






关注公众号,发现CV技术之美
本文分享由同济大学、新加坡南洋理工大学、新加坡国立大学以及达摩院在CVPR 2022上合作提出的基于时序信息的孪生网络框架 TCTrack: Temporal Contexts for Aerial Tracking。
目的是通过两个维度引入时序信息以更好地实现速度和性能的平衡以应对空中场景带来的挑战。TCTrack通过特征维度及相似度图维度连续整合时序信息。在特征提取过程中,我们通过使用改进的Online TAdaConv在特征维度高效引入时序信息;而在特征图维度,本文使用了更加高效的时序信息策略,通过不断积累的时序信息修正特征图。
最终TCTrack不仅在不使用加速情况下在嵌入式系统达到了实时性的要求,还获得了与其他SOTA跟踪器相似的精度。
详细信息如下:

论文链接:https://arxiv.org/abs/2203.01885
项目链接:https://github.com/vision4robotics/TCTrack
01
问题和挑战
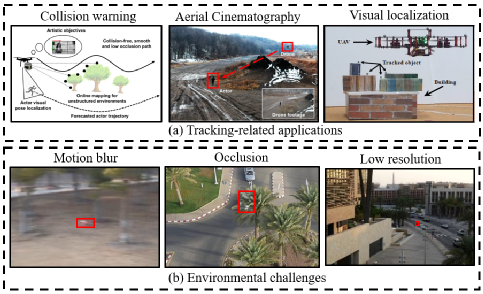
目标跟踪是计算机视觉领域基础任务之一。而得益于无人机等飞行载具的高机动性优势,基于目标跟踪的应用得到越来越快的发展,例如撞击预警,航空摄影,视觉定位等,如图(a)。
而空中场景同样带来了两类挑战:1. 高速和极高的飞行高度带来了诸如运动模糊,频繁遮挡,微小物体等挑战,如图(b);2. 空中载具由于需要保证一定的续航时间,无法携带高性能计算设备,限制了高时间成本的算法。因此开发一种鲁棒且高效的适用于空中跟踪条件的方法仍然是一项具有挑战的工作:
02
方法介绍
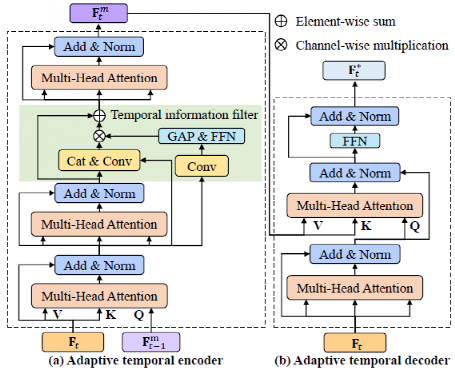
针对以上两类问题,我们提出了一个新颖的基于孪生网络的目标跟踪框架,如下图所示。主要通过两个重要部分组成1)在线的特征提取2)时序自适应的特征图精炼。在这一部分,我们会讲解本文中的 Online TAdaConv 和 AT-Trans 的动机,网络结构和实现细节。
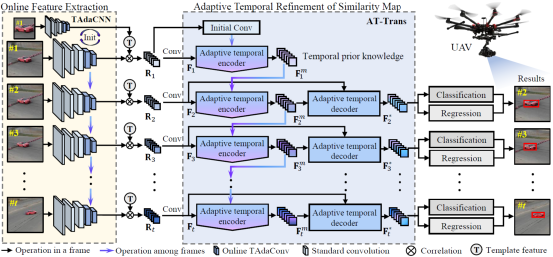
2.1在线的时序自适应卷积
动机:目标跟踪过程中有着丰富时序信息,然而过去的跟踪器在特征提取的过程中每一帧图像都是通过同样的卷积网络提取特征,缺乏对时序信息的建模利用,所以我们希望通过引入时序信息以便提取更加丰富的特征。然而储存过量时序信息会导致内存占用及计算量上升,因此我们最终决定通过在线生成时序调制向量与预训练的卷积核运算来减少相应的计算量。
方法:
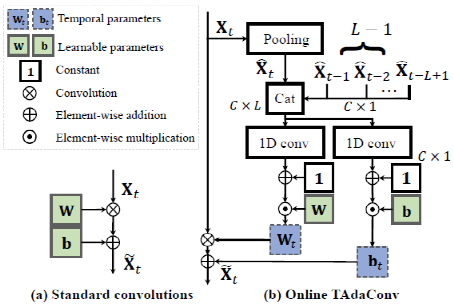
为了方便表达,我们定义第t帧的图像为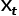 ,经过卷积计算后的结果为
,经过卷积计算后的结果为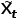 。那么对于标准卷积来说,计算结果可以表示为:
。那么对于标准卷积来说,计算结果可以表示为:
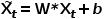
其中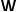 ,
,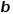 是训练得到的可学习参数,在跟踪过程中对于不同帧并不会改变。
是训练得到的可学习参数,在跟踪过程中对于不同帧并不会改变。
在视频理解中,TAdaConv[1]被提出来以解决视频动作理解中的时序建模问题,而Online TAdaConv是在TAdaConv的基础上改进,以便可以应用到目标跟踪领域。
为了提高运算速度我们首先通过全局平均池化(GAP) 减少输入特征的大小即 。随后将历史信息与当前信息整合后,在时序维度利用卷积计算得到调制向量:
。随后将历史信息与当前信息整合后,在时序维度利用卷积计算得到调制向量:
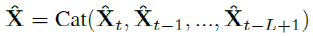
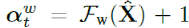
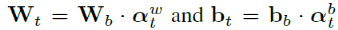
因此最终Online TAdaConv输出结果为:
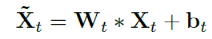
综上所述,Online TAdaConv是跟踪领域第一次尝试在特征提取维度引入时序信息。并且并未引入过多计算量而导致计算延时过长。
Note: 需要注意的是,为了避免调制向量对网络性能产生负影响,1D conv的权重及偏差被初始化为0,即在未训练时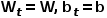 。另外当t≤L-1时,由于没有足够的历史信息,本文使用第一帧信息进行填充(
。另外当t≤L-1时,由于没有足够的历史信息,本文使用第一帧信息进行填充(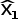 ).
).
2.2时序自适应的特征图精炼
动机:事实上,先前的目标跟踪方法已经试图引入时序信息,比如显式的模板更新[2],基于图的跟踪[3], 时序记忆的整合[4]等等。但是他们融合时序信息的方式大多是间断式的针对特征维度进行融合,通过保存一定量先前的历史信息用以与当前帧融合。这种方式整合了大量时序信息,使得这些跟踪器获得了优异的性能。
但是这种方式并不适用于有计算量限制的空中计算平台。因此本文希望可以提出一种计算量更小,效率更高的引入时序信息的方式。
由于经过互相关操作后的特征图更直接地反映了目标的尺度等信息,相对于特征维度的信息更加丰富,因此本文首次尝试将特征图作为提取时序知识的基体。
另外因为运动具有连续性,我们认为跟踪过程中所有信息都是可以被利用的,即使物体处于被遮挡或模糊的状态。但被环境干扰的特征图需要进行一定的过滤才能有效发挥连续时序信息的优势。
最终基于以上判断,我们设计了固定大小的时序先验知识,通过不断提取旧知识添加到新知识中,再进行信息过滤,以得到当前帧的特征图。而凭借这一策略,我们的框架既利用了时序信息又避免超参数的引入并且限制了内存大小。
方法:作为Transformer的最基本组成,多头注意力公式如下所示,在本文中我们使用了6个分头:

为了表述更加清楚,我们将t-1帧的时序知识定义为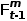 ,当前帧(t帧)为
,当前帧(t帧)为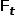 ,则中间结果
,则中间结果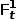 ,
,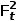 可表示为:
可表示为:
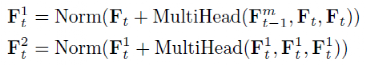
因此信息过滤器的输出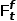 为:
为:
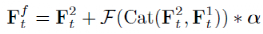
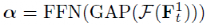
其中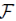 代表卷积层。
代表卷积层。
最终当前帧(t帧)的时序知识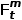 ,及
,及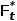 可表示为:
可表示为:
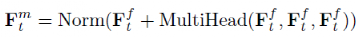
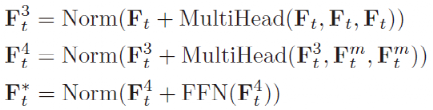
Note: 对于t=1时,考虑到不同物体不同场景具有不同特性,我们使用独立的卷积进行初始化操作而不是使用随机生成的可学习参数。
03
实验结果
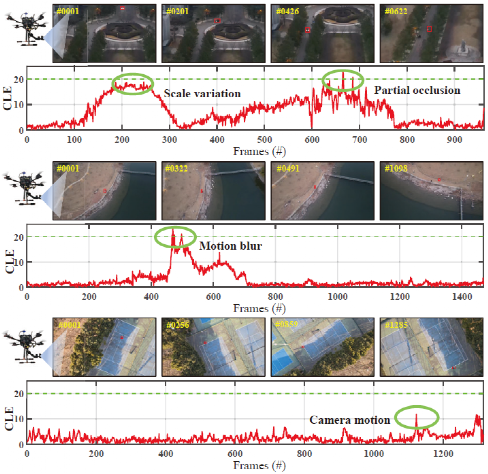
下图为可视效果的对比,可以看出我们的时序建模方式在应对多种空中场景时表现出了足够强的鲁棒性,最终使得跟踪器在多种挑战中得到了性能的提升。

同时我们也进行消融实验的对比,主要分析了关于训练方式(是否采用时序训练)、初始化方式、时序信息基体选择、及TAdaConv信息窗口大小。

SF/MF代表了单帧训练(传统基于检测的跟踪方式)/多帧训练(时序训练),CI/RI代表了基于卷积的初始化/随机初始化,Query列分析了从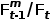 提取时序知识带来的差别。TIF代表了时序信息过滤器。
提取时序知识带来的差别。TIF代表了时序信息过滤器。
消融实验证明了:
仅仅使用时序训练方式而不使用TIF会由于引入噪声而带来负增长,并且TIF对于传统基于检测的跟踪方法依然有信息过滤作用
对不同场景不同物体利用第一帧进行初始化的方式相较于随机可学习参数效果更好
提取t-1帧信息
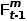 融入当前帧
融入当前帧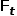 是更好的选择
是更好的选择
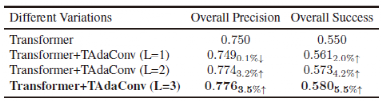
而在针对TAdaConv的分析中,我们选择了L=3作为时序信息的窗口。
为了更好的评估我们方法与SOTA方法的性能,我们将分成两类进行评估。首先针对轻型跟踪器比较,我们的方法在四个公开数据集均取得良好效果。
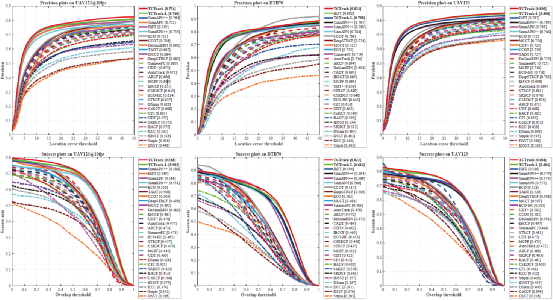
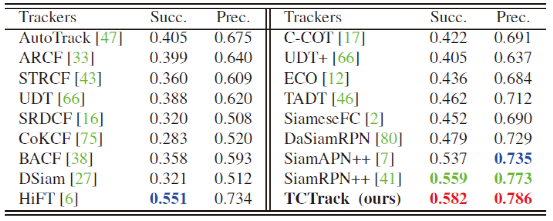
而在与SOTA跟踪器相比,我们的方法保持了相似精度同时,速度达到其2倍以上。

最后为了验证我们的跟踪方法在实际空中条件下的跟踪效果,我们进行了实机测试。我们的跟踪器在真实空中场景下依然保持了高精度和鲁棒性并达到了实时性的要求。
04
结语
在本文中,我们为目标跟踪提出了一种新的高效时序框架。它一方面首次在特征提取(特征维度)高效地引入了时序信息,另一方面通过连续的知识整合避免了超参数及内存占用量的增加。并且多项消融实验和同大量SOTA跟踪器对比中我们证明了该框架的优秀的速度及鲁棒性。最后通过实际机载部署实验有力证明了我们方法的有效性,我们希望这项工作可以为时序目标跟踪提供新的研究思路。
References
[1] Huang Z, Zhang S, Pan L, et al. TAda! Temporally-Adaptive Convolutions for Video Understanding[J]. In ICLR, 2022.
[2] Bin Yan, Houwen Peng, Jianlong Fu, Dong Wang, and Huchuan Lu. Learning Spatio-Temporal Transformer for Visual Tracking. In CVPR, pages 1–10, 2021. 2
[3] Junyu Gao, Tianzhu Zhang, and Changsheng Xu. Graph Convolutional Tracking. In CVPR, pages 4649–4659, 2019.2
[4] Zhihong Fu, Qingjie Liu, Zehua Fu, and Yunhong Wang. STMTrack: Template-free Visual Tracking with Space-time Memory Networks. In CVPR, pages 13774–13783, 2021. 2, 5
推荐阅读
ICLR 2022 TAdaConv:空间卷积也能进行时序推理,高效的视频理解模型TAdaConvNeXt出炉!

EN
欢迎加入「目标跟踪」交流群👇备注:OT
















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









