







Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration
论文地址
摘要
压缩对于通过流媒体服务、虚拟现实或视频游戏等带宽受限系统高效传输和存储图像和视频起着重要作用。然而,压缩不可避免地会导致伪影和原始信息的丢失,这可能会严重降低视觉质量。由于这些原因,压缩图像的质量增强已成为热门的研究课题。虽然大多数最先进的图像恢复方法都基于卷积神经网络,但其他基于变换器的方法(例如 SwinIR)在这些任务上表现出了令人印象深刻的性能。在本文中,我们探索了新颖的 Swin Transformer V2,以改进图像超分辨率的 SwinIR,特别是压缩输入场景。使用这种方法,我们可以解决训练 transformer 视觉模型的主要问题,例如训练不稳定、预训练和微调之间的分辨率差距以及对数据的渴望。我们对三个代表性任务进行了实验:JPEG 压缩伪影去除、图像超分辨率(经典和轻量级)和压缩图像超分辨率。实验结果表明,我们的方法 Swin2SR 可以提高 SwinIR 的训练收敛性和性能,并且是“AIM 2022 压缩图像和视频超分辨率挑战赛”的前 5 名解决方案。我们的代码可以在 https://github.com/mv-lab/swin2sr。
1 引言
压缩在通过流媒体服务、虚拟现实、图像云存储、视频会议或视频游戏等频带受限系统高效传输和存储图像和视频方面发挥着重要作用。但是,压缩会导致伪影和原始信息的丢失,这可能会严重降低图像的视觉质量。由于这些原因,压缩图像的质量增强和恢复已成为一个流行的重新搜索主题。图像恢复技术,如图像超分辨率(SR)和JPEG压缩伪影减少,旨在从低质量的降级(或压缩)对应物重建高质量的干净图像。在过去的十年中,提出了一些革命性的作品,用于单个图像
超分辨率,其中大多数是基于 CNN 的方法 [17,21,29,32,55,62–68]。我们还可以找到大量建议的方法来减少 JPEG 伪影 [19,28,46]。最近,提出了盲超分辨率 [23,57,63] 方法。他们能够使用一个模型来联合处理超分辨率、去模糊、JPEG 伪影减少等任务。尽管与传统方法相比,这些深度学习方法的性能有了显着提高 [49],但它们通常存在两个问题基本卷积层感受野产生的基本问题:(i)图像和内核之间的交互是内容无关的,因此,使用相同的内核来恢复不同的图像区域可能不是最好的。 (ii) 在局部性原则下,卷积对远程依赖建模[33]无效。作为CNN的替代方案,Transformer [53]设计了一种自我注意机制来捕获上下文之间的全局交互,并表明在几个视觉问题中有前途的表现 [6,18,37,51]。最近,Swin Transformer [37] 显示出巨大的潜力,因为它利用了 CNN 和 Transformers 的优势(即 CNN 由于局部注意机制而处理大尺寸图像,而 Transformer 则通过移动窗口方案)。与经典的基于 CNN 的图像恢复模型相比,基于 Transformer 的方法有几个好处:(i)图像内容和注意力权重之间基于内容的交互,可以解释为空间变化的卷积 [52]。 (ii) 远程依赖建模由移动窗口机制实现。 (iii) 在某些情况下,参数越少性能越好。在这种情况下,梁等人。 SwinIR [33],基于 Swin Transformer [37],代表了基于变压器的图像恢复模型的最新技术水平
AIM 2022 压缩图像和视频超分辨率挑战
这项挑战是为建立 JPEG 图像和视频超分辨率新基准向前迈出的一步。本次挑战中提出的方法也有可能解决各种超分辨率任务。该挑战利用著名的 DIV2K [1] 数据集来评估方法。其他相关挑战,如“压缩视频的超分辨率和质量增强的 NTIRE 2022 挑战”[58、60] 和“真实世界图像 SR 的 NTIRE 2020 挑战”[38] 也代表了该领域的 SOTA。在本文中,我们提出了 Swin2SR,一种基于 SwinV2 Transformer 的模型 [36,37],用于压缩图像超分辨率和恢复。该模型代表了针对这些特定任务的 SwinIR [33] 的可能改进或更新。 SwinV2 [36] (CVPR ’22) 使我们能够解决训练大型基于 transformer 的视觉模型的主要问题,包括训练的不稳定性和持续时间,以及预训练和微调之间的分辨率差距 [33]。我们是第一个成功探索除 Swin Transformer [37] 之外的其他 Transformer 模块用于图像超分辨率和恢复的工作。在某些情况下,我们的模型可以获得与 SwinIR [33] 相似的结果,但训练量减少了 33%。我们还提供了与最先进方法的广泛比较,并在相关的 AIM 2022 挑战赛中取得了有竞争力的结果。
二、相关工作
2.2 Vision Transformer
Swin Transformer V2 [36] 修改了 Swin Attention [37] 模块,以更好地缩放模型容量和窗口分辨率。他们首先用后范数配置替换前范数,使用缩放余弦注意力而不是点积注意力,并使用对数间隔连续相对位置偏差方法来替换以前的参数化方法。注意力输出为:
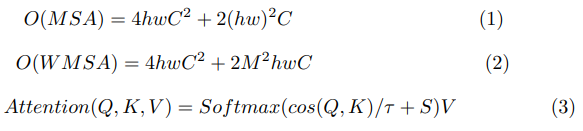
其中 Q,K,V ∈ RM2×d 是查询、键和值矩阵。S ∈ RM2×M2 是通过重新索引后投影位置偏差获得的绝对位置嵌入的相对值。τ 是一个可学习的标量,不跨头部和层共享。该模块如图 1 所示。
三、 我们的方法
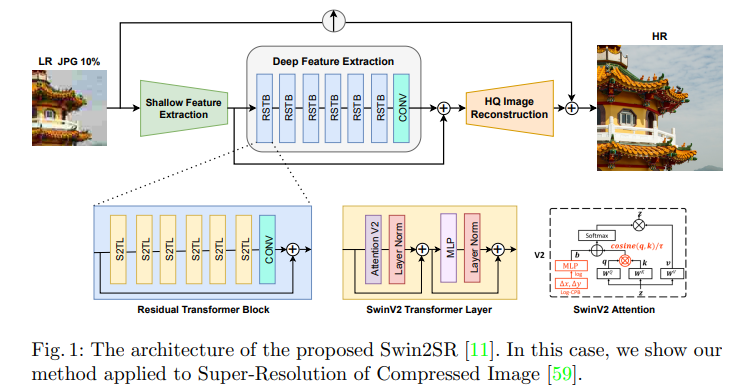
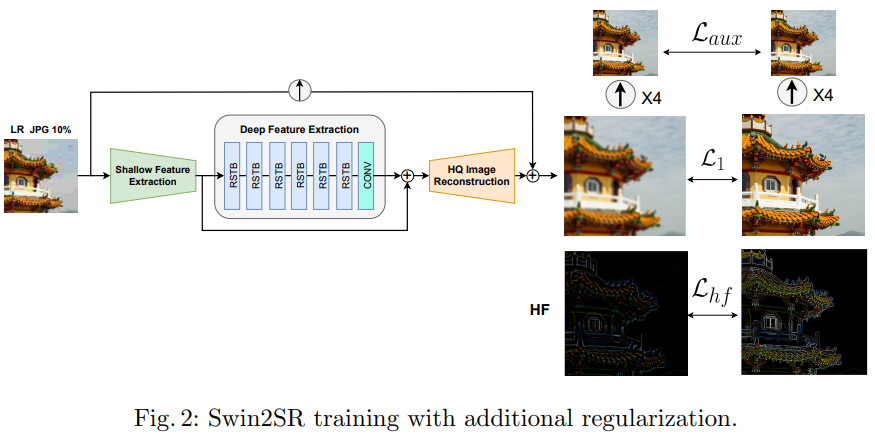
我们的方法 Swin2SR 如图 1 所示。我们提出了一些基于 Swin Transformer [37] 的 SwinIR [33] 的修改,以增强模型的超分辨率能力,特别是压缩输入 SR。我们通过使用新的 SwinV2 transformer [36] (CVPR’22) 层更新原始的 Residual Transformer Block (RSTB) 并注意扩大容量和分辨率 [36]。我们的方法有一个经典的放大分支,它使用双三次插值,如 AIM 2022 挑战排行榜 [59] 和我们的结果 (5) 所示,仅此一项就可以恢复基本的结构信息。出于这个原因,我们模型的输出被添加到基本的放大图像中,以增强它。我们还探索了不同的损失函数,使我们的模型对 JPEG 压缩伪影更加稳健,能够从压缩的 LR 图像中恢复高频细节,从而实现更好的性能。
更新到 SwinV2 的优势
SwinV2 架构修改了移位窗口self-attention 模块,以更好地缩放模型容量和窗口分辨率。使用后归一化而不是预归一化可以减少更深层的平均特征方差并增加训练期间的数值稳定性。这允许将 SwinV2 Transformer 扩展到多达 30 亿个参数,而不会出现训练不稳定性 [36]。在查询和键之间使用缩放余弦注意力而不是点积减少了一些注意力头对少数像素对的支配。在某些任务中,我们的 Swin2SR 模型取得了与 SwinIR [33] 相同的结果,但训练的迭代次数减少了 33%。最后,使用对数间隔的连续相对位置偏差使我们能够在推理时推广到更高的输入分辨率。
3.1 实验设置
为了公平比较并确保可重复性,我们遵循与 SwinIR [33] 和其他最先进方法 [63,70] 相同的实验设置。我们在三个任务上评估我们的模型:JPEG 压缩伪影去除(第 4.1 节),经典和轻量级图像超分辨率(第 4.2 节)和压缩图像超分辨率(第 4.4 节)。我们主要使用 DIV2K 数据集进行训练和验证 [1],并遵循图像 SR 的传统,在 YCbCr 空间的 Y 通道上报告 PSNR 和 SSIM [33,63,70]。我们的模型 Swin2SR 具有以下元素,类似于SwinIR [33]:浅层特征提取、深度特征提取和高质量图像重建模块。浅层特征提取模块使用卷积层提取特征,这些特征直接传输到重建模块以保留低频信息[33,64]。深度特征提取模块主要由 Residual SwinV2 Transformer 块 (RSTB) 组成,每个块利用多个 SwinV2 Transformer [36] 层 (S2TL) 进行局部关注和跨窗口交互。最后,在重建模块中融合了浅层和深层特征,以实现高质量的图像重建。为了放大图像,我们使用标准的像素混洗操作。该架构的超参数如下:RSTB 数、S2TL 数、窗口大小、通道数和注意力头数通常设置为 6、6、8、分别为 180 和 6。对于轻量级图像 SR,我们在第 4.2.
3.2 Implementation details
该方法是在 Pytorch 中实现的,以 https:/github 为基线。 com/cszn/KAIR 和 SwinIR [33] 的官方存储库。我们最初训练Swin2SR 从头开始使用基本的 L1 损失进行重建。在训练时,我们使用 192px 的补丁大小随机裁剪 HR 图像,并相应地裁剪使用 MATLAB 离线生成的 LR 图像,我们还使用标准增强,包括翻转和旋转的所有变化 [50]。我们主要使用 DIV2K [1]。在一些实验中,为了探索更多训练数据的潜在好处,我们还使用了 Flickr2K 数据集(2650 张图像)。在压缩输入超分辨率 [59](第 4.4 节)的特定场景中,我们探索了不同的损失函数以提高我们方法的性能和稳健性;这些在图 2 中表示。首先,我们添加一个 Auxiliary Loss,它最小化下采样预测 y^ 和下采样参考 y.png 之间的 L1 距离,如下所示:
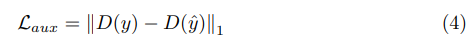
Laux = ∥D(y) − D(y^)∥1 ( 4) 其中 x 是低分辨率退化图像,y 是高分辨率干净图像,f(x) = y^ 是使用我们的模型 f 恢复的图像,D(.) 是下采样算子(即 × 4 双三次核)。这有助于确保在较低分辨率下的一致性。为了最小化Eq。 4 较低分辨率的恢复图像不应该有伪影(即较低分辨率的预测应该接近没有伪影的下采样参考 .png)。其次,我们从高频(HF)中提取高频(HF)信息分辨率图像。这种损失公式如下:
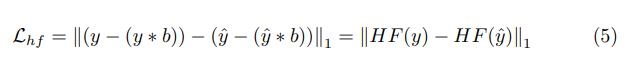
Lhf =∥(y−(y∗b))−(y−(y∗b))∥1 =∥HF(y)−HF(y^)∥1 (5)where HR( .)表示图像的高频信息。为此,我们将一个简单的 5 × 5 内核 b 作为高斯模糊操作进行卷积。该术语强制预测具有与参考相同的高频细节,因此有助于提高结果的清晰度和质量。
5 结论
本文提出了一种基于SwinV2变压器的超分辨率和压缩图像恢复模型Swin2SR。该模型可能是SwinIR(基于Swin Transformer)的改进,允许更快的训练和收敛,以及更大的容量和分辨率。大量实验表明,Swin2SR在以下方面实现了最先进的性能:JPEG压缩伪影去除,图像超分辨率(经典和轻量级)和压缩图像超分辨率。我们的方法还在“AIM 2022压缩图像和视频超分辨率挑战赛”中取得了有竞争力的成绩,跻身前五名,因此,它有助于推进压缩输入超分辨率的最新技术,这将在流媒体服务、虚拟现实或视频游戏等行业中发挥重要作用。














 1671
1671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









