来说上面的配置信息可以分成两部分,第一部分是对Mongo的配置操作,第二部分是对Mongos的配置操作。Mongo和Mongos只相差一个字母,但并不是同一个东西。
<font size=5 & color=#e83e8c>Mongo是客户端,我们可以用客户端的MongoDB Shell完成我们熟悉的那些诸如增删改查等等等等客户端所能提供的操作。
<font size=5 & color=#e83e8c>Mongos是’MongoDB Shard Utility’,"MongoDB Shard"用于分片集群的控制器和查询路由器,分片将数据集分区为不连续的部分,它处理来自应用程序层的查询,并确定分片集群中此数据的位置,以便完成这些操作.从应用程序的角度来看,mongos实例的行为与任何其他MongoDB实例完全相同。
另外,你可能也注意到了启动conf文件时需要使用<font size=5 & color=#e83e8c>Mongod,它是核心数据库进程,简单来说可以用于守护当前数据库的进程,和screen的功能是相似的。
有关更多信息,请访问http://docs.mongodb.org/manual/reference/program/
测试分片集群
- 开启数据库分片配置
db.runCommand( { enablesharding : "testdb" })
- 创建分片的键(id)
db.runCommand( { shardcollection : "testdb,users",key : {id: 1} })
- 创建索引(在非空集合内)
use testdb
db.users.ensureIndex( { id: 1 } )
- 添加测试数据
var arr=[];
for(var i=0;i<1500000;i++){
var uid = i;
var name = "name"+i;
arr.push({"id":uid,"name":name});
}
db.users.insertMany(arr);
我们可以看到,在测试结果中每375000个数据分到一个片中,即使是同一个片在存储大量数据时也分为了不同的时间戳,这样我们就可以大概理解mongodb的分片式集群
通过分片,将数据拆分,一组数据可以被分到多台机器上,从而减轻服务器的负担,存储更多数据。出于成本的考虑,使用具有强大性能的服务器可能成为一种奢望,但是通过分片式集群使用三台或以上轻量应用型服务器,只需要增加服务器,就可以达到相似的效果。MongoDB无疑是中小企业或个人的优越选择,正所谓三个臭皮匠顶一个诸葛亮。
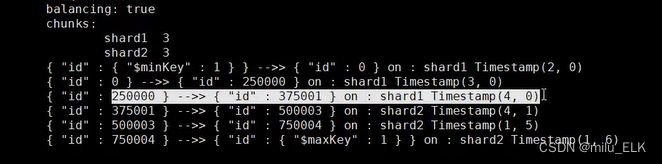
至此,基于mongoDB的分片式集群数据库部署完毕。
其他的操作
创建管理员用户
db.createUser({ user: '', pwd: '', roles: [{ role: 'userAdmin', db: '' }] })
- 查看当前复制集成员状态
rs.status()
输入此命令查看复制集状态,布置成功的话三个节点中第一个初始化的节点会成为主键,用户字段”stateSTR“显示”PRIMARY“
其余两个节点作为副成员,用户字段”stateSTR“显示”SECONDARY“
如果某个Primary宕机了可能会导致其他Secondary操作出现异常,我们只需要将宕机的节点删除并选举出新的Primary即可,或者你也可以删除掉data里的缓存文件重新对mongodb进行初始化。

如果需要用户验证,则需要主键产生一个密钥并分发给副成员,当主键的主机宕机时,将由副成员举行投票选出新的主键,而原来的主键降级为副成员。
其他的更多设定就由大家自行学习吧。
导入我的数据(JSON格式)
./bin/mongoimport --db MHR --collection armor --type json ./armor.json















 3244
3244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









