







文章目录
1. libtoch 的简介与安装
- libtorch是pytorch的C++版本,可以将pytorch的代码尤其自定义算子,通过libtorch迅速实现为C++版本的自定义算子,从而快速的实现模型部署的验证工作;具体流程可以参考如下方式:
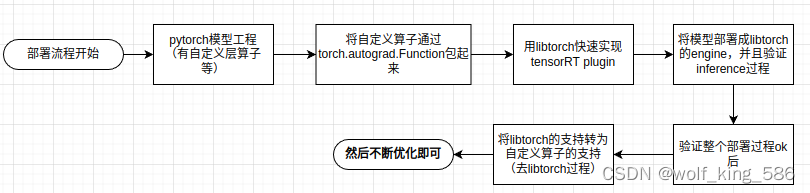
1.1 libtorch官方下载
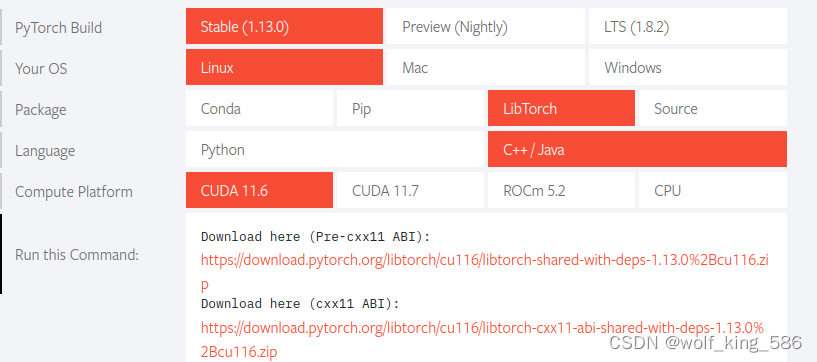
- 注意有两个版本: 一个是支持C++03规范(Pre-cxx11 ABI),一个支持c++11规范(cxx11 ABI)
- 这两个版本在进行编译的时候,需要通过设置_GLIBCXX_USE_CXX11_ABI 宏定义来控制我们使用什么规范的libstdc++.so (当旧版(c++03规范)的libstdc++.so,和新版(c++11规范)的libstdc++.so两个库同时存在,我们根据自己下载的libtorch是哪个ABI规范的就要用哪个,并且是通过设置_GLIBCXX_USE_CXX11_ABI来实现选择的) 。为了避免两个库到底选择哪一个的麻烦,GCC5.1就引入了-D_GLIBCXX_USE_CXX11_ABI来控制编译器到底链接哪一个libstdc++.so
扩展说明1: 在GCC5.1发布的同时,为libstdc++添加了新的特性,其中也包括了std::string和std::list的新实现。这个新的实现使得两者符合了c++11的标准,具体来说是取消了Copy-On-Write。那么,这样子虽然符合了c++11的标注,旧版不就无法兼容了吗。为了避免上述混乱,对于旧版而言,GCC5.1添加了__cxx11命名空间,GCC5.1或者说c++11规范下的string和list,实际上是std::__cxx11::string和std::__cxx11::list,所以我们一般的using namespace std就会变成形如using namespace std::__cxx11的样子。也就是说,有旧版(c++03规范)的libstdc++.so,和新版(c++11规范)的libstdc++.so两个库同时存在。
1.2 libtorch CMakeLists配置
-注意 implicit declaration of function ‘XXX’:未申明的引用的错误,通过-D_GLIBCXX_USE_CXX11_ABI=0来控制
set(Torch_DIR "path/to/libtorch/share/cmake/Torch")
find_package(Torch REQUIRED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++14 ${TORCH_CXX_FLAGS}")
add_definitions(-D_GLIBCXX_USE_CXX11_ABI=0) # 使用旧版stdlibc++.so库, 如果有问题就改为=1
# target_link_libraries(${PROJ} ${TORCH_LIBRARIES})
2. libtorch中常用函数写法
2.1 libtorch与 std::vector/数据指针等数据量的转换
- tensor与vector的转换,是通过数据的指针来完成的
// 一维
std::vector<float> vec;
torch::Tensor tensor = torch::tensor(vec);
// 二维
vector<float> data2dTo1d(const vector<vector<float>>& vec_vec) {
vector<float> vec;
for (const auto& v : vec_vec) {
for (auto d : v) {
vec.push_back(d);
}
}
return vec;
}
vector<float> vec = data2dTo1d(your2Dvector);
// 写法1:
torch::Tensor t = torch::from_blob(vec.data(), {n,m});
// 写法2:
// at::Tensor p_feat = at::tensor(vec, torch::kFloat32).to(device);
/***: 写法3
vector<int> v={1,2,3,4};
at::TensorOptions opts=at::TensorOptions().dtype(at::kInt);
c10::IntArrayRef s={2,2};//设置返回的tensor的大小
at::Tensor t=at::from_blob(v.data(),s,opts).clone();
*/
// tensor --> vector
at::Tensor t=at::ones({3,3},at::kInt);
std::vector<int> v(t.data_ptr<int>(),t.data_ptr<int>()+t.numel());
// data ptr
float * ptr;
cudaMalloc(ptr, sizeof(float)*N);
torch::DeviceType devicetype;
if (torch::cuda::is_available()) {
std::cout << "CUDA available! Training on GPU." << std::endl;
devicetype = torch::kCUDA;
}
torch::Device device(devicetype);
// torch::Tensor t = torch::from_blob(ptr, {N, }, device=device);
// torch::TensorOptions option(torch::kFloat32);
// auto img_tensor = torch::from_blob(img.data, { 1,img.rows,img.cols,img.channels() }, option);//
float* ptr = tensor.data<float>();
2.2 python与C++对照写法
Note: 官方pytorch对比C++的写法; 如果需要什么函数使用,可以参看官网,然后对照的改写; 这个过程特别需要举一反三能力和类比能力。 注意示例中的写法根据版本更新可能会有变化,仿照写即可。
- torch::Tensor是类型, torch::tensor函数;
- 注意libtorch很多都是std::initialized_list的写法,也就是用大括号{}将序列tensor包起来的写法;pytorch中则用中括号括括起来;
- 注意libtorch中一些多返回值的是
std::tuple<torch::Tensor>,有些是std::vector<torch::Tensor> - 当pytorch中传入None或者tensor时,通过判断是否为None即可,但是C++可以,你需要声明一个空的tensor来模拟python中的None; (torch::Tensor None; 传入函数后,用torch.tensor.numel()是否为0判断)
| ------------ | pytorch 写法 | libtorch写法 |
|---|---|---|
| tensor size | size=torch.tensor.size() | c10::ArrayRef size = torch::tensor.sizes() |
| slice | t = torch.tensor.slice(1,2,4) | auto x = torch::tensor.slice(1, 2, 4) |
| .cuda() | t = torch.tensor(2,4).cuda() | t = torch::tensor({2,4}, at::kCUDA); |
| cuda().long() | t= torch.tensor(2,3).cuda().long() | t= torch::tensor({2,3}, at::device(at::kCUDA).dtype(at::kLong)); |
| to(“cuda:1”) | t= torch.tensor(2,3).to(“cuda:1”) | t= torch::tensor({2,3}, at::device({at::kCUDA,1})); |
| print tensor} | print(tensor) | std::cout << torch::tensor << std::endl; |
| index_select | – | torch::Tensor b = torch::index_select(a, 0, indices); |
| 多个输出 | x,y = torch.tensor.max(a,1) | std::tuple<torch::Tensor, torch::Tensor> max_cls = torch::max(a,1); auto max_v=std::get<0>(max_cls); auto max_idx=std::get<1>(max_cls); |
| where | – | std::vectortorch::Tensor index = torch::where( x >= 10); |
| cat,stack等函数 | – | torch::Tensor x = torch::stack({a, b}, 1); |
| permute | – | torch::Tensor x_ = x.permute({1,0,2}); |
| 类型转换 | – | torch::Tensor x = x.toType(torch::kFloat); |
| split | – | std::vectortorch::Tensor> y = torch::split(x, 1, 1); |
| A[mask] <–> torch::masked_select(A, mask) | A[mask] = B[mask] | A = torch::_s_where(mask, B, A); |
| 是否为空tensor | — | if(torch::tensor.numel() == 0) 是否为空 |
| 切片1 | c = a[1::2] | at::Tensor c = a.index({Slice(1, None, 2)}); 需要include torch/script.h,using namespace torch::indexing; |
| 切片2 | tensor[…, 1:] | tensor.index({“…”, Slice(1)}); |
| 切片3 | tensor[…, :2] | tensor.index({“…”, Slice({None, 2})}); |
| 取index | tensor[torch.tensor([1, 2])] | tensor.index({torch::tensor({1, 2})}); 注意大括号 |
| 切片赋值1 | tensor[1, 2] = 1 | tensor.index_put_({1, 2}, 1); |
| 切片赋值2 | x[…, 1] = 100 | x.index_put_({“…”, 1}, 100); |
- mask操作2
/**
//python
a = torch.randn(3, 3) # 创建shape为3*3,值为[0,1]的随机数的tensor-float类型
b = torch.tensor([0, 1, 0]).bool() # 创建bool值向量,最终的结果是对应行向量的取舍
c = torch.tensor([0, 1, 0]).long() # 注意这里不是bool值,最终的结果只是按行(值)索引
a1 = a[b] # 按掩码操作
a2 = a[c] # 按索引操作
*/
// C++
torch::Tensor value = torch::randn({3,3}); // 被操作的tensor
torch::Tensor x = at::tensor({0,1,0}).toType(at::kBool); // bool型掩码向量,注意tensor类别要bool类型
torch::Tensor y = at::tensor({0,1,0}).toType(at::kLong); // 非bool型则按值索引(这里的索引用tensor必须是long, byte or bool类型的)
torch::Tensor value1 = value.index({x}); // bool类型按掩码操作
torch::Tensor value2 = value.index({y}); // 非bool类型按行索引
- 注意permute使用
/**
permute不会改变tensor 的data指针内数据的顺序
但是调用contiguous之后会改变。
*/
tensor_image = tensor_image.permute({2,3,0,1});
tensor_image = tensor_image.contiguous();
3. 实际用例
3.1 写测试用例测试libtorch函数
在写实际用例测试按照libtorch复习的pytorch自定义算子时,需要保存这个算子pytorch的输入输出,来验证libtorch算子是否编写正确,需要注意,保存的时候,f.write 二进制保存或者使用numpy.tofile()去保存二进制;而不是用numpy.save(“*.npy”), 因为npy不是标准的二级制文件格式,C++读取npy可能有问题,会多出32个数。
3.2 用libtorch实现tensorRT的plugin
3.2.1 libtorch与nvidia的DeviceType冲突
主要原因是编译顺序导致,libtorch中头文件里的DeviceType使用的时候,没有显性的指明namespace,而是在开始的时候用namespace at/c10 {}括起来,从而是的与tensorRT中的nvinfer1::DeviceType 冲突ambiguous
有哪些冲突就把libtorch的那些冲突的head文件中 DeviceType前面加上c10::或者at::即可,总共冲突的文件不太多,手动改就好。
DeviceType --> c10::DeviceType
4. reference
- [1] libtorch踩坑记录
- [2] CSDN博客-c++ 部署libtorch 时对Tensor块的常用操作API
- [3] libtorch Tensor张量的常用操作
- [4] _GLIBCXX_USE_CXX11_ABI有什么作用
- [5] libtorch与vector之间的转换
- [6] torch与libtorch对比


















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









