







 该研究提出Make-It-3D方法,利用2D扩散模型作为3D监督,从单张图像创建出精细的3D模型,包括逼真的几何结构和纹理。方法分为两阶段,适用于一般对象,支持高质量文本到3D生成和纹理修改。
该研究提出Make-It-3D方法,利用2D扩散模型作为3D监督,从单张图像创建出精细的3D模型,包括逼真的几何结构和纹理。方法分为两阶段,适用于一般对象,支持高质量文本到3D生成和纹理修改。
[1] Tang J , Wang T , Zhang B ,et al.Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV).0[2024-01-29].DOI:10.1109/ICCV51070.2023.02086.

Abstract
In this work, we investigate the problem of creating
high-fidelity 3D content from only a single image. This
is inherently challenging: it essentially involves estimat-
ing the underlying 3D geometry while simultaneously hal-
lucinating unseen textures. To address this challenge, we
leverage prior knowledge from a well-trained 2D diffusion
model to act as 3D-aware supervision for 3D creation. Our
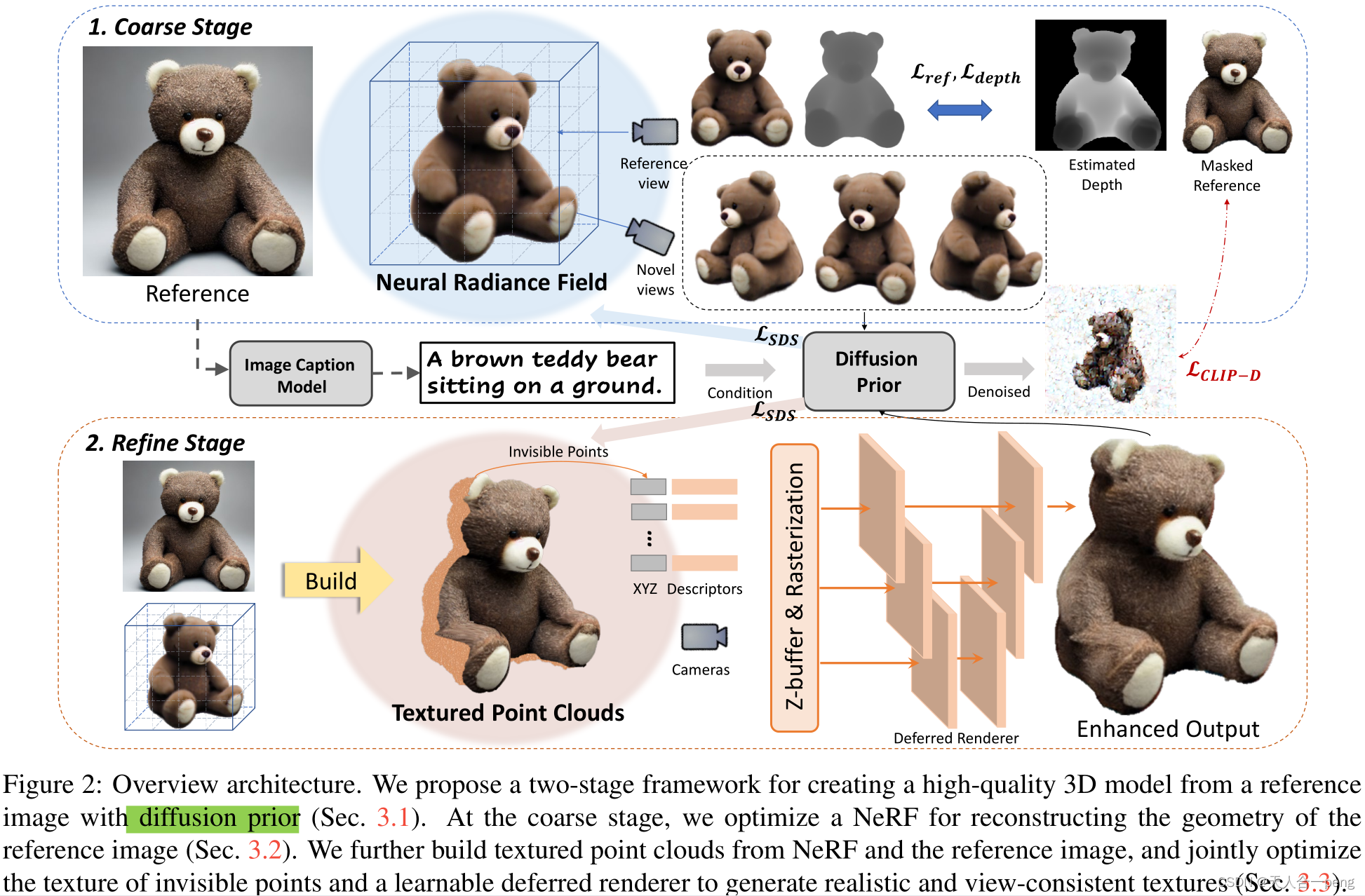
approach, Make-It-3D,employs a two-stage optimization
pipeline: the first stage optimizes a neural radiance field by
incorporating constraints from the reference image at the
frontal view and diffusion prior at novel views; the second
stage transforms the coarse model into textured point clouds
and further elevates the realism with diffusion prior while
leveraging the high-quality textures from the reference im-
age. Extensive experiments demonstrate that our method
outperforms prior works by a large margin, resulting in
faithful reconstructions and impressive visual quality. Our
method presents the first attempt to achieve high-quality 3D
creation from a single image for general objects and en-
ables various applications such as text-to-3D creation and
texture editing.
Our main contributions are summarized as:
• We propose Make-It-3D,a framework to create a high-
fidelity 3D object from a single image, using a 2D dif-
fusion model as 3D-aware prior. It does not require
multi-view images for training and can be applied to
any input image, whether it is real or generated.
• With a two-stage creation scheme, Make-It-3D repre-
sents the first work to achieve high-fidelity 3D creation
for general objects. The resulting 3D models exhibit
detailed geometry and realistic textures that accurately
conform to the reference images.
• Beyond image-to-3D creation, our method enables
multiple applications such as high-quality text-to-3D
creation and texture editing.

High-quality text-to-3D generation with diversity.
Prior arts [32, 18]often produce models with limited diversity
and excessively smooth textures. To perform high-quality
text-to-3D creation, we first convert the text prompt to a
reference image using 2D diffusion, and proceed with our
image-based 3D creation method. As shown in Figure 10,
Make-It-3D is capable of producing diverse examples from
atext prompt that exhibit stunning quality.
3D-aware texture modification.
Make-It-3D enables
view-consistent texture editing by manipulating the refer-
ence image in the refine stage while freezing the geometry.
Figure 11 shows that we can add a tattoo and apply styliza-
tion to the generated 3D model.
6. Conclusions
We introduce Make-It-3D,a novel two-stage method for
creating high-fidelity 3D content from one single image.
Leveraging diffusion prior as 3D-aware supervision, the
generated 3D models exhibit faithful geometry and realis-
tic textures with the diffusion CLIP loss and textured point
cloud enhancement. Make-It-3D is applicable to general
objects, empowering versatile fascinating applications. We
believe our method takes a big step in extending the success
of 2D content creation to 3D, providing users with a fresh
3D creation experience.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









