







摘要: 文无第一, 武无第二. 本贴描述常见的性能评价指标.
性能评价是不同方法 PK 的基础. 要清楚裁判的标准, 才能当好一名运动员.
性能评价指标多数时候是比较直观的, 需要足够的合理性, 才能获得大家的认同. 比如, 短跑比拼的是时间, 谁用时少谁就获胜. 如果你制定一个指标, 谁跑的姿式更优美, 就不合适. 当然, 新开发一个项目, 跳健美操, 就是比姿式了.
有些人专门研究性能评价指标, 很有意义. 但相应的论文不多, 毕竟项目的个数要远远少于运动员的人数.
1. 分类问题评价指标
1.1 准确率 Accuracy
100 个测试样本, 预测正确 95 个, 则准确率为 95%.
- 如果是二分类问题, 准确率低于 50% 毫无意义.
- 如果是多分类问题, 准确率低于 50% 也行.
1.2 F-measure
对于二分类问题, 我们更关注的可能是其中一类. 如根据症状判断是否流感. 将就诊者称为样本, 患流感称为正例, 否则为负例.
| 实际\预测 | 正 | 负 |
|---|---|---|
| 正 | T P = 15 TP = 15 TP=15 | F N = 5 FN = 5 FN=5 |
| 负 | F P = 20 FP = 20 FP=20 | T N = 60 TN = 60 TN=60 |
表 1 给出了一个混淆矩阵. 其中,
- 实际的正例有 P = T P + F N = 15 + 5 = 20 P = TP + FN = 15 + 5 = 20 P=TP+FN=15+5=20 个;
- 实际的负例有 N = T N + F P = 60 + 20 = 80 N = TN + FP = 60 + 20 = 80 N=TN+FP=60+20=80 个;
- 本身是正例, 判断正确 (也为正例) 有 T P = 15 TP = 15 TP=15 (true positive) 个;
- 本身是正例, 判断错误 (弄成负例) 有 F N = 5 FN = 5 FN=5 (false negative) 个;
- 本身是负例, 判断错误 (弄成正例) 有 F P = 20 FP = 20 FP=20 (false positive) 个;
- 本身是负例, 判断正确 (也为负例) 有 T N = 60 TN = 60 TN=60 (true negative) 个.
这样获得四个评价指标:
- 精度 P = T P T P + F P = 15 35 P = \frac{TP}{TP + FP} = \frac{15}{35} P=TP+FPTP=3515 表示判断为正例的样本中, 有多大比例是正确的. 这适合于推荐系统等应用, 你推荐的电影, 要观众喜欢才行.
- 召回率 R = T P T P + F N = 15 20 R = \frac{TP}{TP + FN} = \frac{15}{20} R=TP+FNTP=2015 表示被找出来的样本比例有多大. 这适合于流行病检测等应用, 不要有新冠患者被漏掉.
- 准确率 针对二分类问题时, 准确率可以写为 A c c = T P + T N T P + F N + F P + T N Acc = \frac{TP + TN}{TP + FN + FP + TN} Acc=TP+FN+FP+TNTP+TN.
- F 1 F_1 F1-measure F 1 = 2 P R P + R F_1 = \frac{2PR}{P + R} F1=P+R2PR 是一个比较综合的评价指标. 当 P = R = 1 P = R = 1 P=R=1 时, F 1 = 1 F_1 = 1 F1=1. 这适合于同时考虑精度与召回率的应用: 如果要精度高, 就进可能判断样本是负的; 如果要召回率高, 就尽可能判断样本是正的; 而如果要 F 1 F_1 F1 高, 则进行了良好的折中.
1.3 基于实数值 (概率) 预测的评价指标
接上节, 有时候我们并不直接判断某个样本是正是负, 而是给出一些实数值的预测. 例如, 样本 1 为正的可能性为 0.6, 而样本 2 为正的可能性为 0.7.
- 受试者曲线 ROC. 给定任意一个阈值
α
\alpha
α, 预测值
y
i
′
≥
α
y_i' \geq \alpha
yi′≥α 的点认为是正例, 而
y
i
′
<
α
y_i' < \alpha
yi′<α 的为负例. 可以得到相应的
- True Positive Rate T P R = T P P ; TPR = \frac{TP}{P}; TPR=PTP;
- False Positive Rate
F
P
R
=
F
P
N
.
FPR = \frac{FP}{N}.
FPR=NFP.
T P R TPR TPR 与 F P R FPR FPR 都关于 α \alpha α 非递减, 且 α \alpha α 从 1 变到 0, T P R TPR TPR 与 F P R FPR FPR 均从 0 变到 1. 两种极端情况: - 最佳情况: 所有正例的预测值均大于 0.7, 所有负例的预测值均小于 0.7. 这样, α ≥ 0.7 \alpha \geq 0.7 α≥0.7 时, F P = 0 FP = 0 FP=0, F P R = 0 FPR = 0 FPR=0. T P TP TP 随着 α \alpha α 的减小而增加直到上限 P P P. P P P 为常数, 因此 T P R TPR TPR 也一直增加直到 1. 这些点连起来就是从 ( 0 , 0 ) (0, 0) (0,0) 到 ( 0 , 1 ) (0, 1) (0,1) 的一条线段. 之后, 随着 α \alpha α 减小到 0.7 之下, F P FP FP 逐渐增加直到上限 N N N. 这些点连起来就是从 0 , 1 0, 1 0,1 到 ( 1 , 1 ) (1, 1) (1,1) 的一条线段.
- 最坏情况: 所有负例的预测值均大于 0.7, 所有正例的预测值均小于 0.7. α ≥ 0.7 \alpha \geq 0.7 α≥0.7 时, T P = 0 TP = 0 TP=0, T P R = 0 TPR = 0 TPR=0. F P FP FP 随着 α \alpha α 的减小而增加直到上限 N N N. N N N 为常数, 因此 F P R FPR FPR 也一直增加直到 1. 这些点连起来就是从 ( 0 , 0 ) (0, 0) (0,0) 到 ( 1 , 0 ) (1, 0) (1,0) 的一条线段. 之后, 随着 α \alpha α 减小到 0.7 之下, T P TP TP 逐渐增加直到上限 P P P. 这些点连起来就是从 ( 1 , 0 ) (1, 0) (1,0) 到 ( 1 , 1 ) (1, 1) (1,1) 的一条线段.
- 随机猜情况: 与 y = x y = x y=x 很贴近的一条折线.
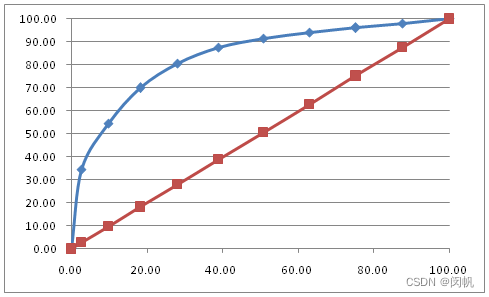
图 1 给了一个 ROC 曲线的例子. 这个曲线可以用如下等价的方法画出:
-
将样本按其预测值逆序列排列, 如 ( 0.95 , 0.89 , 0.87 , 0.73 , 0.65 , 0.42 , 0.31 ) (0.95, 0.89, 0.87, 0.73, 0.65, 0.42, 0.31) (0.95,0.89,0.87,0.73,0.65,0.42,0.31) 分别对应于 ( x 5 , x 6 , x 1 , x 3 , x 7 , x 4 , x 2 ) (x_5, x_6, x_1, x_3, x_7, x_4, x_2) (x5,x6,x1,x3,x7,x4,x2).
-
假设负样本 4 4 4 个, 正样本 3 3 3 个, X X X 轴每个刻度的长度为 0.25 0.25 0.25, Y Y Y 轴每个刻度的长度为 0.33 0.33 0.33.
-
从 ( 0 , 0 ) (0, 0) (0,0) 出发, 依次查看各样本的标签. 如果为正, 就向上走 1 1 1 个刻度, 如果为负, 就向右走 1 1 1 个刻度. 由此获得 ( 0 , 0 ) (0, 0) (0,0) 到 ( 1 , 1 ) (1, 1) (1,1) 的折线, 就是 ROC 曲线.
-
曲线下面积 AUC. ROC 曲线与 x = 0 x = 0 x=0, x = 1 x = 1 x=1, y = 0 y = 0 y=0 三条直接围成的区域, 其面积称为 AUC (Area Under Curve). 最佳情况下, A U C = 1 AUC = 1 AUC=1. 最坏情况下, A U C = 0 AUC = 0 AUC=0.
1.4 基于序的评价指标
预测样本为正的概率, 然后按照该概率将样本进行逆序排列. 例如, 为用户推荐电影时, 将他最有可能喜欢的电影放在前面.
相应地, 获得一系列评价指标, 如: HR, HR@5, DCG, NDCG, NDCG@10.
ROC 也可以用基于序的方式画出来. 假设有 100 个待预测样本, 真实标签有 40 个为正, 60 个为负. 则将所有样本按预测值逆序排列, 依次查看它们的标签, 并用如下方式画一条折线: 如果是正例, 则向上移动 1/40; 如果是负例, 则向右移动 1/60. 这条折线就是 ROC 曲线.
2. 回归问题评价指标
n n n 个测试样本, 第 i i i 个的真实标签值为 y i y_i yi, 预测标签值为 y i ′ y_i' yi′.
- 平均绝对误差 Mean Absolute Error M A E = ∑ i = 1 n ∣ y i − y i ′ ∣ n MAE = \frac{\sum_{i = 1}^n \vert y_i - y_i' \vert}{n} MAE=n∑i=1n∣yi−yi′∣. 错了多少, 就受多大的惩罚.
- 均方根误差 Root Mean Squared Error R M S E = ∑ i = 1 n ( y i − y i ′ ) 2 n RMSE = \sqrt{\frac{\sum_{i = 1}^n (y_i - y_i')^2}{n}} RMSE=n∑i=1n(yi−yi′)2. 有一个平方, 导致误差大的预测受到更严厉惩罚.
3. 聚类问题评价指标
聚类没有一个可参考的客观标准, 所以评价指标很凌乱.
- 内部评价指标: 紧密度 (Compactness) 计算每个样本点到它对应的聚类中心的距离, 然后将它们加起来求平均.
- 外部评价指标: 借助于数据的标签. 但这事情比较扯: 数据本身是没有标签的, 聚类结果你爱怎么解释都行, 从逻辑上无法引入客观的一个标签.
关于聚类, 更多指标参见:
https://blog.csdn.net/kfnorthwind/article/details/109362011
4. 常见的误区
- 以为性能评价指标是一成不变的. 实际上每个人都可以设计新的指标 (或创造一种新的运动).
- 仅用一个指标来做实验. 一篇论文要写得丰富, 需要多个评价指标, 每个对应于一张图或一张表.
















 2042
2042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









