







逻辑回归(Logistic Regression)
对于分类问题(Classification problem),也就是预测的变量 y y y 是一个离散值(比如 y = { 0 , 1 } y=\{0, 1\} y={0,1}),可以使用**逻辑回归(Logistic Regression)**来处理。逻辑回归的假设函数满足: 0 ≤ h θ ( x ) ≤ 1 0\le h_\theta (x)\le 1 0≤hθ(x)≤1
假设函数(Hypothesis Representation)
h θ ( x ) = g ( θ T x ) g ( z ) = 1 1 + e − z } h θ ( x ) = 1 1 + e − θ T x \left. \begin{matrix} h_\theta(x)=g(\theta^Tx)\\ g(z)=\frac{1}{1+e^{-z}} \end{matrix} \right\} \; h_\theta(x)=\frac{1}{1+e^{-\theta^Tx}} hθ(x)=g(θTx)g(z)=1+e−z1}hθ(x)=1+e−θTx1
- g ( z ) g(z) g(z) 称作 (sigmoid函数/logistic函数),它的值域在 ( 0 , 1 ) (0,1) (0,1) 范围内,所以假设函数的值域也在 ( 0 , 1 ) (0,1) (0,1) 之间。下面是 g ( z ) g(z) g(z)的函数图像:
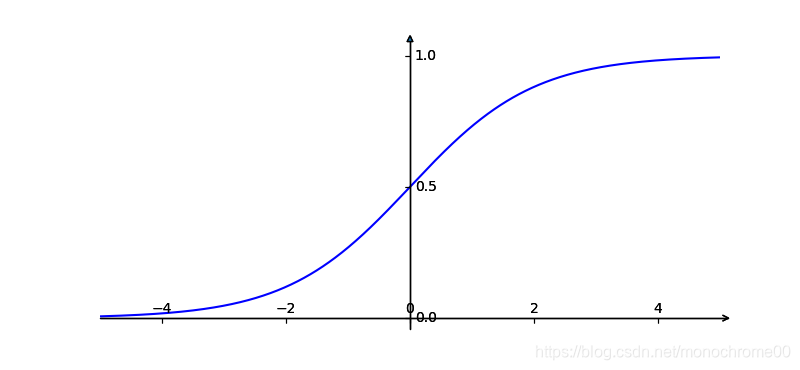
-
假设函数 h θ ( x ) h_\theta(x) hθ(x) 表示的是对于输入 x x x,它的真实值 y y y 是 1 1 1 的概率估计。也可以表示为: h θ ( x ) = P ( y = 1 ∣ x ; θ ) h_\theta(x)=P(y=1|x;\theta) hθ(x)=P(y=1∣x;θ)
-
P ( y = 0 ∣ x ; θ ) + P ( y = 1 ∣ x ; θ ) = 1 P ( y = 0 ∣ x ; θ ) = 1 − P ( y = 1 ∣ x ; θ ) P(y=0|x;\theta)+P(y=1|x;\theta)=1\\ P(y=0|x;\theta)=1-P(y=1|x;\theta) P(y=0∣x;θ)+P(y=1∣x;θ)=1P(y=0∣x;θ)=1−P(y=1∣x;θ)
-
决策边界(Decision Boundary):给假设函数一个边界,边界两边的值分别是 0 0 0 和 1 1 1,通过这种方式输出离散值。比如我们以 h θ ( x ) = 0.5 h_\theta(x)=0.5 hθ(x)=0.5为界,也就是以 θ T X = 0 \theta^TX=0 θTX=0为边界,大于 0 0 0的值为 1 1 1,小于 0 0 0的值为 0 0 0。
代价函数(Cost Function)
如果简单的套用线性回归的代价函数: J ( θ ) = 1 m ∑ i = 1 m 1 2 ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta)=\frac{1}{m}\sum_{i=1}^m\frac{1}{2}(h_\theta(x^{(i)})-y^{(i)})^2 J(θ)=m1∑i=1m21(hθ(x(i))−y(i))2,会发现 J ( θ ) J(\theta ) J(θ)不是一个凸函数(Non-convex),也就没法进行梯度下降。
逻辑回归的代价函数:
J
(
θ
)
=
1
m
∑
i
=
1
m
Cost
(
h
θ
(
x
(
i
)
)
,
y
(
i
)
)
J(\theta)=\frac{1}{m}\sum_{i=1}^{m}\text{Cost}(h_\theta(x^{(i)}),y^{(i)})
J(θ)=m1i=1∑mCost(hθ(x(i)),y(i))
Cost ( h θ ( x ) , y ) = { − log ( h θ ( x ) ) y = 1 − log ( 1 − h θ ( x ) ) y = 0 \text{Cost}(h_\theta(x),y)= \begin{cases} -\log(h_\theta(x))&& y=1\\ -\log(1-h_\theta(x))&& y=0 \end{cases} Cost(hθ(x),y)={−log(hθ(x))−log(1−hθ(x))y=1y=0
关于 c o s t cost cost的意义,画一张图就很好理解:

代价函数的式子也可以写成下面这个更加紧凑的形式:
J
(
θ
)
=
−
1
m
[
∑
i
=
1
m
y
(
i
)
log
h
θ
(
x
(
i
)
)
+
(
1
−
y
(
i
)
)
log
(
1
−
h
θ
(
x
(
i
)
)
]
J(\theta)=-\frac{1}{m}[\sum_{i=1}^my^{(i)}\log h_\theta(x^{(i)})+(1-y^{(i)})\log(1-h_\theta(x^{(i)})]
J(θ)=−m1[i=1∑my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i))]
在这里梯度下降的意义也是让
J
(
θ
)
J(\theta)
J(θ)最小化,代入梯度下降的一般算法并求导可得下面的形式:
r
e
p
e
a
t
u
n
t
i
l
c
o
n
v
e
r
g
e
n
c
e
{
θ
j
:
=
θ
j
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
∗
x
j
(
i
)
}
\begin{aligned} & repeat\;until\;convergence\;\{\\ & \qquad \theta_j:=\theta_j-\alpha\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})*x_j^{(i)} \\ & \}\\ \end{aligned}
repeatuntilconvergence{θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))∗xj(i)}
这个式子跟线性回归的基本一样,但是期内不得代价函数并不相同。
另外逻辑回归为了更好的效率,也要进行特征缩放。
高级优化
对于给定参数 θ \theta θ,如果我们能够求出:
- J ( θ ) J(\theta) J(θ)
- ∂ ∂ θ j J ( θ ) \frac{\partial}{\partial \theta_j}J(\theta) ∂θj∂J(θ)
我们有一下几个算法:
-
梯度下降(Gradient descent)
-
共轭梯度法(Conjugate gradient)
-
变尺度法(BFGS)
-
限制变尺度法(L-BFGS)
后三个算法比梯度下降更加优秀,它们既不需要手动调整参数$\alpha $,运行速度也比梯度下降快。它们唯一的缺陷就是太难了。
多元分类:一对多(Multi-class classification: One-vs-all)
多元分类处理的问题对象是预测值存在多个的情况: y = 1 , 2 , 3 , 4 , . . . y={1,2,3,4,...} y=1,2,3,4,...
如果有 n n n 个可能值,我们只需要进行对应的 n n n 次的逻辑回归即可。假设函数 h θ ( i ) ( x ) h_\theta^{(i)}(x) hθ(i)(x) 表示对于输入 x x x ,预测 y = i y=i y=i 的概率,并从中选一个最大的 i i i 作为最后的预测值。也就是 max i h θ ( i ) ( x ) \text{max}_ih_\theta^{(i)}(x) maxihθ(i)(x)














 3746
3746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









