







损失函数
统计学习中常用的损失函数:
平方损失函数
平方损失函数是最常见的损失函数,在回归中经常使用。
L(Y,f(X))=(Y−f(X))20-1损失函数
L(Y,f(X))=I(Y≠f(X))对数损失函数
对数损失函数是逻辑回归的损失函数,在逻辑回归中,假设样本服从伯努利分布(0-1分布),对样本的估计是用概率形式表达的,即:
P(y|x;θ)=(hθ(x))y(1−hθ(x))1−y
然后取对数得到极大似然估计,而损失函数将似然函数取反,采用梯度下降使其最小。标准的对数损失函数如下:
L(Y,P(Y|X))=−logP(Y|X)指数损失函数
指数损失函数是前向分布算法的损失函数,常见的Adaboost是前向分布算法的一个特例,在Adaboost中,分类器和样本权值的更新公式为:
αm=12log1−emem
wm+1,i=wmiZmexp(−αmyiGm(xi))
这两个公式均是将下式带入到指数损失函数中推导出来的。
fm(x)=fm−1(x)+αmGm(x)合页损失函数
合页损失函数出现在SVM中,可以将其表示为:
∑i=1n[1−yi(wxi+b)]++λ∥w∥2
其中[]+是取正值函数,即:
z,z>00,z≤0
SVM中定义支持向量的距离为1,约束条件中所有点到超平面的距离都要大于1,那么,大于1且分类正确的点的损失值为0。后面的那一项是正则项,控制模型复杂度。
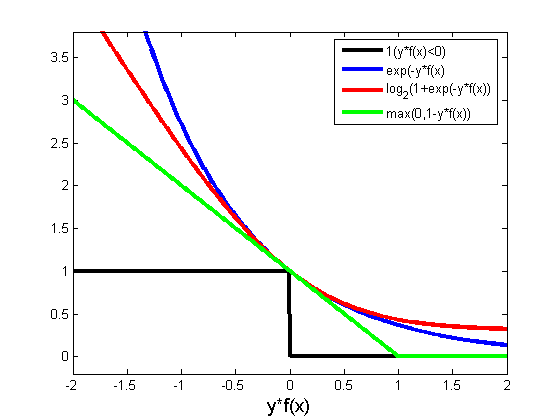
下图给出了各种损失函数对应的曲线。















 2263
2263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









