









网上信息海量,多数人认为这些信息都是垃圾,实际上使用一些技术手,完全可以为公司筛选出有用的内容。开发一个企业竞争对手跟踪系统有非常实际的意义,主要包括以下几个部分:
1. 实时获取竞争情报
2. 优化决策和战略规划
3. 提前识别市场趋势
4. 提升业务敏捷性
5. 降低风险和避免失败
6. 提高市场定位和创新能力
7. 增强企业核心竞争力
今天我们主要来介绍这个系统开发的流程和技术实现,上面这些就不展开讲了,反正就是 辅助决策,提升企业核心竞争力。这看起来很空,但真地用好了,是很有价值的。
我们先来规划一下这个系统的流程:
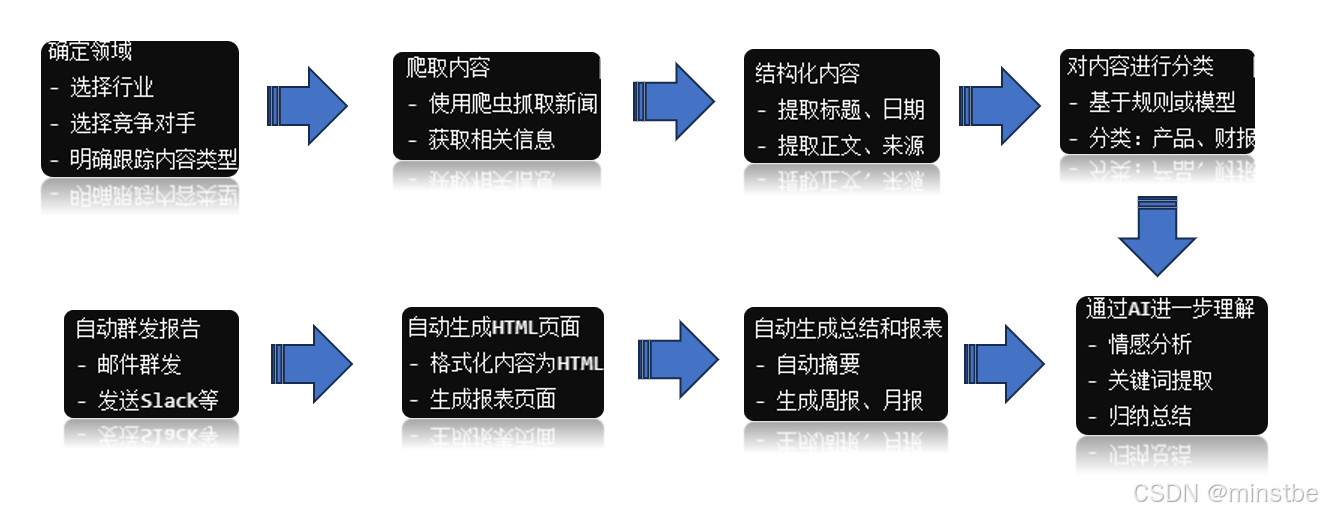
流程简述:
- 确定领域:选择要跟踪的竞争对手、行业以及要跟踪的内容类型(如新闻、产品发布等)。
- 爬取内容:通过爬虫抓取相关新闻或信息。
- 结构化内容:对抓取的数据进行结构化处理,提取重要信息,如标题、发布时间、正文等。
- 对内容进行分类:将内容分为不同的类别,如“产品发布”、“财报”、“市场动态”等。
- 通过AI进一步理解和归纳:使用AI模型进行更深层次的分析,如情感分析、关键点提取等。
- 自动生成总结和报表:根据分类和分析结果,自动生成简要总结和周期性报表。
- 自动生成HTML页面:将报表和总结转换为HTML格式,生成可视化的页面。
- 自动群发报告:通过邮件、Slack等自动将生成的HTML报告发送给相关人员。
这可以作为一个整体框架,用于系统开发、自动化流程管理和持续跟踪的实现。
根据上面这个流程设计,我们再分别从以下几个方面进行详细阐述,并结合实际开发流程和代码示例:
1. 确定领域
首先,需要明确系统关注的具体领域。例如,竞争对手的产品发布、市场动态、财报信息、新闻报道等。这些领域会影响后续的爬取、结构化和分析。
- 业务领域:选择具体的行业(如芯片、汽车、消费电子等)。
- 竞争对手:选择要跟踪的竞争对手列表。
- 内容种类:明确需要获取的内容类型(如新闻文章、产品信息、财报)。
2. 爬取内容
爬取内容通常是通过网页爬虫来获取,可以使用 requests 和 BeautifulSoup 等库进行网页抓取。
示例代码:
import requests
from bs4 import BeautifulSoup
def crawl_competitor_news(competitor_name):
# 搜索竞争对手的新闻页面(示例)
url = f"https://www.google.com/search?q={competitor_name}+news"
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
news_links = []
for item in soup.find_all('a', href=True):
link = item['href']
if 'news' in link:
news_links.append(link)
return news_links
# 示例:爬取竞争对手 "Tesla" 的新闻
news_links = crawl_competitor_news("Tesla")
print(news_links)
这个代码段的目的是爬取包含“Tesla”相关新闻的 Google 搜索结果页面,并提取其中的新闻链接。执行代码后,返回的 news_links 变量将是一个包含所有爬取到的新闻链接的列表。具体来说:
-
url = f"https://www.google.com/search?q={competitor_name}+news"
这一行构建了一个搜索URL,搜索的是竞争对手名字(如“Tesla”)加上关键词“news”,即查询“Tesla news”相关的信息。 -
headers = {'User-Agent': 'Mozilla/5.0'}
设置User-Agent请求头,以模仿正常浏览器请求,避免被 Google 阻止。 -
response = requests.get(url, headers=headers)
通过requests.get发送HTTP请求到Google,获取搜索结果页面。 -
soup = BeautifulSoup(response.text, 'html.parser')
使用BeautifulSoup解析HTML页面内容,提取页面上的所有链接。 -
news_links = []
初始化一个空的列表news_links,用来存储新闻链接。 -
for item in soup.find_all('a', href=True):
遍历页面中所有带有href属性的<a>标签,意味着我们正在寻找所有链接。 -
link = item['href']
提取每个链接的 URL。 -
if 'news' in link:
过滤出链接中包含news字段的链接,假设这些链接与新闻相关。 -
news_links.append(link)
将满足条件的链接添加到news_links列表中。
实际获得的结果: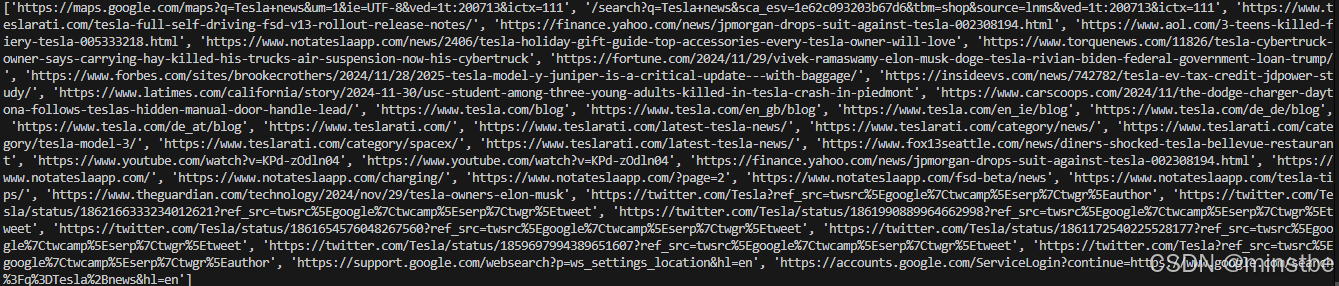
3. 结构化内容
爬取的内容往往是非结构化的,因此需要对其进行结构化处理。例如,提取标题、发布时间、正文内容、来源等信息。
示例代码:
def parse_news_content(news_url):
response = requests.get(news_url)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('h1').text
date = soup.find('time')['datetime'] # 获取发布日期
content = soup.find('div', class_='article-content').text
structured_content = {
'title': title,
'date': date,
'content': content
}
return structured_content
# 示例:解析某个新闻链接
news_content = parse_news_content(news_links[0])
print(news_content)
这段代码是用来解析网页的,因为每个网页格式不一样,所以这里只做了一个示例,可以多谢一写规则来结构化网页,也可可以用现成的大模型api去解析你的网页地址(具体可以搜一下 有一些免费方法的)
4. 对内容进行分类
爬取和结构化后,可以使用文本分类方法对内容进行分类。例如,可以使用机器学习或基于规则的方法来分类新闻内容。
- 分类类别:例如,可以将新闻分为“产品发布”、“市场动态”、“财报”。
- 工具选择:可以使用如
scikit-learn、spaCy或深度学习方法进行分类。
示例代码(使用简单的文本分类):
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
# 假设已经有一个新闻内容的列表和对应的标签
news_titles = ["Tesla releases new car model", "Tesla's Q3 earnings report"]
labels = ['Product', 'Earnings']
# 向量化文本
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(news_titles)
# 使用朴素贝叶斯分类器
classifier = MultinomialNB()
classifier.fit(X, labels)
# 对新内容进行分类
new_news = ["Tesla announces new battery technology"]
X_new = vectorizer.transform(new_news)
predicted_category = classifier.predict(X_new)
print(predicted_category) # 输出预测的类别
5. 通过 AI 进一步理解和归纳
AI 可以用来分析文本,提取关键点,或者进行情感分析等更深层次的理解。
- 工具选择:可以使用 GPT-3、BERT、TextRank 等模型进行更深的理解与归纳。
- 应用场景:例如,通过情感分析判断竞争对手新闻的情感倾向(积极、消极、中性)。
示例代码(使用 transformers 进行情感分析):
from transformers import pipeline
# 使用 Hugging Face 的预训练模型进行情感分析
classifier = pipeline('sentiment-analysis')
result = classifier("Tesla's new product is revolutionary!")
print(result) # 输出情感分析结果
6. 自动生成总结内容和报表
根据分类和理解的结果,自动生成内容摘要,并生成相应的报表。例如,可以生成每周的竞争对手报告。
示例代码(自动生成简要总结):
def generate_summary(content):
# 假设使用GPT-3或其他AI模型生成摘要
# 这里仅使用简单的文本截取
summary = content[:300] + "..."
return summary
# 示例:生成新闻摘要
summary = generate_summary(news_content['content'])
print(summary)
7. 自动内容生成 HTML 页面
根据处理后的内容,可以自动生成 HTML 页面,方便展示或发送。
示例代码(生成 HTML):
def generate_html_report(news_data):
html_content = f"""
<html>
<head><title>Competitor News Report</title></head>
<body>
<h1>Competitor News Report</h1>
<h2>{news_data['title']}</h2>
<p><strong>Published on:</strong> {news_data['date']}</p>
<div>{news_data['content']}</div>
</body>
</html>
"""
with open('competitor_report.html', 'w') as file:
file.write(html_content)
# 生成 HTML 报告
generate_html_report(news_content)
8. 自动群发给相关人员
最后,生成的 HTML 页面或报告可以通过邮件、Slack 等方式自动群发给相关人员。
示例代码(使用 smtplib 发送邮件):
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
def send_email_report(recipient, subject, html_content):
msg = MIMEMultipart()
msg['From'] = 'your-email@example.com'
msg['To'] = recipient
msg['Subject'] = subject
msg.attach(MIMEText(html_content, 'html'))
# 发送邮件
with smtplib.SMTP('smtp.example.com', 587) as server:
server.starttls()
server.login('your-email@example.com', 'password')
server.sendmail(msg['From'], msg['To'], msg.as_string())
# 发送 HTML 报告
send_email_report('recipient@example.com', 'Competitor News Report', open('competitor_report.html').read())
通过以上步骤,您可以建立一个竞争对手跟踪系统,自动化爬取竞争对手的相关新闻、结构化内容、分类、分析、生成报告并自动发送给相关人员。整个流程可以通过编程和AI技术实现自动化,从而节省人力并提高效率。
变现
开发应用后,除了可以给自己公司用,让你升值加薪之外,还可以结合用户画像、市场需求和产品特点,使之产品化、最终变现:
1. 明确目标用户群体
- 分析目标用户:基于应用的功能确定目标人群(如科技爱好者、新闻读者或特定行业的从业者)。
- 细分市场:识别不同用户群体的需求,设计不同的推广策略。
- 比如,如果是新闻类应用,可能关注特斯拉的消费者、股民、行业分析师等。
2. 制定推广策略
线上推广
-
社交媒体营销:
- 在社交平台(如微博、Twitter、LinkedIn)发布关于应用功能的内容。
- 用有吸引力的标题和简洁的视频演示应用的核心功能。
- 合作有影响力的KOL或KOC(意见领袖/消费者)推广。
-
内容营销:
- 撰写高质量的博客、新闻稿或案例分析,展示应用的独特功能。
- 提供免费的教程或操作指南,让潜在用户轻松上手。
-
广告投放:
- 使用 Google Ads、Facebook Ads 等精准投放广告。
- 选择目标受众:如关注特斯拉新闻或汽车科技的人群。
线下推广
-
行业会议与展会:
- 参加相关行业的展会,展示应用。
- 提供现场体验,收集潜在客户反馈。
-
合作推广:
- 与相关领域的企业合作,互换流量或交叉推广。
3. 用户体验优化
- 提供 免费试用或基础功能,让用户体验价值。
- 设置激励机制:
- 推荐奖励:用户邀请朋友使用后,双方获得优惠或奖励。
- 积分体系:使用应用积累积分,可兑换礼品或解锁高级功能。
4. 变现策略
-
订阅服务:
- 提供基础功能免费,高级功能或去广告版本需要订阅。
- 订阅选项如按月、按年收费,增加灵活性。
-
广告收入:
- 在不影响用户体验的情况下,嵌入定向广告。
- 使用 Google AdSense 或类似服务获取广告收入。
-
付费版本:
- 提供专业版或定制服务,针对企业用户需求。
- 可按用户数量或功能模块收费。
-
数据服务:
- 提供行业趋势分析、新闻数据导出等增值服务,向企业或研究机构收费。
-
联盟营销:
- 和其他产品合作,应用内植入合作方的服务或链接,按点击或注册收费。
5. 用户增长与留存
- 持续更新内容:例如,加入热点新闻、特斯拉行业预测等内容,增强用户黏性。
- 定期互动:
- 推送个性化消息,提醒用户使用。
- 在社交媒体上与用户交流,收集反馈。
- 运营活动:
- 举办抽奖、活动或用户挑战赛,提高用户参与度。
6. 分析与调整
- 使用数据分析工具(如 Google Analytics、Mixpanel)追踪用户行为,分析:
- 用户来源、留存率、支付转化率等。
- 根据数据不断优化推广策略和应用功能。
7. 案例借鉴
- 参考类似产品:
- 比如 Flipboard(新闻聚合)和 TeslaFi(特斯拉数据分析工具)的推广与变现方式。
- 小范围测试:
- 在一小部分市场投放,测试不同策略的效果,逐步扩展。
通过以上策略,逐步扩大用户群体,增强品牌效应,建立多元化的收入渠道,实现长期变现目标。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









