







原文链接:使用模拟方法玩转统计推断 https://mp.weixin.qq.com/s/bUSE2JY4M9knTMCjJwXNWw
https://mp.weixin.qq.com/s/bUSE2JY4M9knTMCjJwXNWw
统计推断主要涉及四个指标[1]。简单来说,它们是α、1-β(统计功效)、效应量和样本量,其中统计功效和效应量相对比较抽象。
本文将继续深入学习上一篇文章中所讲的模拟方法,通过R语言编程的方式,阐释统计功效和效应量的具象含义。
统计功效又名统计检验力。假设某种处理能够产生某种效应,那么通过一次抽样操作能够检测到这种效应的概率就是其含义了。
统计功效还有一个名称,叫“真阳性率”。当零假设H0为假时,只要样本的数量无限接近总体的数量,那么肯定的一个结果是H0会被拒绝。
然而,实际情况是,抽样的数量很有限,而且抽样难免会产生误差,因此抽样结果有时会正确拒绝H0,有时又会落入误区(下图蓝色β区域)[2]。
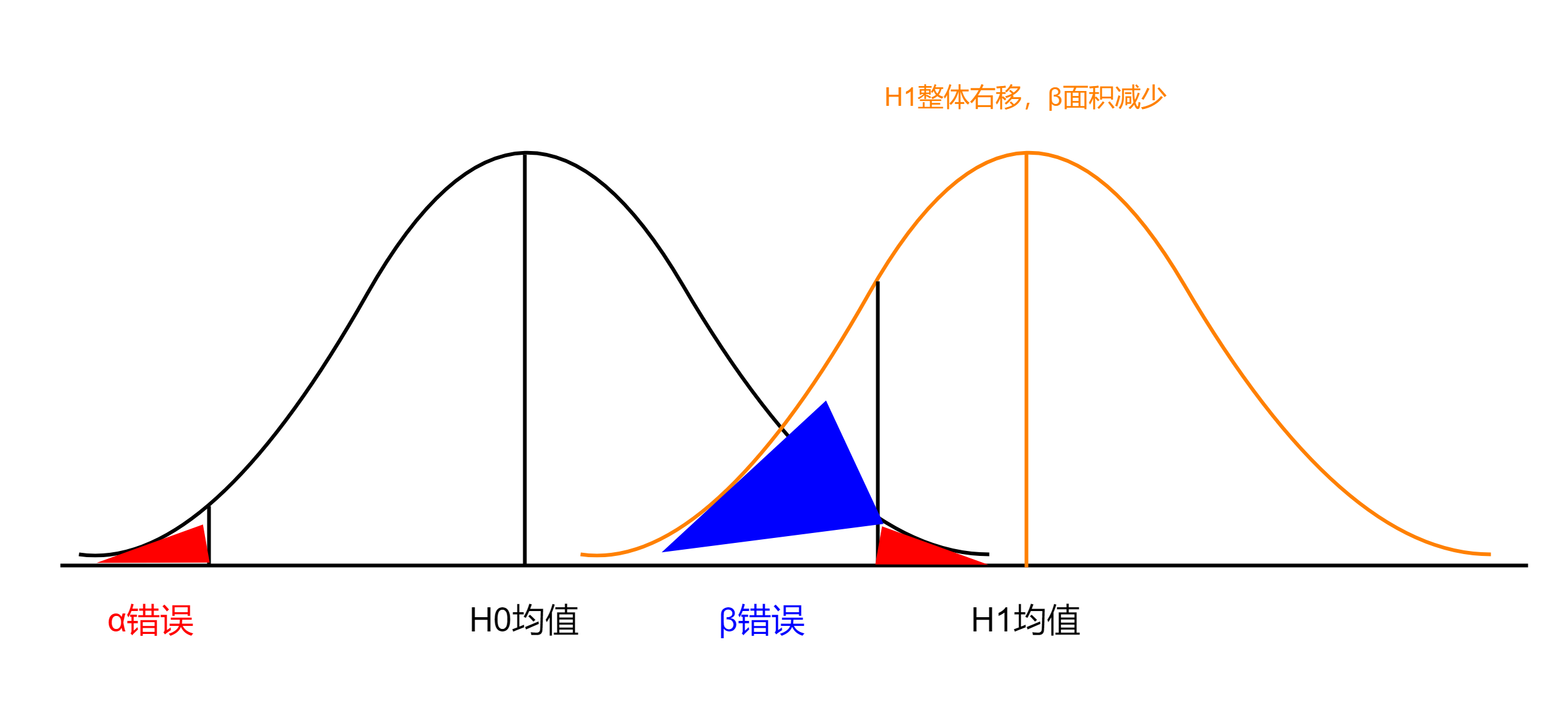
在所有的抽样次数中,正确拒绝H0的次数所占的比例即是真阳性率。如果能够在80%的情况下拒绝错误的零假设,意思是说它的统计功效是80%。
心理学研究经常使用G*Power来进行功效分析和样本量计算。不过,说是功效分析通常通过模拟来完成,特别是对于非实验研究[3]。
这让人想到通过计算机模拟打点计算圆周率的方法。边长为1的正方形有一内切圆,按随机打点位置在四分之一圆弧内还是外,通过面积比例计算得到π的估计值。
功效分析会遇到一些现实困难。除了小效应外,还有自变量本身变异不大、因变量噪声太多(受其它因素影响)以至于信号难以提取,以及追求苛刻的估计效应值的标准误。
好在这几个问题能够通过增加足够的样本量来解决。至于到底需要多少的样本量,是可以通过所设定的统计功效和效应量计算出来的。
效应量即真实效应值,例如回归分析中的预测因子系数。
为了更加具体地了解概念,还得结合例子进行说明。假设我们想研究阅读训练计划(X)对儿童阅读成绩(Y)的影响,还关心该效应是否会因性别(M)而异[3]。
我们先从上帝的视角来展示下“真实数据”:X的回归系数为3.6,M的回归系数为0.6,X和M交互作用的回归系数为1.2,Y的标准差为8。
对于其它一堆可能会影响测试分数的因素,我们统一打包到一个控制变量S里。并且设定S每增加一个标准差,相应地Y会平均增加5个单位。
而且S也会对自变量X产生影响:S每增加一个标准差,接受训练的可能性则会减少11%。
要是用回归方程来表示以上设定,那就是Y = β0 + 3.6*X + 0.6M + 5*S + 1.2*M*X + rnorm(N, sd = 8),其中rnorm()函数用于在模拟数据过程中生成误差项。
--逐步编程--

上图是根据前面一篇文章[4],对模拟方法的使用流程作了梳理。以下的例子演示与这个流程基本相同,只是最后一步检验的是效应量和样本量。
在模拟中要如何提取功效值呢?从操作定义的角度看,统计功效等于是抽样结果中具有统计显著性的比例。
因此在编程中要增加一个二进制变量,用于存储效应是否显著的结果。这里的是否显著指的是非零检验的结果,即参数估计值的置信区间是否包含零。
就本文的例子来说,指的是X和M两者交互效应的系数估计值是否显著。其是否显著的结果要从模型拟合结果中读取,上篇文章已讲到可以使用broom包的tidy()函数。
tidy()函数能够从模型信息中提取出整洁的结果,其输出为tibble类型,方便访问具体的结果值(见下图)。
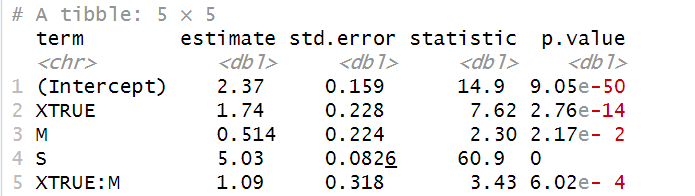
其实到目前为止,前期的准备工作已完成。接下来可以参照上一篇文章的内容,完成自定义函数的编写,用于模拟生成一份样本数据(代码如下)。
##模拟采样函数##
#参数B4指交互效应系数
d_sample <- function(N, B4) {
S = rnorm(N) #混杂因素
M= sample(0:1, N, replace = TRUE) #性别
d_temp <- tibble(S, M) %>%
#根据S对X的影响关系生成数据
#接受阅读训练的比例不到一半
mutate(X = runif(N) + .11*S < .5) %>%
#假设截距值为2.3
mutate(Y = 2.3 + 3.6*X + 0.6*M + 5*S + B4*M*X + rnorm(N, sd = 8))
return(d_temp)
}上面自定义函数有一个B4参数,它是指交互作用的效应量。虽然前面已设定其真实值为1.2,不过后面我们要对它进行操纵试验,此处用参数能够保留调整的灵活性。
下一步是根据生成的样本数据,通过线性拟合方法估计模型参数,同时获得显著性结果。这里我们只关心交互效应是否显著,最终用于计算真阳性率(即统计功效)。
##返回交互效应是否显著##
r_sig <- function(N, B4) {
d_onetime <- d_sample(N, B4)
#第一个参数formula默认带常数项β0
# X*M等价于X+M+X:M(冒号表示交互项)
m_fitted <- lm(Y~X*M + S, data = d_onetime)
#模型转tibble
m_tidied <- tidy(m_fitted)
#第五行对应B4系数
r_temp <- m_tidied$p.value[5] < .05
return(r_temp)
}一切准备就绪,现在可以用上火力了——通过迭代方法生成任意数量的样本。例如生成1000份样本,每个样本的大小为2000,分别对应下边r_iterate()函数的count参数和N参数。
##迭代调用##
r_iterate <- function(N, B4, count) {
r_temp <- 1:count %>%
#参数x表示当前迭代
map_dbl(function(x) {
#输出进度
if (x %% 100 == 0) { print(percent(x/count)) }
#返回是否显著结果
return(r_sig(N, B4))
})
#均值即功效值
return(mean(r_temp))
}r_iterate()函数会计算1000份样本中,交互效应结果显著的比例。
要是保持B4和count参数不变,仅去调整N,就可以获得不同的功效值。反过来说,假设我们对功效的期望值是80%,那么只需通过反复多次试验就能找到最小的N值。
##寻找最小样本量##
r_effect <- tibble(N = c(2000, 4000, 6000))
#创建power列,存储不同样本量下的效应值
r_effect$power <- c(2000, 4000, 6000) %>%
#第一个参数N由前面的向量逐个传递进来
map_dbl(r_iterate, B4 = 1.2, count = 1000)
r_effect
上图显示,6000份样本时,效应量已接近82%。
还有最后一个问题就留给各位自己做试验啦~
当样本数量和样本大小保持不变,如何通过前面预留的B4参数,去获得不同交互效应下不同的统计功效呢?
参考文章:
- 到底需要多少样本量
https://mp.weixin.qq.com/s/Ate4y3GiwOw_KQWIq8DV7A - 从样本量计算到元分析——有效应量、有随机效应模型
https://mp.weixin.qq.com/s/UlXDAoQtT7oczY6pJwm9YQ - The Effect: An Introduction to Research Design and Causality
https://theeffectbook.net/index.html - 模拟生成因果关系数据
https://mp.weixin.qq.com/s/YL3_kuEsNdhAjhxFAguC1g


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









