






关注公众号,发现CV技术之美
近日,ECCV(European Conference on Computer Vision)组委会公布了录用论文名单,共有2395篇论文被录用,录用率27.9%。ECCV,即欧洲计算机视觉国际会议,是计算机视觉领域中最顶级的会议之一,与ICCV和CVPR并称为计算机视觉领域的“三大顶会”。ECCV每两年举行一次,会议内容广泛覆盖了计算机视觉的所有子领域,包括但不限于图像识别、物体检测、场景理解、视觉跟踪、三维重建、深度学习在视觉中的应用等。
今年,腾讯优图实验室共有14篇论文被录用,内容涵盖工业缺陷异常检测、图文引导图像编辑、多模态标签等研究方向,展示了腾讯优图实验室在人工智能领域的技术能力和研究成果。
以下为腾讯优图实验室的入选论文概览:
01
基于强化学习的多模态标签相关性排序
Multimodal Label Relevance Ranking via Reinforcement Learning
Taian Guo, Taolin Zhang, Haoqian Wu, Hanjun Li, Ruizhi Qiao, Xing Sun
传统的多标签识别方法通常集中于标签的置信度,却往往忽视了与人类偏好相一致的偏序关系的重要性。为了解决这一问题,我们提出了一种创新的多模态标签相关性排序方法,并将其命名为基于近端策略优化的标签相关性排序算法(LR²PPO),该算法能够有效地识别标签间的偏序关系。LR²PPO首先利用目标域中的偏序对来训练一个奖励模型,该模型旨在捕捉特定场景中内在的人类偏好。然后,我们精心设计了针对排序任务的状态表示和策略损失,使LR²PPO能够提升标签相关性排序模型的性能,并大幅减少在新场景中转移时对偏序标注的需求。为了辅助评估我们的方法及类似方法,我们进一步提出了一个新的基准数据集LRMovieNet,该数据集特点是包含多模态标签及其相应的偏序数据。广泛的实验表明,我们的LR²PPO算法实现了最先进的性能,证明了其在解决多模态标签相关性排序问题中的有效性。我们将公开代码和所提出的LRMovieNet数据集。
02
Diffumatting:生成任意带有mattIng的四通道物体
DiffuMatting: Synthesizing Arbitrary Objects with Matting-level Annotation
Xiaobin Hu, Xu Peng(厦门大学), Donghao Luo, Xiaozhong Ji, Jinlong Peng, Zhengkai Jiang, Jiangning Zhang,Taisong Jin(厦门大学), Chengjie Wang, and Rongrong Ji(厦门大学)

由于获取高精度或抠图标注非常困难且耗费人力,因此可供公众使用的高精度标签数量有限。为了应对这一挑战,我们提出了一种 DiffuMatting,它继承了扩散强大的万物生成能力,并赋予了“抠图万物”的能力。我们的 DiffuMatting 可以 1). 充当具有高精度标注的万物抠图工厂2). 与社区 LoRA 或各种条件控制方法兼容,实现社区友好的艺术设计和可控生成。具体而言,受绿屏抠图的启发,我们旨在教扩散模型在固定的绿屏画布上绘画。为此,我们收集了一个大规模绿屏数据集 (Green100K) 作为 DiffuMatting 的训练数据集。其次,提出了一种绿色背景控制损失,使绘图板保持纯绿色,以区分前景和背景。为了确保合成的对象具有更多边缘细节,我们提出了一种细节增强的过渡边界损失作为生成具有更复杂边缘结构的对象的标准。为了同时生成对象及其抠图注释,我们构建了一个抠图头,以在 VAE 解码器的潜在空间中去除绿色。我们的 DiffuMatting 展示了几种潜在的应用(例如,抠图数据生成器、社区友好的艺术设计和可控生成)。作为抠图数据生成器,DiffuMatting 合成了一般对象和肖像抠图集,有效地将一般对象抠图任务中的相对 MSE 误差降低了 15.4%,肖像抠图任务中的相对 MSE 误差降低了 11.4%。
项目链接:
https://diffumatting.github.io
03
仅用单张正常图像作为视觉提示学习检测多类异常
Learning to Detect Multi-class Anomalies with Just One Normal Image Prompt
Bin-Bin Gao, Jun Liu, Chengjie Wang, and Yunsheng Wu
自注意力Transformer的无监督重构网络在单一模型进行多类(统一)异常检测方面取得了当前最先进的结果。然而,这些重构模型主要在目标特征本身上进行操作,注意到特征与其临近上下文的一致性使正常特征和异常特征都可能被完美重构,从而导致异常检测失败。此外,由于这些模型在低分辨率的隐空间进行特征重构,常常导致异常分割不够准确。为使重构模型在提高效率的同时增强其对统一异常检测的泛化能力,我们提出了一种简单而有效的方法(OneNIP),该方法仅用单张正常图像作为视觉提示就能重构正常特征并恢复异常特征。与以往工作不同,OneNIP首次允许仅用单张正常图像作为视觉提示来重构正常或恢复异常,有效提升了统一异常检测的性能。此外,我们提出了一个监督式的精调器,它通过使用真实的正常图像和合成的异常图像来回归重构误差,从而显著提高了像素级别的异常分割。OneNIP在三个工业异常检测基准MVTec,BTAD和ViSA上均优于以前方法。我们将开源代码和模型以便于结果重现。
04
基于少样本异常驱动生成的异常分类和分割
Few-Shot Anomaly-Driven Generation for Anomaly Classification and Segmentation
Guan Gui*, Bin-Bin Gao*, Jun Liu, Chengjie Wang, and Yunsheng Wu
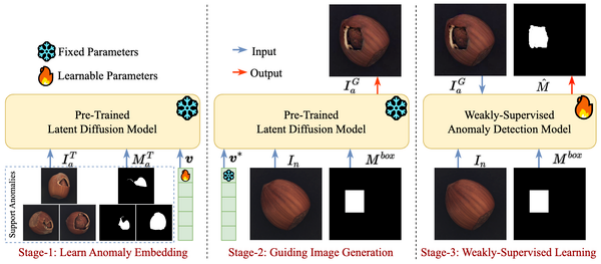
工业质检中异常样本的稀缺性使异常检测(包括分类和分割)成为一项实用且挑战性的任务。一些现有的异常检测方法通过使用噪声或外部数据合成异常来解决这个问题。然而,合成的异常与真实异常之间存在较大的语义差距,导致异常检测的性能较弱。为了解决上述问题,我们提出了一种少样本异常驱动的生成方法,该方法引导扩散模型仅用少量真实异常来生成逼真且多样化的异常,从而有利于训练异常检测模型。具体来说,我们的工作分为三个阶段。在第一阶段,我们基于少量给定的真实异常学习异常分布,并将学习到的知识注入到一个嵌入向量中。在第二阶段,我们使用该嵌入向量和给定的边界框来引导扩散模型在特定的对象上生成真实且多样化的异常。在最后阶段,我们提出了一种弱监督的异常检测方法,用生成的异常来训练一个更强大的异常检测模型。基于DRAEM和DesTSeg基础模型,在常用的工业异常检测数据集MVTec上进行实验。结果表明,我们生成的异常样本有效提高了异常分类和分割任务的性能,例如,DRAEM和DseTSeg在异常分割任务上的AU-PR指标上分别提高5.8%和1.5%。我们将开源代码和生成的异常图像以便于结果重现。
05
频率特征可控融合与显式分解的文档图像篡改检测
Enhancing Tampered Text Detection through Frequency Feature Fusion and Decomposition
Zhongxi Chen(Xiamen University), Shen Chen, Taiping Yao, Ke Sun(Xiamen University), Shouhong Ding, Xianming Lin(Xiamen University), Liujuan Cao(Xiamen University), Rongrong Ji(Xiamen University)
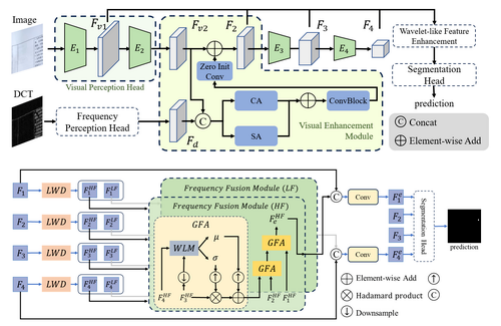
文档图像篡改对信息的真实性构成了严重威胁,其潜在后果包括虚假信息传播、金融欺诈和身份盗窃。现有检测方法通常利用频率信息发现肉眼不可见的篡改痕迹,但它们往往无法恰当地整合这些信息,也无法增强对检测细微篡改至关重要的高频成分。为了解决这些问题,我们提出了一种新的文档图像篡改检测方法——频率特征可控融合与显式分解网络 (FFDN)。我们的方法结合了视觉增强模块 (VEM) 和类小波频率增强 (WFE),以提高对细微篡改痕迹的检测能力。具体而言,视觉增强模块增强了模型对肉眼不可见信息的捕捉,同时保持了原始 RGB 信息的完整性。而类小波频率增强模块则将特征分解为高频和低频分量,来保留并强调小区域的篡改细节。在 DocTamper 数据集上的测试证实了我们方法的优势,其在篡改检测方面明显优于现有方法。
06
TF-FAS: 细粒度双元素语义引导的泛化人脸活体检测
TF-FAS: Twofold-Element Fine-Grained Semantic Guidance for Generalizable Face Anti-Spoofing
Xudong Wang(Xiamen University), Ke-Yue Zhang, Taiping Yao, Qianyu zhou(Shanghai Jiao Tong University), Shouhong Ding, Pingyang Dai(Xiamen University), Rongrong Ji(Xiamen university)
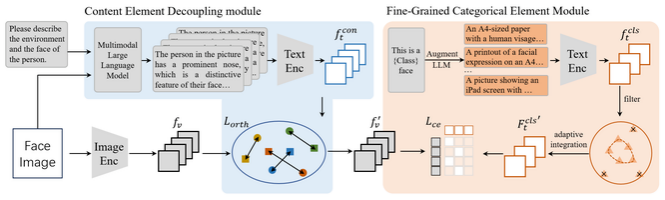
人脸活体检测技术在人脸识别系统的安全方面至关重要,因此其在未知场景中的泛化能力备受关注。尽管一些最新的方法引入视觉-语言模型提升泛化性,但仅使用粗粒度或单一元素提示,未能充分发挥语言监督的潜力,导致泛化能力有限。为此,我们提出TF-FAS框架,通过双重元素细粒度语义指导来增强泛化能力。我们设计内容元素解耦模块(CEDM),全面探索与内容相关的语义元素,并监督类别特征与内容特征的解耦。此外,细粒度类别元素模块(FCEM)则用于探索和整合细粒度的类别元素指导,提升每类数据的分布建模能力。实验结果表明,TF-FAS在各项指标上均优于现有最先进方法,展示了其卓越的性能和广泛的应用前景。
07
Face Adapter:用于预训练扩散模型的细粒度身份和属性控制适配器(高校合作)
Face Adapter for Pre-Trained Diffusion Models with Fine-Grained ID and Attribute Control
Yue Han(Zhejiang University),Junwei Zhu,Keke He, Xu Chen,Yanhao Ge(Vivo), Wei Li(Vivo),Xiangtai Li(Nanyang Technological University),Jiangning Zhang,Chengjie Wang,Yong Liu(Zhejiang University)
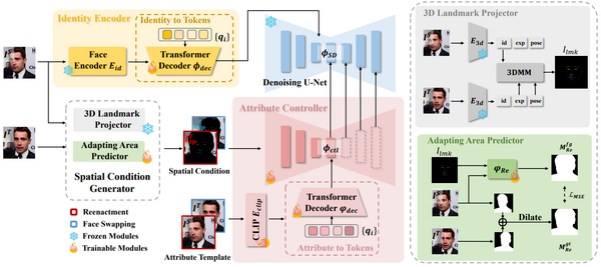
以往的人脸驱动和换脸方法主要依赖于GAN框架,但最近的研究重点已转向扩散模型,因为它们具有更优越的生成能力。然而,训练这些模型需要大量资源,而且结果尚未达到令人满意的水平。为了解决这个问题,我们引入了FaceAdapter,这是一种高效的适配器,专为结合预训练扩散模型实现高精度和高保真度人脸编辑设计。我们观察到,人脸驱动和换脸任务本质上都涉及目标结构、身份和属性的组合。我们希望充分解耦这些因素的控制,以在一个模型中实现这两项任务。具体来说,我们的方法包括:1)一个提供精确关键点和背景的空间条件生成器;2)一个通过transformer解码器将人脸嵌入转移到文本空间的即插即用身份编码器;3)一个整合空间条件和细节属性的属性控制器。与完全微调的人脸驱动/换脸模型相比,FaceAdapter在运动控制精度、身份保留能力和生成质量方面实现了相当甚至更优的性能。此外,FaceAdapter可以无缝集成到各种StableDiffusion模型中。
论文链接:
https://arxiv.org/pdf/2405.12970
08
基于自监督特征适应的3D异常检测(高校合作)
Self-supervised Feature Adaptation for 3D Industrial Anomaly Detection
Yuanpeng Tu(Tongji University), Boshen Zhang, Liang Liu, Yuxi Li, Xuhai Chen(Zhejiang University), Jiangning Zhang, Yabiao Wang, Chengjie Wang, Cai Rong Zhao(Tongji University)
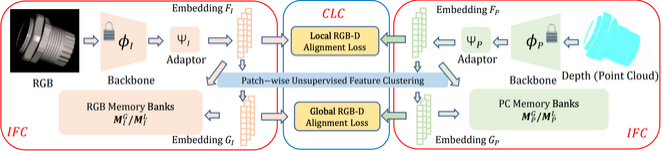
工业异常检测通常被视为一种无监督任务,旨在仅使用正常训练样本定位缺陷。近年来,许多二维异常检测方法被提出并取得了令人满意的结果,然而,仅使用二维RGB数据作为输入不足以识别难以察觉的几何表面异常。因此,本研究聚焦于多模态异常检测。具体而言,我们研究了早期的多模态方法,这些方法尝试利用在大规模视觉数据集(如ImageNet)上预训练的模型来构建特征数据库。我们通过实验证明,直接使用这些预训练模型并非最佳选择,它们可能无法检测到细微缺陷,或将异常特征误认为正常特征。这可能归因于目标工业数据与源数据之间的域差异。针对这一问题,我们提出了一种局部到全局的自监督特征适应(LSFA)方法,以微调适配器并学习面向任务的表示用于异常检测。在LSFA中,从局部到全局的视角优化了模态内适应和跨模态对齐,以确保推理阶段的表示质量和一致性。大量实验表明,我们的方法不仅显著提升了基于特征嵌入的方法的性能,还在MVTec-3D AD和Eyecandies数据集上显著超越了之前的最新方法(SoTA),例如,LSFA在MVTec-3D上实现了97.1%的I-AUROC,比之前的SoTA高出3.4%。
论文链接:
https://arxiv.org/abs/2401.03145
09
AdaCLIP:通过混合可学习提示适应CLIP用于零样本异常检测(高校合作)
AdaCLIP: Adapting CLIP with Hybrid Learnable Prompts for Zero-Shot Anomaly Detection
Yunkang Cao(Huazhong University of Science and Technology), Jiangning Zhang, Luca Frittoli(Politecnico di Milano), Yuqi Cheng(Huazhong University of Science and Technology), Weiming Shen(Huazhong University of Science and Technology), and Giacomo Boracchi(Politecnico di Milano)
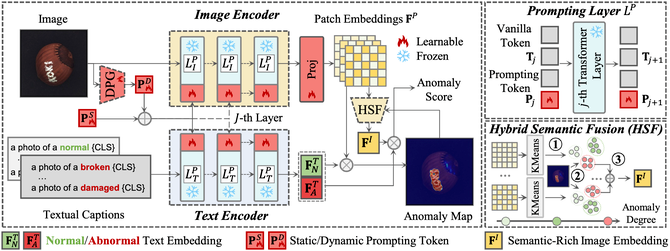
零样本异常检测(ZSAD)旨在识别来自任意新类别图像中的异常。本研究引入了AdaCLIP用于ZSAD任务,利用了预训练的视觉-语言模型(VLM),即CLIP。AdaCLIP在CLIP中引入了可学习提示,并通过在辅助标注的异常检测数据上进行训练来优化这些提示。提出了两种类型的可学习提示:静态提示和动态提示。静态提示在所有图像中共享,用于初步适应CLIP以进行ZSAD。相反,动态提示是为每个测试图像生成的,赋予CLIP动态适应能力。静态和动态提示的结合被称为混合提示,能够提升ZSAD的性能。在工业和医疗领域的14个真实世界异常检测数据集上进行的大量实验表明,AdaCLIP优于其他ZSAD方法,并且在不同类别甚至不同领域中具有更好的泛化能力。最后,我们的分析强调了多样化的辅助数据和优化提示对于增强泛化能力的重要性。
10
基于学习统一参考表示的无监督多类异常检测(高校合作)
Learning Unified Reference Representation for Unsupervised Multi-class Anomaly Detection
Liren He*(Fudan University), Zhengkai Jiang*, Jinlong Peng*, Liang Liu, Qiangang Du(Fudan University), Xiaobin Hu, Wenbing Zhu(Fudan University), Mingmin Chi(Fudan University), Yabiao Wang, Chengjie Wang
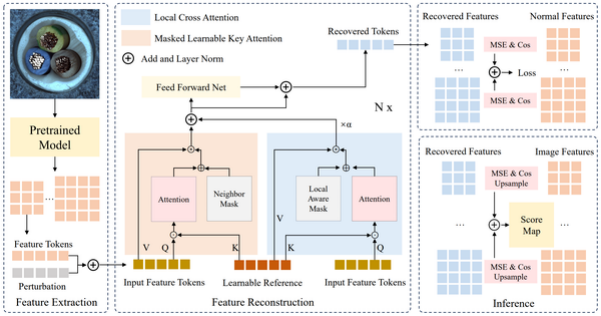
在多类异常检测领域,源自单类异常检测的基于重构的方法面临着一个众所周知的挑战,即“学习捷径”。在这种情况下,模型无法正确学习正常样本的模式,而是选择诸如恒等映射或人为噪声消除等捷径。因此,模型无法将真正的异常重构为正常实例,导致异常检测失败。为了解决这个问题,我们提出了一种新颖的基于统一特征重构的异常检测框架,称为RLR(从可学习的参考表示中重构特征)。与以前的方法不同,RLR利用可学习的参考表示来明确地强迫模型学习正常特征模式,从而防止模型陷入“学习捷径”问题。此外,RLR将局部约束融入可学习的参考中,以促进更有效的正常模式捕捉,并利用掩码可学习的关键注意机制来增强鲁棒性。在15类MVTec-AD数据集和12类VisA数据集上对RLR进行评估,结果显示在统一设置下与现有方法相比具有更优越的性能。
11
无需微调的图文引导图像编辑(高校合作)
Tuning-Free Image Customization with Image and Text Guidance
Pengzhi Li (Tsinghua University), Qiang Nie, Ying Chen, Xi Jiang (Southern University of Science and Technology), Kai Wu, Yuhuan Lin, Yong Liu, Jinlong Peng, Chengjie Wang, Feng Zheng (SUSTech)
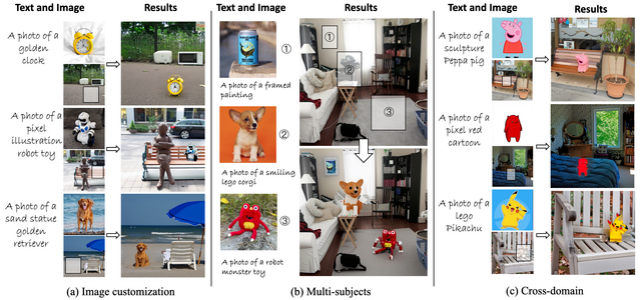
尽管扩散模型在图像定制方面取得了显著进展,但当前的方法仍存在若干局限性:1、在重新生成整个图像时,非目标区域会发生意外变化;2、仅依赖参考图像或文本描述进行指导;3、需要耗时的微调,限制了其实用性。为此,我们引入了一种无需微调的框架,用于同时进行文本-图像引导的图像定制,使得在几秒钟内精确编辑特定图像区域成为可能。我们的方法在允许基于文本描述修改详细属性的同时,保留了参考图像主体的语义特征。为实现这一目标,我们提出了一种创新的注意力混合策略,在去噪过程中将自注意力特征混合到UNet解码器中。据我们所知,这是第一个同时利用文本和图像指导进行特定区域图像定制的无需微调的方法。我们的方法在主观和定量评估中均优于以往的方法,为图像合成、设计和创意摄影等各种实际应用提供了一种高效的解决方案。
论文链接:
https://arxiv.org/abs/2403.12658
12
TexDreamer:零样本高保真3D人体纹理生成(高校合作)
TexDreamer: Towards Zero-Shot High-Fidelity 3D Human Texture Generation
Yufei Liu(Shanghai University), Junwei Zhu, Junshu Tang(Shanghai Jiao Tong University), Shijie Zhang(Fudan University), Jiangning Zhang, Weijian Cao, Chengjie Wang, Yunsheng Wu, Dongjin Huang(Shanghai University)
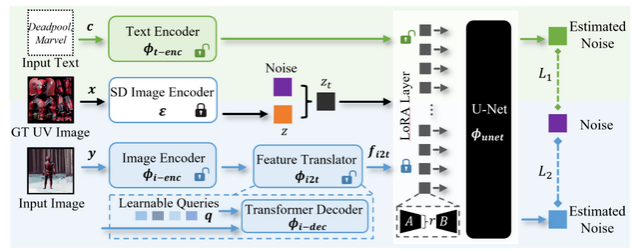
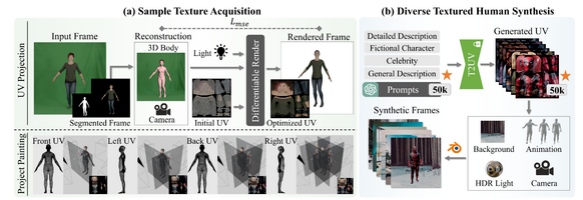
将3D人物纹理与语义UV贴图相结合仍然具有挑战性,因为获取合理展开的UV具有一定难度。尽管最近的文本到3D技术在使用大型文本到图像(T2I)模型监督多视图渲染方面取得了进展,但生成速度、文本一致性和纹理质量方面仍存在问题,导致现有数据集中数据稀缺。我们提出了TexDreamer,这是第一个零样本多模态高保真3D人物纹理生成模型。通过使用高效的纹理适应微调策略,我们将大型T2I模型适应到语义UV结构,同时保留其原始的泛化能力。利用一种新颖的特征转换模块,经过训练的模型能够在几秒钟内从文本或图像生成高保真的3D人物纹理。此外,我们还推出了ArTicuLated humAn textureS (ATLAS),这是一个最大的高分辨率(1,024 × 1,024)3D人物纹理数据集,包含了50,000个具有文本描述的高保真纹理。我们的数据集和模型将可供研究目的使用。
论文链接:
https://arxiv.org/abs/2403.12906
13
AccDiffusion: 精准生成高分辨率图片的方法(高校合作)
AccDiffusion: An Accurate Method for Higher-Resolution Image Generation
Zhihang Lin (Xiamen Univ.), Mingbao Lin (Skywork AI), Meng Zhao, Rongrong Ji (Xiamen Univ.)

本文试图解决在分块方式的高分辨率图像生成中出现的对象重复问题。我们提出了一种名为AccDiffusion的精确方法,无需训练即可生成分块方式的高分辨率图像。本文深度分析了不同的图像块使用相同的文本提示会导致对象的重复生成的问题,但没有提示又会损害图像的细节。因此,我们的AccDiffusion首次提出将普通的图像内容感知提示分解为一组图像块内容感知提示,每个提示都作为图像块的更精确描述。此外,AccDiffusion还引入了带窗口交互的扩张采样,以在高分辨率图像生成中实现更好的全局一致性。与现有方法相比,我们的AccDiffusion有效地解决了重复对象生成的问题,从而在高分辨率图像生成中实现了更好的性能。
14
FreeMotion: 一个用于任意人数的运动生成的统一框架(高校合作)
FreeMotion: A Unified Framework for Number-free Text-to-Motion Synthesis
Ke Fan(Shanghai Jiao Tong University), Junshu Tang(Shanghai Jiao Tong University), Weijian Cao, Ran Yi(Shanghai Jiao Tong University), Moran Li, Jingyu Gong(Shanghai Jiao Tong University), Jiangning Zhang, Yabiao Wang, Chengjie Wang, Lizhuang Ma(Shanghai Jiao Tong University)
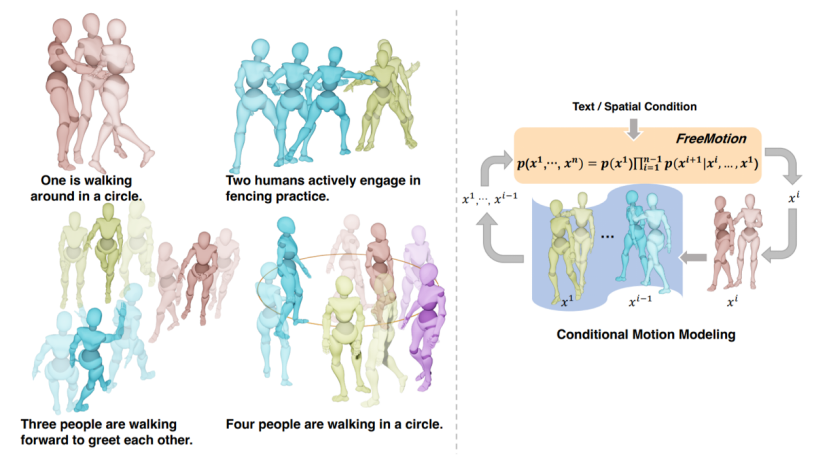
文本至动作合成在计算机视觉中是至关重要的任务。现有的方法在普遍性上受到限制。由于现有方法专门为单人或双人动作生成量身定制,并不能用于生成任意人数(包括1个,2个或者更多个人)的动作。为了实现任意人数的动作合成,本文重新考虑动作生成过程,并提出通过条件动作分布来统一单人和多人动作。此外,我们为FreeMotion框架设计了一个生成模块和一个交互模块,以解耦条件动作生成的过程,并最终支持无数动作合成。此外,基于我们的框架,当前的单人动作控制方法可以无缝集成进来,实现多人动作的精确控制。大量的实验结果证明了我们的方法的优越性能,并且具备推断单人和多人动作的能力。
论文链接:
https://arxiv.org/pdf/2405.15763
本文转载自腾讯优图实验室。
更多ECCV2024论文,请关注
Github:https://github.com/52CV/ECCV-2024-Papers

END
加入「计算机视觉」交流群👇备注:CV
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









