






在机器学习的广袤领域中,随机森林犹如一颗璀璨的明星,以其卓越的性能和广泛的适用性备受瞩目。今天,就让我们一同深入探索随机森林算法的奥秘。
一、随机森林的魅力之源
- 随机森林(Random Forest )是一种集成学习算法,它由多个决策树组成。其基本思想是通过构建多个决策树,并将这些决策树的结果进行综合(比如投票或者求平均)来得到最终的预测结果。在机器学习中,集成学习方法通常能够提高模型的准确性和稳定性,随机森林就是其中非常成功的代表。
- 例如,在一个判断水果是苹果还是橙子的分类问题中,单棵决策树可能会因为某些特殊的特征(如颜色稍红就判断为苹果)而出现错误。但是随机森林会综合多棵决策树的判断,降低这种因单棵树的特殊性而导致的错误。
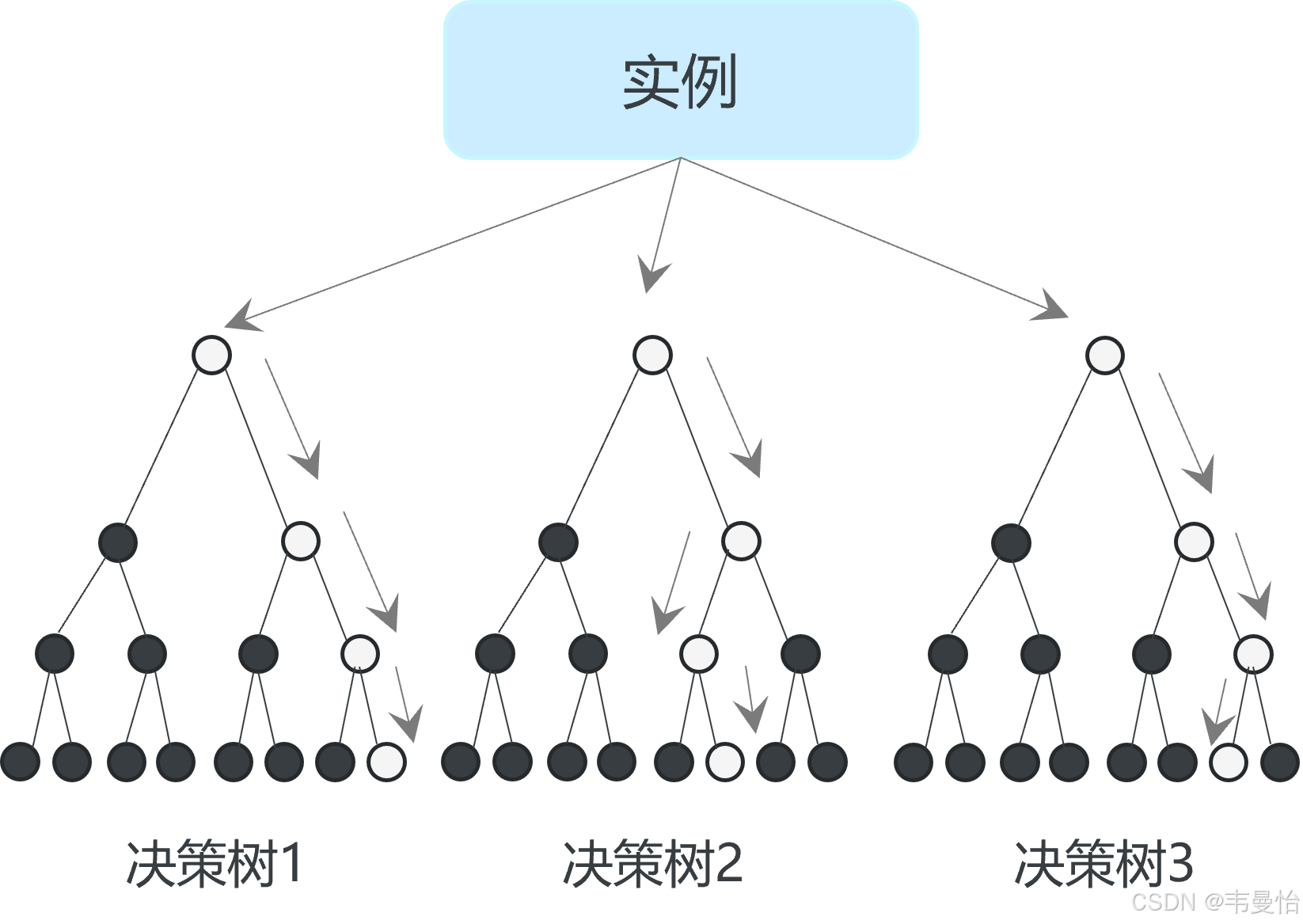
二、工作原理的精妙之处
决策树构建
随机森林中的每一棵决策树都是通过对训练数据集进行有放回的抽样这种抽样方式称为自助采样法,英文是 Bootstrap Sampling)来构建的。 。这意味着在构建每棵树时,部分样本可能会被多次选中,而有些样本可能一次都不会被选中。这样构建出来的决策树之间具有一定的差异,从而增加了整个森林的多样性。
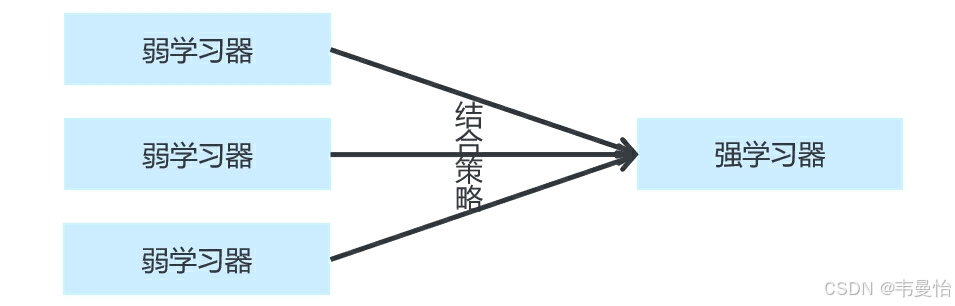
2.随机森林原理及步骤
集成算法
同质个体学习器集成学习大致分为两类,一类为并行化,如Bagging,一类串行生成,如Boosting。


随机森林
随机森林是bagging的一个特化进阶版,所谓的特化是因为随机森林的弱学习器都是决策树。所谓的进阶是随机森林在bagging的样本随机采样基础上,又加上了特征的随机选择。
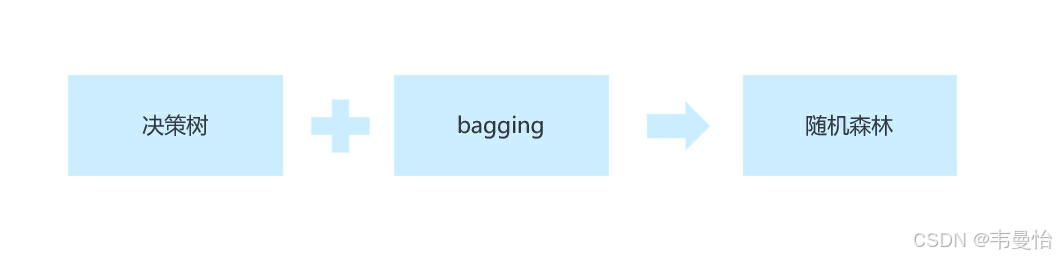
3.随机森林算法实现过程
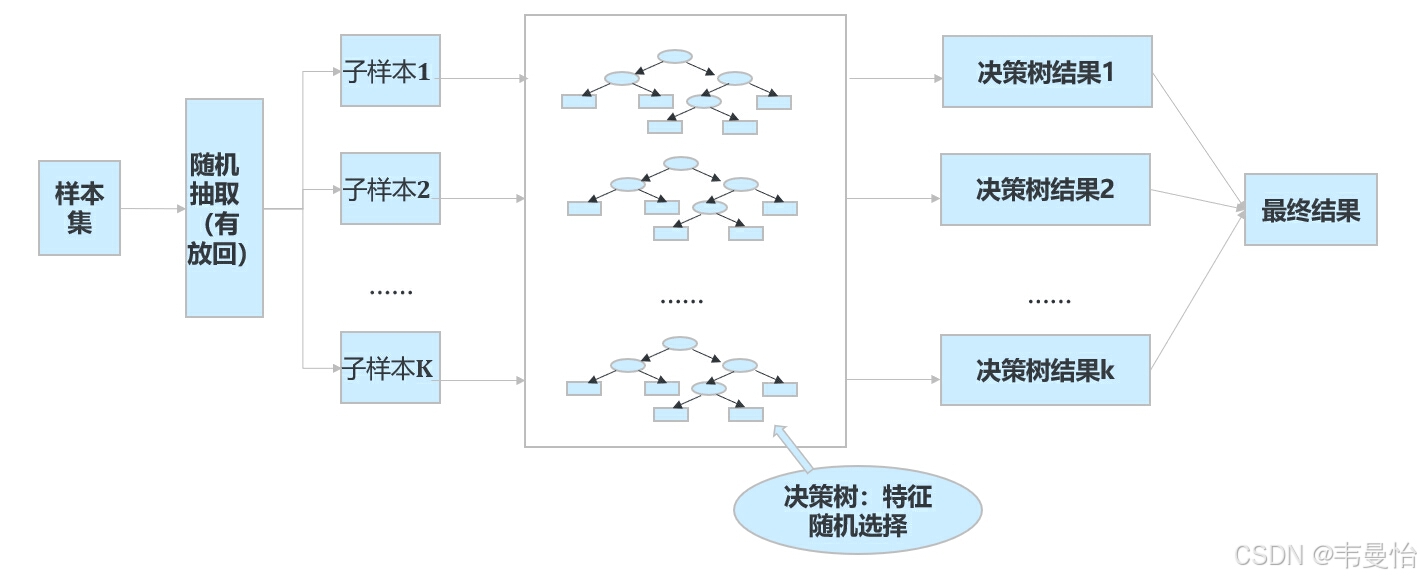
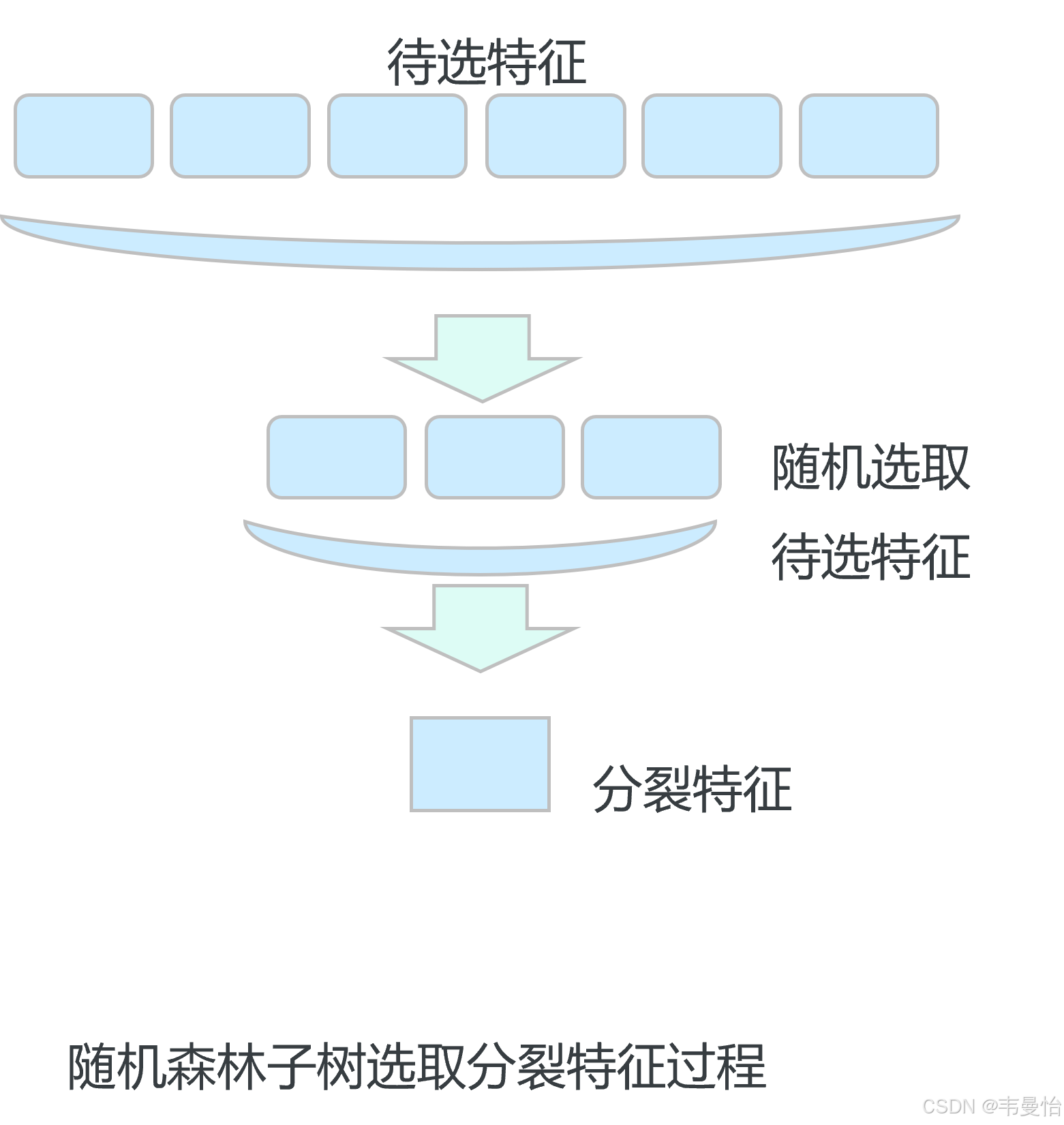
4.特征选择随机化
在构建每一棵决策树时,对于节点的分裂,不是从所有的特征中选择最优的特征进行分裂,而是从一个随机的特征子集中选择最优特征。这种随机化的特征选择方式进一步增加了决策树之间的差异,提高了整个随机森林的泛化能力。
5.预测的集成
当进行预测时,对于分类问题,随机森林通过投票的方式确定最终的分类结果。每棵决策树都会给出一个类别预测,得票最多的类别即为最终的预测结果。对于回归问题,随机森林则是取所有决策树预测结果的平均值作为最终的预测结果。
三、随机森林的优势大盘点
1.高准确性
在客户细分、市场预测、推荐系统等方面有着广泛的应用。通过分析客户的行为数据和偏好,随机森林可以帮助企业更好地了解客户需求,制定个性化的营销策略,提高客户满意度和忠诚度。
2.强鲁棒性
对数据中的噪声和异常值具有很强的容忍度。即使数据中存在一些错误或异常值,随机森林也能够通过综合多个决策树的结果来降低这些异常值的影响,从而保持较高的准确性。
3.处理高维数据的能力
能够轻松处理具有大量特征(高维)的数据。在构建每棵树时的随机特征选择步骤在一定程度上起到了特征选择的作用,使得随机森林能够自动选择对预测结果最有帮助的特征,而不需要进行复杂的手动特征选择。
4.易于并行化
随机森林的构建过程可以很容易地进行并行化,因为每一棵决策树的构建都是独立的。这使得随机森林在处理大规模数据时具有很大的优势,可以利用多核处理器或分布式计算平台来加速训练过程。
四、局限性
1.计算成本较高
由于要构建多个决策树,随机森林的训练时间和资源消耗相对较多。特别是在数据量非常大、特征数量非常多或者树的数量很多的情况下,训练过程可能会比较漫长。
2.模型解释性相对较差
虽然决策树本身具有一定的可解释性,但是随机森林是由多个决策树组成的集成模型,其结果是综合多个树的判断,所以在解释最终结果是如何得出的方面会比单棵决策树复杂。
五、随机森林的应用领域
1.数据挖掘与分析
在客户细分、市场篮分析等领域广泛应用。通过分析客户的各种属性,可以对客户进行精准分类,为企业制定个性化的营销策略提供依据。
2.金融风险评估
用于信用评分、贷款违约预测等。根据借款人的收入、债务情况、信用历史等多个特征,准确预测其是否会违约,帮助金融机构降低风险。
3.生物信息学
在基因表达数据分析、疾病诊断等方面发挥重要作用。通过分析基因表达数据,可以判断某种疾病的患病情况,为医学研究和临床诊断提供支持。
4.医疗领域
用于疾病诊断、基因分析、药物研发等。随机森林可以分析大量的医疗数据,如患者的症状、基因表达、医疗记录等,帮助医生更准确地诊断疾病和制定治疗方案。
5.市场营销领域
在客户细分、市场预测、推荐系统等方面有着广泛的应用。通过分析客户的行为数据和偏好,随机森林可以帮助企业更好地了解客户需求,制定个性化的营销策略,提高客户满意度和忠诚度。
六、例题练习
1.导入需要运用的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import numpy as np:NumPy 是 Python 中用于科学计算的核心库。它提供了高性能的多维数组对象,以及用于处理这些数组的工具。在机器学习中,NumPy 常用于数据的表示和操作,例如存储特征矩阵和标签向量等。import pandas as pd:Pandas 是一个强大的数据处理和分析库。它提供了数据结构如 Series 和 DataFrame,使得数据的读取、清洗、转换和分析变得更加容易。在机器学习项目中,常用来读取和处理数据集。from sklearn.model_selection import train_test_split:Scikit-learn 中的train_test_split函数用于将数据集分割为训练集和测试集。这是机器学习中非常重要的一步,确保模型在未见过的数据上进行评估,以检测其泛化能力。from sklearn.ensemble import RandomForestClassifier:Scikit-learn 中的随机森林分类器。随机森林是一种强大的集成学习算法,由多个决策树组成。它在分类和回归问题上都有很好的表现,具有高准确性、鲁棒性和对高维数据的处理能力等优点。from sklearn.metrics import classification_report:用于生成分类模型的性能报告。该报告包括准确率、召回率、F1 值等指标,帮助评估模型在不同类别上的性能表现。
2.导入数据
data = pd.read_csv('ods_bye_car_info1.csv' ,encoding='gb2312')
data.head()
输出结果:
user_id age gender annual_income marital_status buy_car_sign
0 1 0 0 0 0 否
1 2 2 1 1 1 是
2 3 1 0 0 0 否
3 4 0 0 2 0 是
4 5 2 0 1 1 否
1.这行代码使用 pandas 库的 read_csv 函数读取一个名为 ods_bye_car_info1.csv 的 CSV 文件。
2.encoding='gb2312' 参数指定了文件的编码格式为 GB2312。这是很重要的,因为如果文件的编码格式与默认编码不同,不指定正确的编码可能会导致读取文件时出现乱码或错误
3.这行代码调用 DataFrame 对象的 head 方法,该方法返回数据的前几行(默认是前 5 行)
4.这个操作通常用于快速查看数据集的结构和内容,以便对数据有一个初步的了解
| brand | model | price | ... | |
| 0 | Ford | Mustang | 30000 | ... |
| 1 | Toyota | Camry | 25000 | ... |
| 2 | Honda | Civic | 20000 | ... |
| 3 | BMW | 3 Series | 40000 | ... |
| 4 | Audi | A4 | 35000 | ... |
3.获取关于pandas数据框的信息
data.info()
输出结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 30 entries, 0 to 29
Data columns (total 6 columns):
user_id 30 non-null int64
age 30 non-null int64
gender 30 non-null int64
annual_income 30 non-null int64
marital_status 30 non-null int64
buy_car_sign 30 non-null object
dtypes: int64(5), object(1)
memory usage: 1.5+ KB
4.看一下买车情况的分类分布
data['buy_car_sign'].value_counts()
输出结果:
否 16
是 14
Name: buy_car_sign, dtype: int64
5.切出X和Y
x = data[['age','gender','annual_income','marital_status']].values
y = data['buy_car_sign'].values
6.设置随机数种子
np.random.seed = 123
7.拆分样本,训练集和测试集比例8:2
(train_x, test_x,train_y,test_y)=train_test_split(x,y,train_size=0.8,test_size=0.2)
8.构建模型,参数设置:决策树数量10,决策树的特征度量方法选择“gini”,树深不做设置,为none
model = RandomForestClassifier(n_estimators=7,criterion='gini',max_depth=None)
把测试集数据XY丢进去模型拟合学习
model.fit(train_x, train_y)
输出结果:
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=7, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
model.score(test_x, test_y)
输出结果:
0.8333333333333334
9.看看分类报告(用测试集真实值和模型预测值)
print(classification_report(test_y,model.predict (test_x)))
输出结果:
precision recall f1-score support
否 1.00 0.80 0.89 5
是 0.50 1.00 0.67 1
avg / total 0.92 0.83 0.85 6
10.用模型做预测,使用上次决策树时候的瞎编新数据,瞎编一个数据,假设有一个人,30-40岁,男性,年收入31万,已婚。转换一下编码,X= 1,0,2,1,让模型预测他是否买车
model.predict([[1,0,2,1]])
输出结果:
array(['是'], dtype=object)
11.看看预测的概率
model.predict_proba([[1,0, 2,1]])
输出结果:
array([[0.23809524, 0.76190476]])
模型预测买车的概率是92.3%,预测不买车的概率是7.69%
总结:
随着数据量的不断增加和计算能力的不断提高,随机森林在未来的应用前景将更加广阔。随着深度学习等新兴技术的发展,随机森林也可以与这些技术相结合,发挥更大的作用。例如,可以将随机森林作为深度学习模型的一部分,用于特征选择和模型解释,提高深度学习模型的可解释性和稳定性。
总之,随机森林作为一种强大的机器学习算法,具有高准确性、强鲁棒性、处理高维数据的能力和易于并行化等众多优点,在各个领域都有着广泛的应用前景。相信在未来,随机森林将继续发挥其重要作用,为数据驱动的决策提供有力支持。

















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









