







关注公众号,发现CV技术之美
【写在前面】
在本文中,作者提出了将Swin Transformer缩放到30亿个参数的技术 ,并使其能够使用高达1536×1536分辨率的图像进行训练。通过扩大容量和分辨率,Swin Transformer在四个具有代表性的视觉基准上创造了新的记录:ImageNet-V2图像分类的84.0%top-1 准确度,COCO目标检测上的63.1/54.4box / mask mAP ,ADE20K语义分割的59.9 mIoU ,以及Kinetics-400视频动作分类的86.8%top-1 准确度。目前,视觉模型尚未像NLP语言模型那样被广泛探索,部分原因是训练和应用中的以下差异:
1) 视觉模型通常在规模上面临不稳定性问题;
2) 许多下游视觉任务需要高分辨率图像,如何有效地将低分辨率预训练的模型转换为高分辨率模型尚未被有效探索。当图像分辨率较高时,GPU显存消耗也是一个问题。
为了解决这些问题,作者提出了几种技术,并在本文中以Swin Transformer进行了说明:
1)提高大视觉模型稳定性的后归一化(post normalization) 技术和缩放余弦注意力(scaled cosine attention) 方法;
2)一种对数间隔连续位置偏差技术(log-spaced continuous position bias technique) ,用于有效地将在低分辨率图像中预训练的模型转换为其高分辨率对应模型。
此外,作者还分享了重要的实现细节,这些细节可以显著节省GPU显存消耗,从而使使用常规GPU训练大型视觉模型成为可能。利用这些技术和自监督的预训练,作者成功地训练了一个强大的30亿参数的Swin Transformer模型,并将其有效地迁移到涉及高分辨率图像的各种视觉任务中,在各种基准上实现了SOTA的精度。
1. 论文和代码地址

Swin Transformer V2: Scaling Up Capacity and Resolution
论文地址:https://arxiv.org/abs/2111.09883
代码地址:尚未开源
2. Motivation
扩大语言模型的规模已经取得了成功。它显著地提高了模型在语言任务上的表现,并且该模型展示了与人类相似的Zero-shot能力。BERT大型模型具有3.4亿个参数,语言模型在几年内迅速扩大了1000倍以上,达到5300亿个密集参数和1.6万亿个稀疏参数。
另一方面,视觉模型的扩展一直滞后。虽然人们早就认识到,较大的视觉模型通常在视觉任务上表现得更好,但最近,模型大小刚刚能够达到约10-20亿个参数。更重要的是,与大型语言模型不同,现有的大型视觉模型仅适用于图像分类任务。
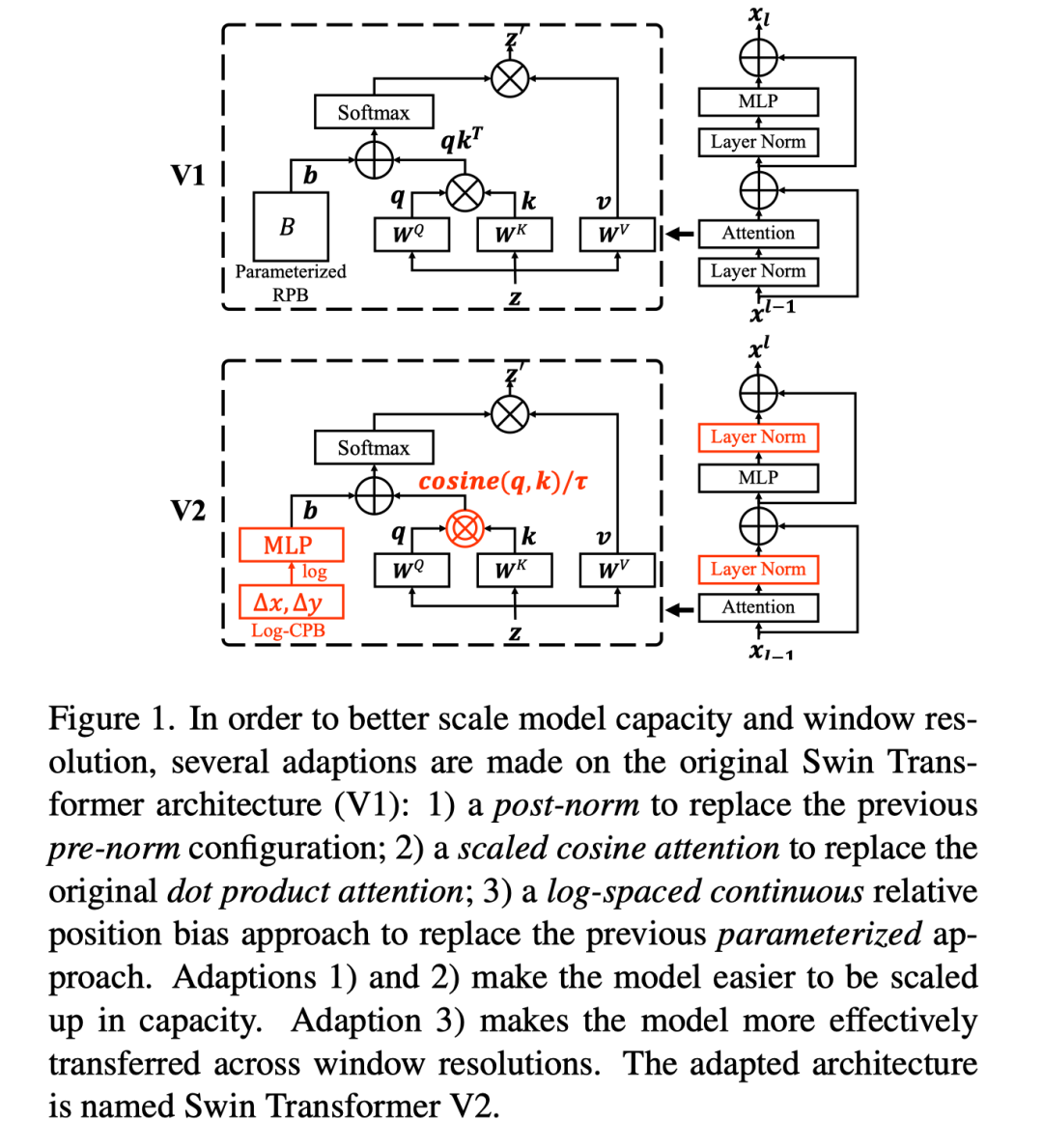
为了成功地训练大型和通用的视觉模型,需要解决几个关键问题。首先,对大型视觉模型的实验揭示了训练中的不稳定性问题。作者发现,在大型模型中,各层之间的激活幅度差异显著增大。仔细观察结构可以发现,这是由直接添加回主分支的残差单元的输出引起的。结果是激活值逐层累积,因此深层的振幅明显大于早期层的振幅。为了解决这个问题,作者提出了一种新的归一化配置,称为post norm,它将LN层从每个残差单元的开始移动到后
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4444
4444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









