






编者按:针对图像翻译(image translation)任务,微软亚洲研究院的研究员们曾在 CVPR 2020 发表的论文中提出了 CoCosNet 算法,解决了图像生成过程中风格精细控制的难题。目前这一基于样例的图像翻译技术再升级!借鉴 PatchMatch 的思想,研究员们提出了 CoCosNet v2 算法,实现了在原高清分辨率下高效近似注意力(attention)机制。相比第一代算法,CoCosNet v2 能够应用到高清大图的生成过程中,同时也能节省大量的计算内存开销。目前,相关工作论文“Full-resolution Correspondence Learning for Image Translation”已被收录为 CVPR 2021 oral,并入围 Best Paper 候选名单。
近年来,图像翻译技术百花齐放,但仍有两个关键问题有待解决:1)生成的图风格不可预知,用户无法指定具体实例的样式(如红色的法拉利、橘红的天空);2)图片往往有较明显的瑕疵, 影响用户体验。
针对上述问题,微软亚洲研究院的研究员们在 CVPR 2020 上提出了基于样例的 CoCosNet 算法,算法按照用户给定样例生成多模态结果, 解决了图像生成过程中风格精细控制的难题,在一系列图片翻译任务中取得大幅领先的生成质量。但是由于较大的计算内存开销,这个方法并不能很好地拓展到高清图生成领域。
而为了解决图片清晰度的问题,研究员们进一步提出了 CoCosNet v2。借鉴了 PatchMatch 的思想,CoCosNet v2 充分利用了自然图片特征空间局部连续的特点,用迭代的方法换取内存开销,实现了在原高清分辨率下高效近似注意力(attention)机制,在高清大图的生成上取得了惊艳的效果。
该方法的相关工作已被收录为 CVPR 2021 oral 论文“Full-resolution Correspondence Learning for Image Translation”(论文链接:https://arxiv.org/abs/2012.02047)。
CoCosNet v2 算法的解决思路是降低计算内存开销,增强高清图片数据集的训练效率。该算法继承了“一代”的技术核心——两个跨域(cross-domain)图片的密集语义对应(dense semantic correspondence),从而可以在技术上实现图片的特征空间计算cross-attention,如图1所示。

图1:CoCosNet 框架
但第一代 CoCosNet 与最近大火的视觉 Transformer 类似,直接在高分辨率图片(或特征空间)上计算注意力矩阵会带来极大的内存开销,例如,在1024x1024分辨率图片上,计算注意力矩阵会占用 1T 大小的显存。
另外,CoCosNet 仅在64x64的分辨率上构建语义对应,而低分辨率下的对应关系使得样例图片中的精细纹理并不能很好的保留在最终的生成结果中。

解决方法
针对上述注意力矩阵显存占用率问题,CoCosNet v2 用两个技术对此进行了处理。首先,利用 coarse-to-fine 的思想,构建多层级特征空间金字塔,在高层次低分辨率空间构建的对应关系中,指导下一层在更高分辨率下进行更精细的搜索。
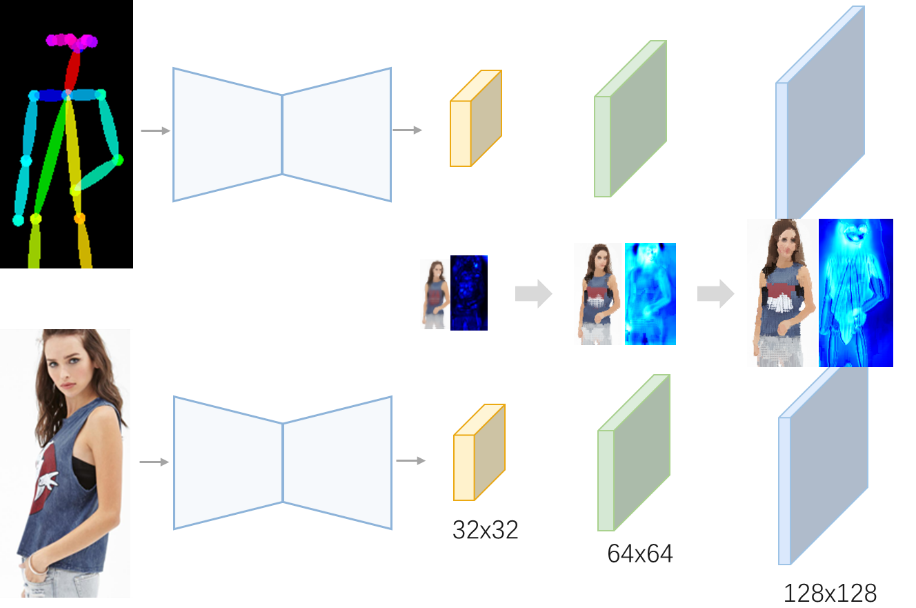
图2:采用 coarse-to-fine 的策略,利用低分辨率对应来指导高分辨率下的搜索
尽管有来自上一层的对应初始化,但在高分辨率上的密集对应依然有挑战性。对此,研究员们借用了 PatchMatch 的思想,考虑到对应关系的局部平滑性,因而可以将最近邻搜索用迭代搜索的方法快速逼近。
如图3所示,初始时刻(左图)的蓝色图块的对应关系并不可靠,当发现其临近图块(绿色框)有优质的对应结果后,研究员们便对蓝色图块的候选区域进行了更新(中间图),得到更合理的对应,从而传播到当前图块(matching propagation)。
最后在候选区域附近扰动搜索(local random searching),至此完成一次迭代搜索。随着迭代的进行,可靠图块的对应关系会迅速传播给附近图块,整个搜索过程可以在几次迭代后迅速收敛。

图3:PatchMatch 过程
具体实现时,研究员们为每个图块匹配到 K 个对应区域,进而图片扭转(image warping)可以写成 softmax 的形式,整个迭代搜索过程梯度可导为:
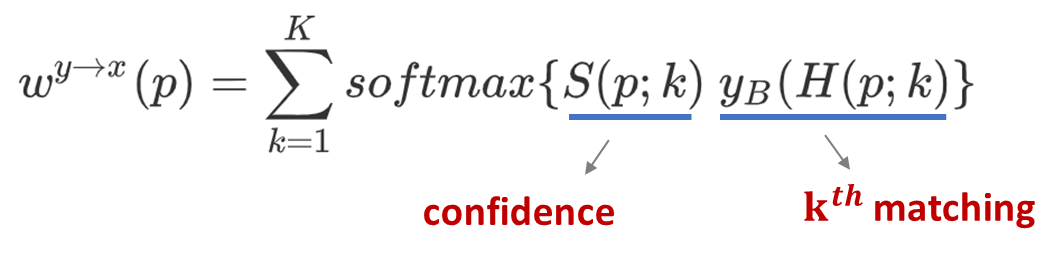
但是这样的实验并不理想,图片扭转的结果显示输入图片的语义并不能很好的对应起来。

图4:直接用 differentiable PatchMatch 不能学习得到准确的语义对应
研究员们猜测其原因是 PatchMatch 之前的特征提取模块没有很好的更新,造成了语义特征提取不准确。这是因为每个图块的梯度只能反传到稀疏的 K 个候选区域,而不能像注意力矩阵那样每个位置都可以得到梯度更新。
另一个猜测的原因是,PatchMatch 迭代每次仅仅考虑临近图块,需要很多次迭代才能利用到远处图块的对应关系。所以,研究员们利用几层卷积来提前处理每次迭代的结果,等同于增大了每层 match propagation 的感受野 (图5)。

图5:利用卷积层可以扩大 matching propagation 的感受野
此外,如果迭代搜索认为是 recurrent(递归)过程,那么则可以采用 GRU 来更好地修正下次搜索位置。
因此,研究员们提出了 ConvGRU-assisted PatchMatch,不仅能利用更大视野内所有图块的对应,也能利用历史迭代结果,大大缩短了 PatchMatch 所需的迭代次数。每一层的搜索过程,可以用图6表示。

图6:ConvGRU 辅助下的 PatchMatch 迭代搜索过程
至此,研究员们可以在 N 个层级上得到语义对应,每层的图片扭转注入到生成网络可得到最终的生成结果。值得注意的是,端到端训练网络同时实现语义对应和图片生成,其中语义对应并没有 ground truth,而是通过弱监督信号间接习得的。

图7:从图片扭转到最终的图片生成

实验结果
研究员们在三个任务上进行了实验:骨骼关键点->姿态图片,语义分割->自然图像,轮廓->人脸图片。图8、图9、图10为生成结果,每组结果中第一列是输入图片,第一行是输入样例图片,第二行是 CoCosNet v2 结果。

图8:DeepFashion 512x512分辨率下的骨骼关键点->姿态生成

图9:DeepFashion 512x512分辨率下的骨骼关键点->姿态生成

图10:MetFace 1024x1024分辨率下的人脸轮廓->艺术画生成
相比之前的 SOTA 方法,CoCosNet v2 生成的图片在肉眼感知质量、定量指标上均大幅领先。

图11:生成质量对比

图12:DeepFashion 数据集上的指标对比。CoCosNet v2 能大幅降低 FID,且更好的保留样例图片的风格细节。
结语与展望
为了解决先前图像翻译方法无法生成高清图的痛点问题,研究员们在 CoCosNet v2 中构建了多分辨率金字塔,并借鉴传统方法 PatchMatch 的方法,将其作为可微分模块与图像生成端到端训练,同时额外引入 ConvGRU 模块帮助了梯度反传,帮助迭代搜索更快收敛。
值得注意的是,CoCosNet v2 有效解决了高清图中注意力模块的平方级内存开销问题。与近期一系列高效(efficient)Transformer,如 BigBird、Linformer、Performer 相比,CoCosNet v2 能够更充分的利用图片的局部相关性,用迭代的方法换取更小的内存消耗,可谓另一种另辟蹊径的解决方法。
研究员们希望 CoCosNet 系列工作能将高清逼真的图片翻译提升至新的台阶,并在未来有望开启更多如图片编辑、人脸上妆、虚拟试衣等新奇有趣的任务研究。
了解更多 CoCosNet 系列论文细节,请查看:
CoCosNet v2 论文链接:https://arxiv.org/abs/2012.02047
CoCosNet v2 代码:https://github.com/microsoft/CoCosNet-v2
CoCosNet v1 论文链接:https://arxiv.org/abs/2004.05571
CoCosNet v1 代码:https://github.com/microsoft/CoCosNet

备注方向,如:GAN

计算机视觉交流群
图像分割、姿态估计、智能驾驶、超分辨率、自监督、无监督、2D、3D目标检测等最新资讯,若已为CV君其他账号好友请直接私信。
在看,让更多人看到 















 358
358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









