







原文链接:知识点之Logistic回归和效应量 https://mp.weixin.qq.com/s/y9QVUyR7K1id5d6O09aTuQ
https://mp.weixin.qq.com/s/y9QVUyR7K1id5d6O09aTuQ
Logistic回归和效应量在前面的文章中已有所学习,见:广义线性模型之Logistic回归、看文献之期望和记忆如何影响经济决策(重复测量方差分析部分)、到底需要多少样本量(效应量部分)。这次对困扰本人的一些难点重新查阅了些资料,借机做进一步的思考和探讨。
Logistic回归
Logistic回归有翻译成逻辑回归,跟其最常适用的二分类任务倒是匹配,因为逻辑型变量的值要么是TRUE要么是FALSE。Logistic回归属于广义线性模型家族的一员,它重用了线性回归的基础架构,是使用Logistic函数作为连接函数。Logistic函数也叫sigmoid函数(机器学习领域的叫法)、S函数(因其S型曲线的缘故),其横轴x的取值范围是整个实数,纵轴y的值域为[0,1],可见下图(来自参考文章1)。
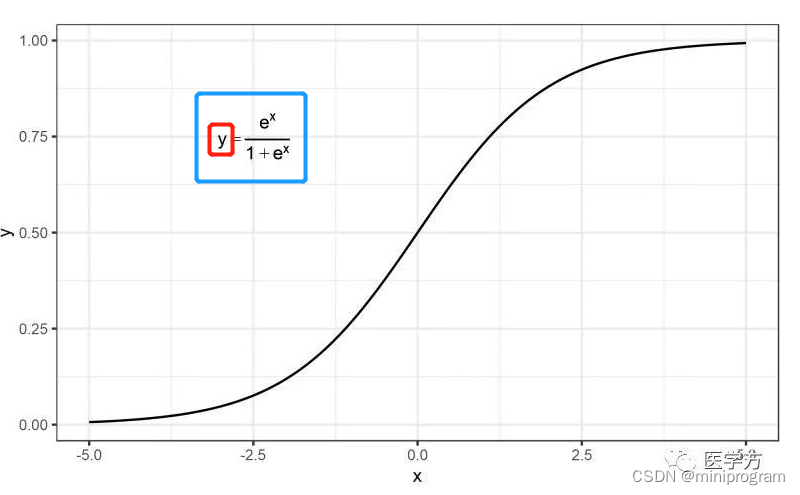
这里为什么需要加上Logistic连接函数呢?因为此时的应变量为二分变量,而线性回归方程应变量的类型为连续型实数,藉由构建新的回归方程(把原先方程的右边放入上图蓝框部分的x处),y值被限定在0到1的闭区间。要是设定某个阈值(比如0.5),并规定预测值大于0.5我们就判别预测结果为1,反之结果为0,于是就完成了符合需求模型方程的构建。进一步对公式进行转换,右边只留下x部分,形式与线性回归方程变得一致,结果如下(来自参考文章1)。
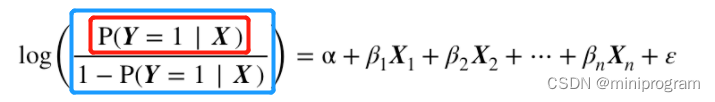
在研究二分问题时,我们通常关心的是阳性结果(表示存在,如参考文章2中的出轨),在给定样本X的情况下结果为阳性的概率可以表示为P(Y=1|X),见上图公式中的红框部分,也即原先公式中的y。而蓝框内容中的比值称作几率(Odds,见参考文章2),即结果为阳性的相对可能性。再取对数就是拟合方程所要预测的值了。
还有一个问题是,原始数据中二分类型的应变量(例如:1表示出轨、0表示未出轨)要如何代入方程进行模型拟合呢?或者问P(Y=1|X)是怎么凭空出来的呢?参考文章3给出了解释和答案。我们把单个样本的预测结果看成是一个事件,那么这个事件发生(即阳性)的概率为P(Y=1|X),不发生的概率P(Y=0|X)就等于1-P(Y=1|X),等价于函数P(yi|xi)=pyi(1-p)1-yi(方便计算yi的概率:y为1时结果为p,y为0时结果为1-p),再列出一组样本总概率的方程,最后通过极大似然法(先要计算总概率最大时的p值)求得模型参数。
效应量
效应量是衡量处理效应大小的指标,例如两种实验处理总体均值的差异大小。Cohen' d是标准化后的效应量(见参考文章4),在t检验中比较常见,其数值是实验组的均值减去控制组的均值再除以两组混合后样本的标准差。而在方差分析中会选用处理变异与总体变异的比值,来反映处理效果的大小,其中η2(读作Eta方)最为常见,它使用样本平方和来估计效应量,例如因素A的效应量η2A=SSA/SST。为了排除因素A的效应量受到其它因素的影响,可以使用偏η2A,其值为SSA/(SST+SSE)。有些文献只报告F值,不过可以利用等价的公式计算偏η2A,见下图(来自参考文章5)。

另外,在模型拟合方法中会涉及拟合优度(如G2)的χ2检验法,它根据样本的经验分布和所假设的理论分布的吻合程度来决定是否接受原假设,这与列联表的卡方检验原理是一致的(见参考文章7最后部分),都是根据不同的自由度来比较卡方值和临界值的大小(计算方式见下图红框部分,来自参考文章6)。
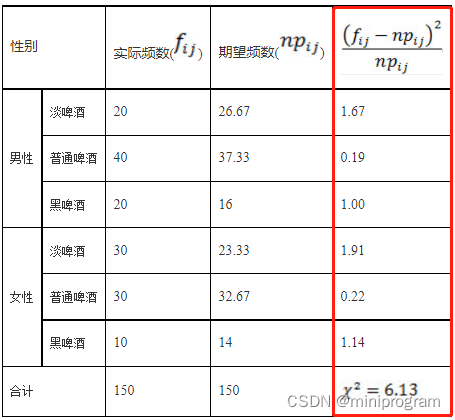
相应地,在文献中我们会看到其效应量用w来表示,其含义见下图(来自参考文章8)。P0i是指拟合的模型(零假设)所预测的每小格期望值(相对频数,这里是比例),P1i是指每小格的实际观测值所占的比例(对应不同模型,即备择假设),m指所有格子的数目。

从上图公式,我们可以看出w2的计算方式与χ2值的计算相类似,w值越大表示拟合效果越差,其效应量大小的参考指标如下(来自参考文章8)。

彩蛋:tidyverse包
tidyverse实际上是一个整合包,它包括下图中所列的这些包,它们基本上是R中基础安装包的升级款。ggplot2包的绘图功能详见参考文章10。dplyr包主要用于数据的筛选、分组和汇总等操作,它是plyr包的升级版,这两个包在参考文章11中有示例代码。tidyr包也是用于数据整理,其中有相应的函数来帮助我们进行长/宽数据格式的转换。
tibble包是data.frame的升级款,它能根据屏幕大小恰当地展示数据,隐藏行列的概要信息会在下方显示,如下图所示。除了显示数据有多少行和多少列,它还显示了每一列变量的数据类型,例如:dbl(double)表示双精度浮点数、fct(factor)表示变量为因子类型。
readr包用于读取/输出文本数据,说是比传统的read.table()方式效率更高。stringr包用于字符串的处理,forcats包用于处理因子类型的变量(例如排序操作),purrr包用于循环迭代(即依次在向量或列表的每个元素上做相同的操作),这些包先做初步了解,后续待研究。
参考文章:
- 一文读懂logistic回归的前世今生
https://www.sohu.com/a/270954377_777125 - [本公号文章]广义线性模型之Logistic回归
- 逻辑回归 logistics regression 公式推导
https://zhuanlan.zhihu.com/p/44591359 - [本公号文章]到底需要多少样本量
- 解读方差分析中的效应量(Effect Size),检验力(Power)和样本量
https://zhuanlan.zhihu.com/p/137779235?utm_source=qq - 拟合优度检验(自由度)
https://blog.sciencenet.cn/blog-3428464-1241961.html - [本公号文章]初探R之数据结构和列联表
- [图书]Statistical Power Analysis for the Behavioral Sciences (2nd Edition) Chap.7
- r语言psych包_R语言 | Tidyverse包入门介绍
https://blog.csdn.net/weixin_31523833/article/details/113414818 - [本公号文章]高级绘图之ggplot2包
- [本公号文章]看文献之期望和记忆如何影响经济决策

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









