






专业算力卡是不少垃圾佬的最爱捡漏显卡之一,比如 P102、P104、P106、 P40、M40、P100 之类的计算卡性价比都非常高,不足千元甚至两三百元就能摸到 8G 显存甚至 16G 显存的门槛,这就是下面要分享的这款大船靠岸的专业算力卡,Tesla V100 SXM2 16G 显卡,一款不到600元的算力卡,真AI圈的“平民超跑”!

关注我,后续分享更多精彩内容!
关注可加交流群哈!
群里有大佬哥!
纯个人交流群,无利益纠纷,随意畅聊装机乐趣,优化装机配置!
有大佬,也有小白,欢迎您的加入,期待您的分享!

扫码添加后可拉DIY交流群!
一、Tesla V100 SXM2 16G 显卡介绍
Tesla V100 SXM2 16G 显卡是一款专业算力卡,它是IBM服务器的二手拆机的显卡,作为专业计算卡,它没有显示输出接口,不能直接用于日常的图形显示,但在AI服务器应用中,这并不影响它发挥实力。
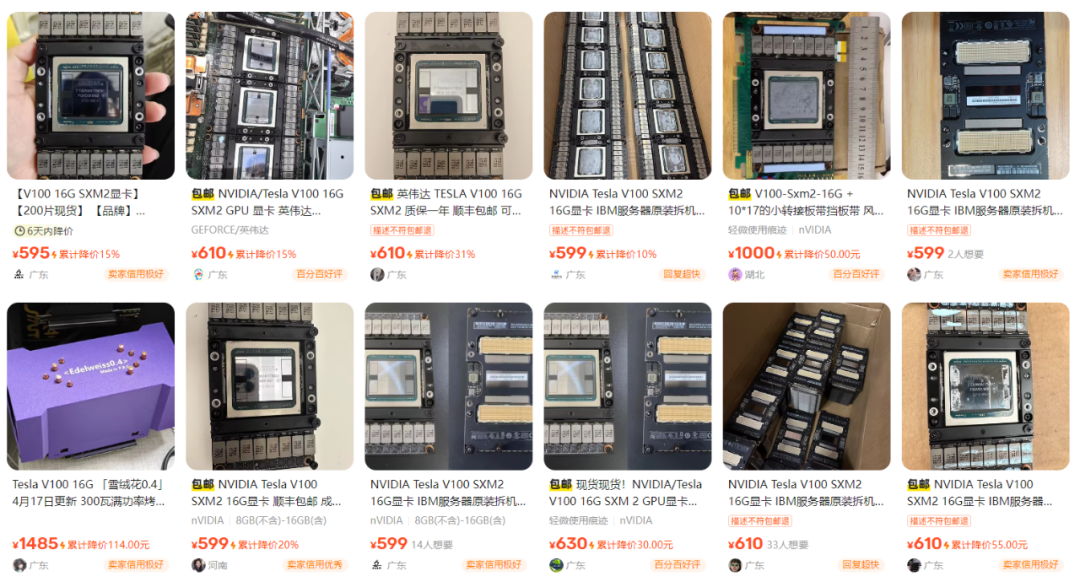
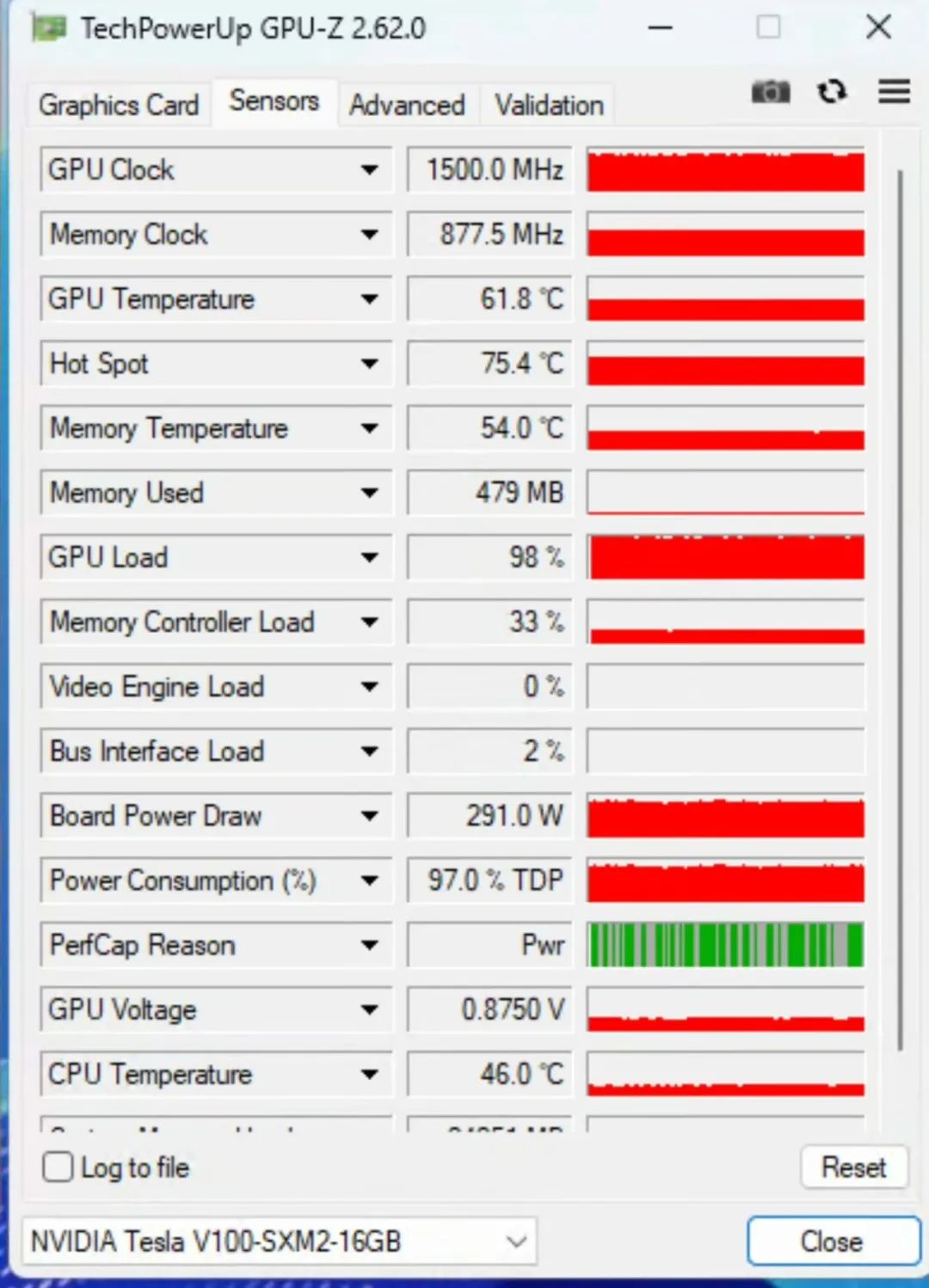
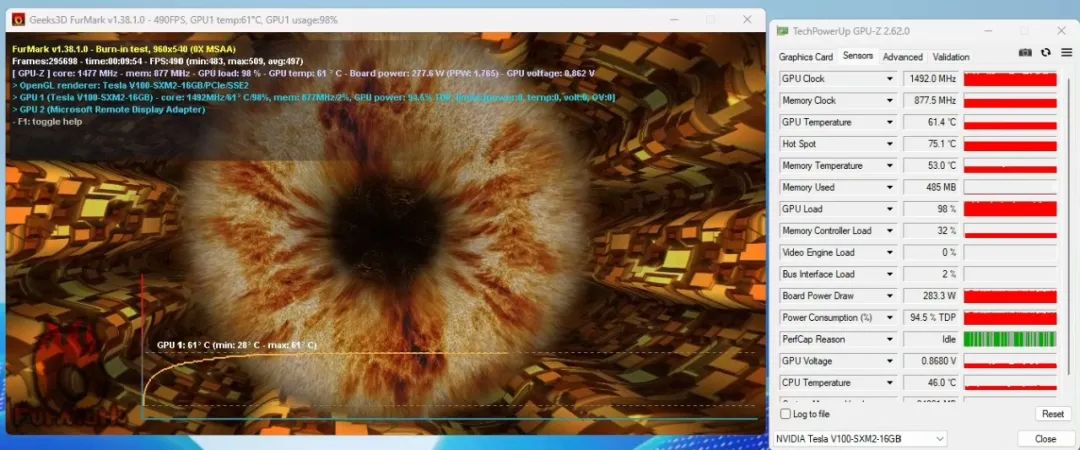
这款显卡真的是性价比之王,它有5120个CUDA核心和16GB显存容量,最大功耗达到了250W,采用被动式散热方式。这款显卡不仅适用于深度学习,还能加快AI高性能设计和图形技术。



二、Tesla V100 SXM2 16G 显卡参数
Tesla V100 SXM2 16G 显卡是一款发布于2017年的显卡,它是基于NVIDIA Volta架构,采用12nm工艺 ,拥有5120个CUDA核心,搭配16GB的HBM2显存,显存位宽达到了4096bit,数据处理能力强大。并且它还带有640个Tensor核心,能极大加快AI和机器学习的运算速度,在深度学习领域表现尤为出色。需要考虑就是入手用户个人的动手,手搓能力如何了,毕竟你得折腾。


不过V100作为专业计算卡,虽可运行游戏,但性价比和体验远不及同代GeForce产品,更适合用于深度学习、科学计算等领域。若用户主要关注游戏性能,应优先考虑其他显卡型号。


二手平台上的 Tesla V100 16G 显卡都是 SXM2 版本的,需要搭配 PCIE 转接卡才能用在家用 PC 主板上,PCIE版本的显卡价格会贵上不少,而且不符合垃圾佬捡漏和折腾的精神宗旨。


如果你主要用于个人的AI服务器搭建、深度学习训练等工作,那么这款不到600元的二手拆机NVIDIA Tesla V100 SXM2 16G显卡,搭配pcie转接卡,绝对是性价比之选。

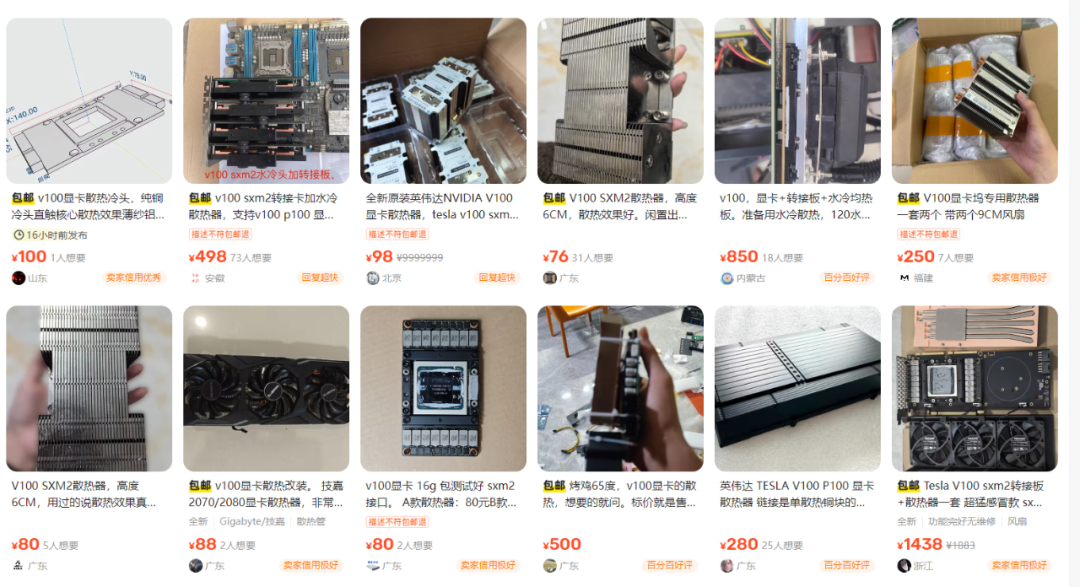
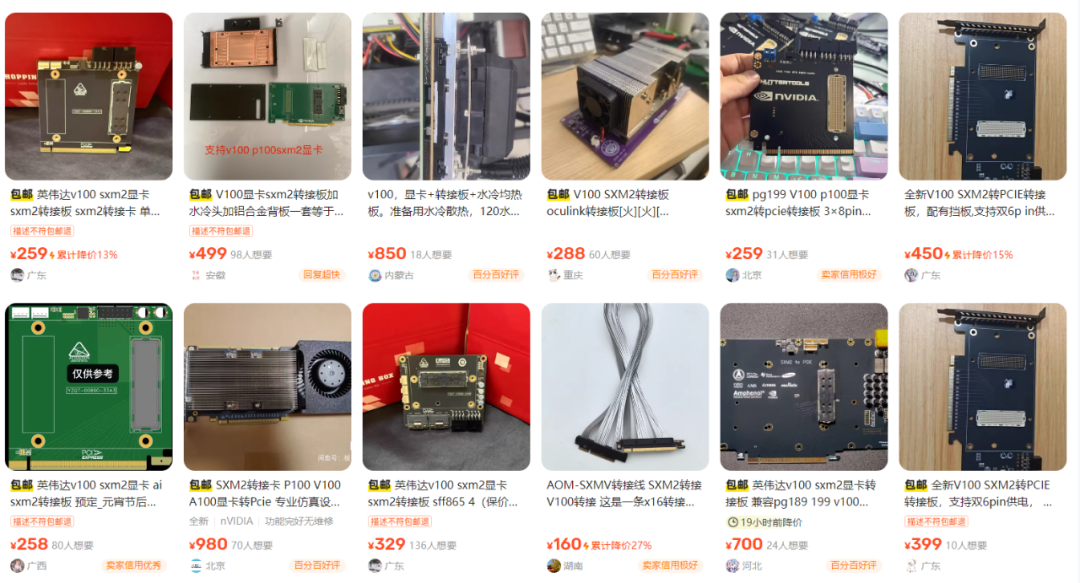
虽然它在游戏等方面不如RTX 3080,但在专业计算领域的表现足以让人忽视这一点。不过在入手二手卡时,也要注意检查显卡的状态和兼容性,确保能够稳定运行。

三、Tesla V100 SXM2 16G 显卡价格
目前某鱼上Tesla V100 SXM2 16G 显卡价位为595元,大多在599元,价位如今还是比较坚挺,这还是其手搓前的显卡价位,如果搞好价位应该接近千元,较好的用料的手搓配件肯定是超过了千元水平,当然也有手搓好的成品在售,网络上如今可找到不少大佬的手搓分享实战教程。
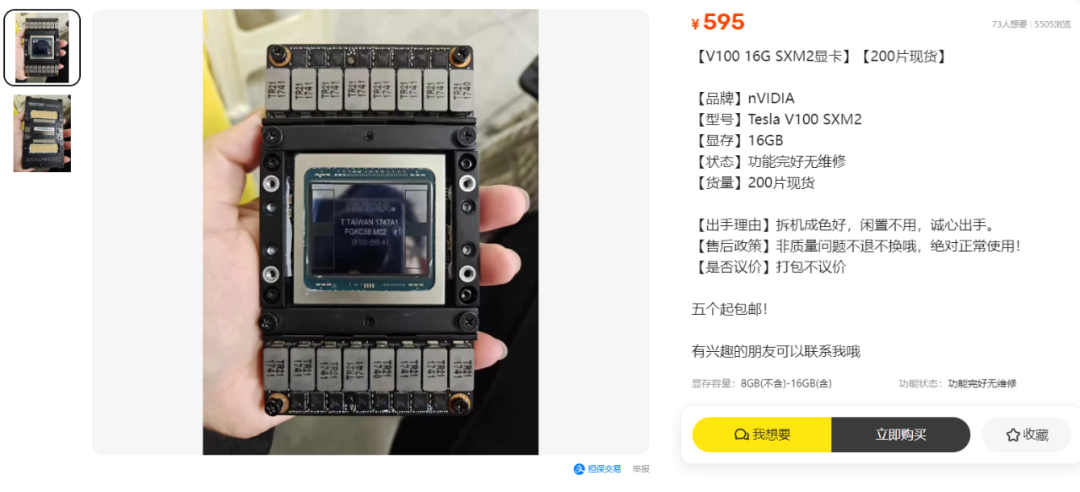
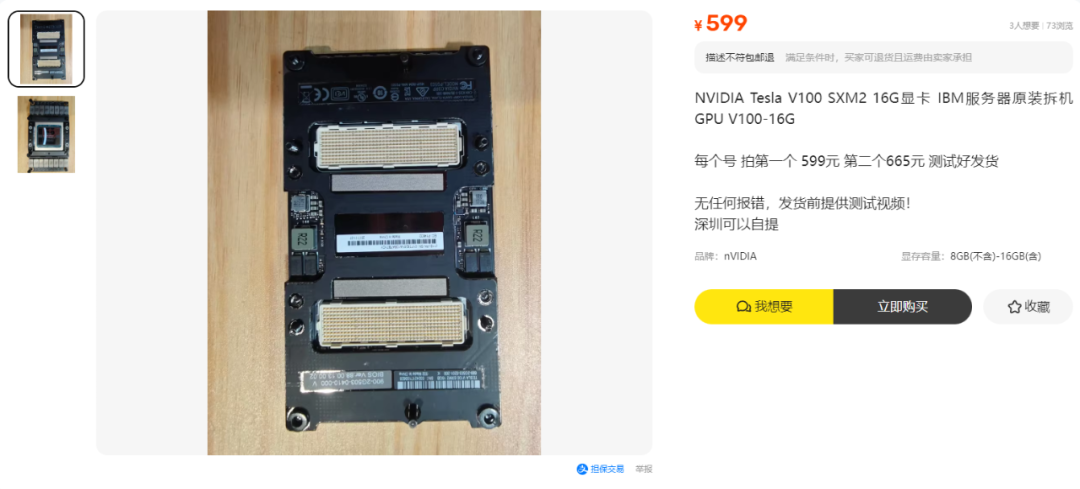
需要说明的是,大船靠岸的时候,刚流出的话,价位仅350元,有大佬就捡漏实测分享了该款显卡,奈何性价比实在太高了,再加上AI应用的持续火热,更架不住垃圾佬的接盘,涨到如今的价位水平。
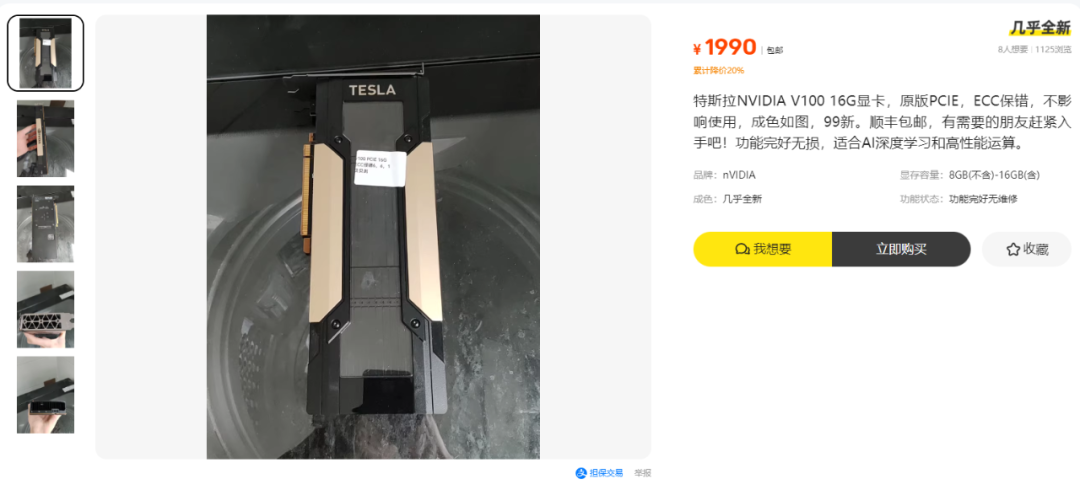
毫无疑问,这又是一款垃圾佬的毕业显卡,需要较强的手搓动手能力,同时卡几乎无售后或者质保期极短,如果不是主打AI的老哥,还是谨慎入手吧!
以上仅一家之言,仅供参考!
往期精彩:
当下现役显卡推荐游戏性能排行榜(AMD篇)!
DIY电脑垃圾佬的最爱——“钉子户”E3神教装机配置清单推荐!

DIY电脑垃圾佬的最爱——低价(高性价比)装机配件推荐!


渣渣手残党DIY装机必备软件工具教程推荐!
往期手残记录:
DIY组装电脑踩坑,手残党DIY装机分享!

老爷“鸡”升级小记!

假装是个电工,记一次家用监控安装之旅

·················END··················

扫码添加后可拉DIY交流群!

你好,我是菜鸡@搞机子,
革命老区外出进城务工人员,
IT垃圾佬、喜欢数码、捡垃圾、DIY电脑...
公众号不挣钱,交个朋友。


扫码关注,滴,学生卡;
老司机,快上车;
关注我,三千预算进图吧,学校对面开网吧!



















 1342
1342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









