









CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation图像翻译的全分辨率对应学习
0.摘要
我们提出了跨域图像的全分辨率对应学习,这有助于图像翻译。我们采用分层策略,利用粗层次的对应关系来指导精细层次。在每个层次中,通过迭代利用邻域匹配的补丁匹配(PatchMatch),可以有效地计算对应关系。在每个PatchMatch迭代中,ConvGRU模块被用来优化当前的对应关系,不仅要考虑更大背景的匹配,还要考虑历史估计。提出的CoCosNet v2是一种GRU辅助的PatchMatch方法,它是完全可微且高效的。当与图像翻译联合训练时,可以以无监督的方式建立全分辨率语义对应,这反过来有助于基于范例的图像翻译。对不同翻译任务的实验表明,CoCosNet v2在生成高分辨率图像方面的性能远远优于最新文献。
1.概述
图像到图像的翻译学习图像域之间的映射,并在广泛的应用中取得了成功[29,10,39,46,59]。特别是,基于范例的图像翻译允许用户更灵活地控制,方法是根据具有所需风格的特定范例进行翻译。然而,在忠实于样本的同时,同时生成高质量的图像并非易事,而生成高分辨率图像则变得相当困难
早期研究[9,19,56,55,48,5]直接通过生成性对抗网络[14,36]学习地图绘制,但他们未能利用样本中的信息。后来,一系列方法[12、17、40]提出在翻译过程中参考样本图像,方法是根据样本图像的样式调整特征规范化。但是,由于调制是均匀应用的,因此只能传输全局样式,而在最终输出中,细节纹理会被洗掉
最近,CoCosNet[57]建立了跨域图像之间的密集语义对应关系。通过这种方式,网络可以利用样本中的精细纹理,从而减轻对局部纹理的幻觉。然而,在估计高分辨率对应关系时,会出现令人望而却步的内存占用,因为匹配需要计算输入特征图所有位置之间的成对相似性,而低分辨率对应关系(例如64×64)无法引导网络利用样本的精细结构。
在本文中,我们首次提出了全分辨率的跨域对应学习,这将产生具有照片真实感的高分辨率翻译图像,因为网络可以利用示例中的精细细节。为了实现这一点,我们从PatchMatch[3]中汲取了灵感,它在计算效率和纹理一致性方面具有优势,因为它迭代地传播来自邻域的对应关系,而不是全局搜索。尽管如此,直接将PatchMatch应用于高分辨率特征地图进行训练是不可行的,原因有三个。首先,当对应关系被随机初始化时,该算法对高分辨率图像的效率不够。第二,在早期训练阶段,对应是混沌的,向后梯度流向错误对应的面片,使得特征学习困难。此外,PatchMatch在传播对应估计时没有考虑更大的上下文,并且需要大量迭代来收敛。
为了解决这些局限性,我们提出以下技术来学习全分辨率对应。
- 我们采用了一种分层策略,利用粗层的匹配来指导后续的更细层,以便在细层的搜索可以从良好的初始化开始。
- 受最近循环优化成功的启发[42,7,45],我们使用**卷积选通循环单元(ConvGRU)**来优化每个PatchMatch迭代中的对应关系。匹配考虑了更大的背景以及历史通信估计,这大大提高了通信质量。此外,它极大地有利于特征学习,因为梯度现在可以流向一个更大的背景,而不仅仅是几个对应的补丁。
- 最后所提出的分层GRU辅助修补匹配是完全可微的,并且以无监督的方式学习跨域对应,这是非常具有挑战性的,尤其是在高分辨率的情况下。
我们表明,我们的方法称为CocosNet v2,由于具有全分辨率跨域对应,因此获得的图像质量明显高于最先进的作品。更重要的是,我们的方法能够生成具有视觉吸引力的高分辨率图像转换结果,例如512×512和1024×1024的图像(图1)。我们将主要贡献总结如下:
- 我们提出学习来自不同领域的全分辨率对应,以便从示例图像中捕捉细致逼真的细节,用于图像翻译为了实现这一点,
- 我们提出了CoCosNet v2,这是一种分层GRU辅助的补丁匹配方法,用于高效的对应计算,它与图像翻译同时学习
- 我们表明,全分辨率对应会导致翻译输出中的纹理显著细化。翻译后的图像在大分辨率下显示出前所未有的质量。
2.相关工作
2.1.PatchMatch
对应匹配是计算机视觉中的一个基本问题[6,28,51,32,11,13,50]。开创性的工作PatchMatch[3]在很大程度上缓解了高得令人望而却步的计算挑战。关键的见解来自两个原则:1)通过随机抽样可以找到良好的补丁匹配;2) 图像是连贯的,因此匹配可以传播到附近地区。由于其效率,PatchMatch已成功应用于不同的任务[26,4,2,16,11]。然而,传统的PatchMatch只能找到与图像的匹配,不适用于深度神经网络。最近,[11]提出使整个匹配过程可微,并支持特征学习和端到端对应学习。然而,这种方法在训练过程中仍然无法学习高分辨率的对应关系。相反,我们在层次结构中应用补丁匹配,并提出了一种新的GRU辅助细化模块来考虑更大的上下文,这使得更快的收敛和更准确的对应关系。值得注意的是[25,27]使用PatchMatch进行风格转换,但它们对预训练的VGG特征进行操作,并要求输入为自然图像,而我们允许对任意域输入(如姿势或边缘)进行特征学习。
2.2.图像到图像的翻译
图像翻译方法[19,48,40,60,53,22,29,44]通常采用条件生成对抗网络,通过明确监督的成对数据或强制循环一致性的非成对数据来优化网络。近年来,基于范例的图像翻译[18,41,47,33,43,1,54]因其灵活性和较高的生成质量而受到广泛关注。虽然大多数方法都是从参考图像转移整体风格,但最近的一项工作CoCosNet[57]提出了建立跨域输入的密集语义对应,从而更好地保留了范例的精细结构。我们的工作与CoCosNet[57]密切相关,但有很大的改进。我们的目标是计算全分辨率下的密集对应,而[57]只能找到小尺度上的对应。由于全分辨率的对应关系,我们的网络可以从范例中利用更精细的结构,从而在高分辨率的输出中实现卓越的质量。
3.CoCosNet v2
给定源域A中的图像xA和目标域B中的图像yB,我们建议学习跨域全分辨率对应,以捕获更精细的细节,并作为基于范例的图像平移的更好指导。具体来说,xA和yB首先被表示为多级特性(章节3.1)。此后,从低分辨率到全分辨率建立对应关系,并进一步用于扭曲样本以与xA对齐(章节3.2)。最后,扭曲的样本通过一个平移网络来生成所需的输出图像(章节3.3)。我们在图2中说明了整个网络架构。

图2:CoCosNet v2的总体架构。我们学习全分辨率的跨域对应,通过它我们扭曲了样本图像(wy→xi)并将其输入翻译网络以进行进一步渲染。全分辨率对应关系是分层学习的,低分辨率结果作为下一级的初始化。在每一层中,通过可微修补匹配可以有效地计算对应关系,然后通过ConvGRU进行循环细化。
3.1. 多级域对齐
我们首先学习一个公共的潜在空间,其中表示包含两个领域的语义内容,并且可以在某种相似性度量下比较特征。与之前的工作[57]类似,我们分别学习了两个域的映射函数。我们构建了一个由L个从低分辨率到高分辨率的潜在空间组成的金字塔,而不是仅仅创建一个潜在空间。对于特征提取,我们采用U-net架构,通过跳过连接将丰富的上下文信息传播到更高分辨率的特征。
形式上,假设MA和MB是对应的两个映射函数,我们有多层次的潜在特征,
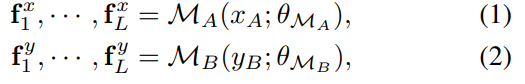
其中fxl∈RHl×Wl×Cl,并且H1<H2<…<HL,W1<W2<…<WL,Cl表示通道数。潜在特征fx从小分辨率放大到全分辨率。fyl具有相似的含义,而θMA和θMB表示参数。
3.2. 分层GRU辅助补丁匹配
值得注意的是,由于内存限制和速度限制,以前的工作在低分辨率水平上计算密集对应场。我们建议在全分辨率特征水平上利用对应关系,即fxL和fyL,并提出一种新的有效方法,该方法对内存和时间的要求更低。
3.2.1.从粗到精的策略
直接在全分辨率特征上建立对应不仅增加了计算复杂度,而且还放大了小面片的噪声和模糊度。为了解决这个问题,我们提出了一个从粗到精的策略,对潜在表征的金字塔进行处理。特别是,我们从最低分辨率级别的对应匹配开始,并使用匹配结果作为后续高分辨率级别的初始指导。通过这种方式,可以获取所有级别的对应字段。用公式表示就是:
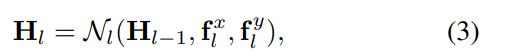
其中Hl ∈RHl×Wl×2K代表fxl的最近领域。并且对于特征点fxl(P),Hl(P)指定了fyL中P的K个最邻近的位置,举例说明:
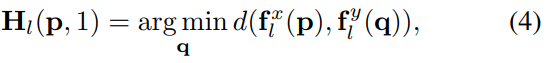
然而,彻底遍历p和q需要很多时间,尤其是在整个全分辨率特征地图上。因此,我们提出了GRU辅助的PatchMatch,它试图进行迭代改进。
3.2.2.GRU辅助修补匹配
从本质上讲,我们的算法可以简单地看作是迭代和重复地执行传播和基于GRU的精化,直到收敛或达到固定的迭代次数。上一级别的结果为Hl−1用作初始化,并通过交替两个步骤逐步改进。我们在图3中说明了这个匹配过程。

图3:GRU辅助的补丁匹配包括(a)传播和(b)基于GRU的细化。请注意,所有位置的传播都是并行进行的。
我们将第t步中的对应映射表示为Hl,t,初始化对应域Hl,0从Hl−1上采样。为了避免引起混乱,在本小节中省略了级别注释l。第一步,传播,源于PatchMatch[3]。它通过检查当前patch邻域的已知匹配结果来改进当前patch的匹配,我们将其表示为
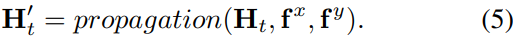
其中,Hˋt为最近邻场(NNF)传播结果。然而,传播只检查空间相邻的小块,这使得它严重依赖于空间平滑假设,容易陷入局部最优。PatchMatch中的随机搜索步骤在一定程度上缓解了这个问题,但这还不够,特别是在一个非常大的候选集中搜索时。我们的解决方案是有选择地查找遥远的候选对象,而不是随机搜索,这是通过一个新设计的细化模块引导的。我们期望,给定当前偏移量,操作符输出一个细化字段,作为对一些不正确匹配对的校正。
具体来说,在第二步中,我们采用了卷积门控循环单位(ConvGRU):
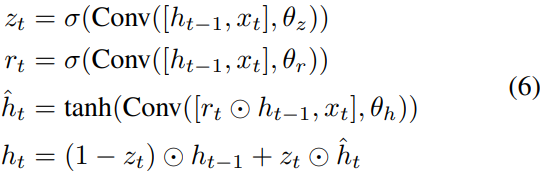
其中,xt为从四个变量fx, fy, Ot, St中提取特征串接得到的输入,Ot和St为当前偏移量和对应的匹配分数,
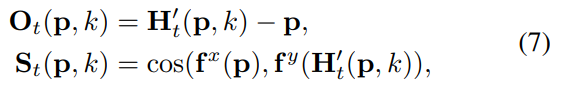
其中k = 1, 2,···,k考虑k个最近邻。初始隐藏状态设置为0,通过将输出隐藏状态Ht输入两个卷积层来预测偏移量更新∆Ht。最后,将偏移量更新为:Ht+1 = Hˋt +∆Ht,并传递到下一步。
3.2.3.ConvGRU的好处
首先,它有助于利用更大的文本,而不是邻域,来完善当前的对应关系估计。因此,这些对应关系可以在更快的收敛速度下变得全局一致。其次,GRU会记住对应估计的历史,并在下一次迭代中以某种方式预测可能的对应位置。第三,后向梯度现在可以在更大的上下文中流向像素,而不是在特定的位置,这有利于特征学习,进而有利于对应。
3.2.4.可微扭曲函数
与直接将学习到的对应关系推向地面真相的传统应用不同,我们在图像到图像的翻译中没有偏移地面真相。相反,我们利用后续翻译网络中的对应字段生成高质量的输出,从而使对应字段更加准确。
我们使用对应字段扭曲样本图像yB,并使用扭曲图像wy→xl来指导翻译网络。通常,wy→xl仅通过使用最接近的匹配获得,即wy→xl§=yB(Hl(p,1))。然而,等式4中的arg-min运算是不可微的。因此,我们建议使用以下软扭曲函数,即top K可能扭曲函数的平均值:
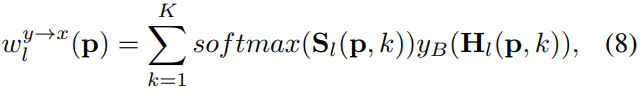
其中S是等式7中定义的匹配分数,表示语义相似性。
3.3.翻译网络
翻译网络G旨在合成一个图像x∧B,该图像需要尊重xA中的空间语义结构,同时类似于yB中相似部分的外观。与最近的条件生成器[38,55,35]类似,我们采用了一种简单而自然的方法,将常量代码z作为输入。为了保留扭曲样本图像的语义信息,wy→X1,wy→xL,我们采用空间自适应非规范化(SPADE)[40],自适应学习调制参数。
具体来说,让第i个标准化层之前的激活为Ti∈ RCi×Hi×Wi。我们首先在通道维度中连接扭曲的图像(必要时在此处执行上采样)。结果串联表示为w∧y→x=[wy→x1↑, · · · , wy→xL],↑ 表示上采样。此后,我们计划通过两个卷积层投影w∧y→x产生调制参数αih,w和βih,w用于风格调制,
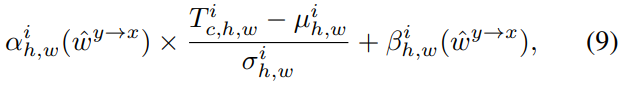
其中,µih,w和σih,w计算平均值和标准差。最后,翻译结果为:
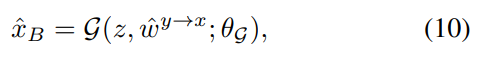
其中,θG为网络参数。
3.4.损失函数
我们的方法是端到端可微分的,可以通过反向传播优化,同时学习跨域对应和期望输出。一般来说,可以很容易地访问不同领域中语义对齐的数据对{xA, xB},但不一定可以访问训练三元组{xA, yB, xB},其中xB与yB具有相似的外观,而xA的语义类似。因此我们应用几何失真从xB构造伪样本yB = T (xB),其中T表示几何增强。
3.4.1.域对齐损失
对于成功的对应,xA和它对应的xB的多级表示必须位于相同的空间,因此我们强制,
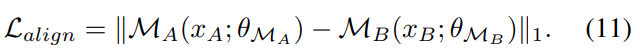
3.4.2.对应的损失
对于伪对,扭曲的w∧y→x应该恰好是xB。因此,我们强调,
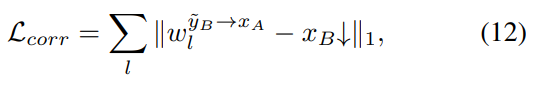
其中↓表示下采样,使xB的大小与翘曲图像匹配。
3.4.3.映射的损失
我们期望跨域输入可以从潜在表示映射到目标域的对应表示,这有助于在潜在空间中保持语义,
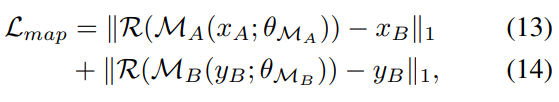
其中R将特征映射到目标域中的图像。
3.4.4.翻译损失
翻译后的输出在语义上与输入相似,外观接近范例。我们分别针对这两个目标提出了两种损失。一是知觉损失,以最小化与xB的语义差异:
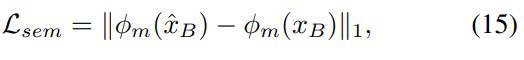
其中,我们从预训练的VGG网络的高层中采用φm特征
另一个是外观损失,包括应用任意范例yB时上下文损失(contextual loss ,CX)[34]和使用pseudo yB时特征匹配损失。外观损耗通过利用VGG的低级特征φm来促进外观相似性。具体来说,外貌损失是
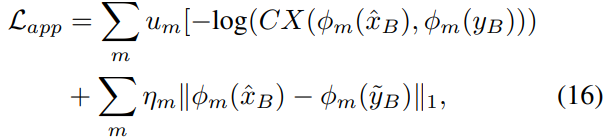
其中,um控制不同VGG层的相对重要性,ηm为平衡系数。
3.4.5.对抗损失
我们添加了一个鉴别器来区分输出和目标域中的真实图像,与试图合成不可区分图像的生成器竞争。对抗性损失是,
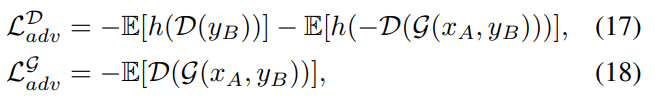
其中h(t) = min(0,−1 + t)为正则化鉴别器的hinge损耗[55,5]。
3.4.6.总损失
总之,我们的总体目标函数是,
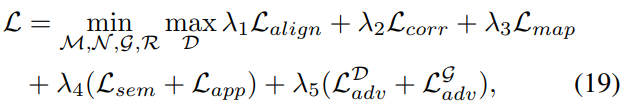
式中,λ为加权参数,M包括MA和MB, N包括N1,···,NL。
5. 结论
我们建议学习完全解析的语义对应。为了实现这一点,我们引入了一种有效的算法CoCosNet v2,该算法通过从粗到细的层次结构中的迭代细化有效地建立通信。在每一层,传播和基于grubbased的传播交替执行。CoCosNet v2导致具有精细纹理的真实感输出以及大分辨率5122和10242的视觉吸引力图像。
参考文献
[1] Aayush Bansal, Yaser Sheikh, and Deva Ramanan. Shapes and context: In-the-wild image synthesis & manipulation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2317–2326, 2019. 2
[2] Linchao Bao, Qingxiong Yang, and Hailin Jin. Fast edgepreserving patchmatch for large displacement optical flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3534–3541, 2014. 2
[3] Connelly Barnes, Eli Shechtman, Adam Finkelstein, and Dan B Goldman. Patchmatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph., 28(3):24, 2009. 2, 3
[4] Michael Bleyer, Christoph Rhemann, and Carsten Rother. Patchmatch stereo-stereo matching with slanted support windows. In Bmvc, volume 11, pages 1–11, 2011. 2
[5] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018. 1, 5, 7
[6] Thomas Brox and Jitendra Malik. Large displacement optical flow: descriptor matching in variational motion estimation. IEEE transactions on pattern analysis and machine intelligence, 33(3):500–513, 2010. 2
[7] Shaofan Cai, Xiaoshuai Zhang, Haoqiang Fan, Haibin Huang, Jiangyu Liu, Jiaming Liu, Jiaying Liu, Jue Wang, and Jian Sun. Disentangled image matting. In Proceedings of the IEEE International Conference on Computer Vision, pages 8819–8828, 2019. 2
[8] Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7291–7299, 2017. 5
[9] Qifeng Chen and Vladlen Koltun. Photographic image synthesis with cascaded refinement networks. In Proceedings of the IEEE international conference on computer vision, pages 1511–1520, 2017. 1
[10] Y unjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8789–8797, 2018. 1
[11] Shivam Duggal, Shenlong Wang, Wei-Chiu Ma, Rui Hu, and Raquel Urtasun. Deeppruner: Learning efficient stereo matching via differentiable patchmatch. In Proceedings of the IEEE International Conference on Computer Vision, pages 4384–4393, 2019. 2
[12] Vincent Dumoulin, Jonathon Shlens, and Manjunath Kudlur. A learned representation for artistic style. arXiv preprint arXiv:1610.07629, 2016. 1
[13] Alexei A Efros and Thomas K Leung. Texture synthesis by non-parametric sampling. In Proceedings of the seventh IEEE international conference on computer vision, volume 2, pages 1033–1038. IEEE, 1999. 2
[14] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Y oshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014. 1
[15] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in neural information processing systems, pages 6626–6637, 2017. 5, 6
[16] Yinlin Hu, Rui Song, and Y unsong Li. Efficient coarse-tofine patchmatch for large displacement optical flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5704–5712, 2016. 2
[17] Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, pages 1501–1510, 2017. 1, 6
[18] Xun Huang, Ming-Y u Liu, Serge Belongie, and Jan Kautz. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 172–189, 2018. 2, 6
[19] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134, 2017. 1, 2
[20] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196, 2017. 7
[21] Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Training generative adversarial networks with limited data. Advances in Neural Information Processing Systems, 33, 2020. 5
[22] Taeksoo Kim, Moonsu Cha, Hyunsoo Kim, Jung Kwon Lee, and Jiwon Kim. Learning to discover cross-domain relations with generative adversarial networks. arXiv preprint arXiv:1703.05192, 2017. 2
[23] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. 5
[24] Boyi Li, Felix Wu, Kilian Q Weinberger, and Serge Belongie. Positional normalization. In Advances in Neural Information Processing Systems, pages 1622–1634, 2019. 21
[25] Chuan Li and Michael Wand. Combining markov random fields and convolutional neural networks for image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2479–2486, 2016. 2
[26] Y u Li, Dongbo Min, Michael S Brown, Minh N Do, and Jiangbo Lu. Spm-bp: Sped-up patchmatch belief propagation for continuous mrfs. In Proceedings of the IEEE International Conference on Computer Vision, pages 4006–4014, 2015. 2
[27] Jing Liao, Y uan Yao, Lu Y uan, Gang Hua, and Sing Bing Kang. Visual attribute transfer through deep image analogy. arXiv preprint arXiv:1705.01088, 2017. 2
[28] Ce Liu, Jenny Y uen, and Antonio Torralba. Sift flow: Dense correspondence across scenes and its applications. IEEE transactions on pattern analysis and machine intelligence, 33(5):978–994, 2010. 2
[29] Ming-Y u Liu, Thomas Breuel, and Jan Kautz. Unsupervised image-to-image translation networks. In Advances in neural information processing systems, pages 700–708, 2017. 1, 2
[30] Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1096–1104, 2016. 5
[31] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of the IEEE international conference on computer vision, pages 3730–3738, 2015. 8
[32] Bruce D Lucas, Takeo Kanade, et al. An iterative image registration technique with an application to stereo vision. 1981. 2
[33] Liqian Ma, Xu Jia, Stamatios Georgoulis, Tinne Tuytelaars, and Luc V an Gool. Exemplar guided unsupervised image-toimage translation with semantic consistency. arXiv preprint arXiv:1805.11145, 2018. 2, 6
[34] Roey Mechrez, Itamar Talmi, and Lihi Zelnik-Manor. The contextual loss for image transformation with non-aligned data. In Proceedings of the European Conference on Computer Vision (ECCV), pages 768–783, 2018. 5
[35] Lars Mescheder, Andreas Geiger, and Sebastian Nowozin. Which training methods for gans do actually converge? arXiv preprint arXiv:1801.04406, 2018. 4
[36] Mehdi Mirza and Simon Osindero. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784, 2014. 1
[37] Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Y uichi Y oshida. Spectral normalization for generative adversarial networks. arXiv preprint arXiv:1802.05957, 2018. 5
[38] Takeru Miyato and Masanori Koyama. cgans with projection discriminator. arXiv preprint arXiv:1802.05637, 2018. 4
[39] Zak Murez, Soheil Kolouri, David Kriegman, Ravi Ramamoorthi, and Kyungnam Kim. Image to image translation for domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4500–4509, 2018. 1
[40] Taesung Park, Ming-Y u Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2337–2346, 2019. 1, 2, 4, 6
[41] Xiaojuan Qi, Qifeng Chen, Jiaya Jia, and Vladlen Koltun. Semi-parametric image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8808–8816, 2018. 2, 6
[42] Dongwei Ren, Wangmeng Zuo, Qinghua Hu, Pengfei Zhu, and Deyu Meng. Progressive image deraining networks: A better and simpler baseline. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3937–3946, 2019. 2
[43] Morgane Riviere, Olivier Teytaud, Jérémy Rapin, Yann LeCun, and Camille Couprie. Inspirational adversarial image generation. arXiv preprint arXiv:1906.11661, 2019. 2
[44] Amélie Royer, Konstantinos Bousmalis, Stephan Gouws, Fred Bertsch, Inbar Mosseri, Forrester Cole, and Kevin Murphy. Xgan: Unsupervised image-to-image translation for many-to-many mappings. In Domain Adaptation for Visual Understanding, pages 33–49. Springer, 2020. 2
[45] Zachary Teed and Jia Deng. Raft: Recurrent allpairs field transforms for optical flow. arXiv preprint arXiv:2003.12039, 2020. 2
[46] Ziyu Wan, Bo Zhang, Dongdong Chen, Pan Zhang, Dong Chen, Jing Liao, and Fang Wen. Bringing old photos back to life. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2747–2757, 2020. 1
[47] Miao Wang, Guo-Ye Yang, Ruilong Li, Run-Ze Liang, SongHai Zhang, Peter M Hall, and Shi-Min Hu. Example-guided style-consistent image synthesis from semantic labeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1495–1504, 2019. 2
[48] Ting-Chun Wang, Ming-Y u Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8798–8807, 2018. 1, 2, 6
[49] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004. 8
[50] Li-Yi Wei and Marc Levoy. Fast texture synthesis using tree-structured vector quantization. In Proceedings of the 27th annual conference on Computer graphics and interactive techniques, pages 479–488, 2000. 2
[51] Philippe Weinzaepfel, Jerome Revaud, Zaid Harchaoui, and Cordelia Schmid. Deepflow: Large displacement optical flow with deep matching. In Proceedings of the IEEE international conference on computer vision, pages 1385–1392, 2013. 2
[52] Saining Xie and Zhuowen Tu. Holistically-nested edge detection. In Proceedings of the IEEE international conference on computer vision, pages 1395–1403, 2015. 5
[53] Zili Yi, Hao Zhang, Ping Tan, and Minglun Gong. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE international conference on computer vision, pages 2849–2857, 2017. 2
[54] Bo Zhang, Mingming He, Jing Liao, Pedro V Sander, Lu Y uan, Amine Bermak, and Dong Chen. Deep exemplarbased video colorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8052–8061, 2019. 2
[55] Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. Self-attention generative adversarial networks. In International Conference on Machine Learning, pages 7354–7363. PMLR, 2019. 1, 4, 5
[56] Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dimitris N Metaxas. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE international conference on computer vision, pages 5907– 5915, 2017. 1
[57] Pan Zhang, Bo Zhang, Dong Chen, Lu Y uan, and Fang Wen. Cross-domain correspondence learning for exemplar-based image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5143–5153, 2020. 1, 2, 3, 6
[58] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 633–641, 2017. 5
[59] Xingran Zhou, Siyu Huang, Bin Li, Yingming Li, Jiachen Li, and Zhongfei Zhang. Text guided person image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3663–3672, 2019. 1
[60] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycleconsistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, pages 2223– 2232, 2017. 2, 21















 3162
3162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









