







本小节通过生成的聚类数据集,使用K-means方法进行分类,并将其可视化。
1.数据集
本小节通过make_blobs产生数据集,该函数是 sklearn.datasets中的一个函数,主要是产生聚类数据集,代码如下
n_samples = 1500
random_state = 170
X, y = make_blobs(n_samples=n_samples, random_state=random_state) n_samples表示样本的个数
random_state是随机种子,可以固定生成的数据
2.完整代码
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
def show_kmeans():
print(__doc__)
plt.figure(figsize=(12, 12))
n_samples = 1500
random_state = 170
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X)
plt.subplot(221)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.title("hello word!")
plt.show()
if __name__ == '__main__':
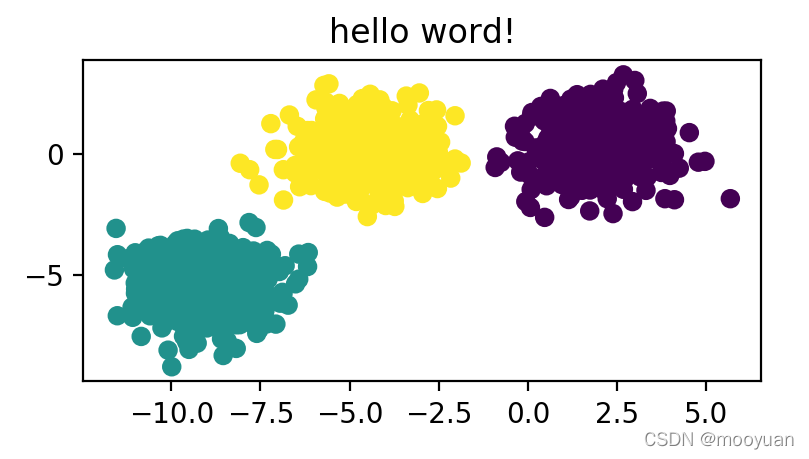
show_kmeans()3.运行结果
















 5558
5558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











