






关注公众号,发现CV技术之美
本篇分享 CVPR2022 论文『Masked-attention Mask Transformer for Universal Image Segmentation』能同时做三个分割任务的模型,性能和效率优于MaskFormer!Meta&UIUC提出通用分割模型,性能优于任务特定的模型!代码已开源!
详细信息如下:

论文地址:https://arxiv.org/abs/2112.01527[1]
代码地址:https://bowenc0221.github.io/mask2former/[2]
01
摘要
图像分割是关于使用不同语义对像素进行分组,例如类别或实例,其中每个语义选择定义了一个任务。虽然只有每个任务的语义不同,但当前的研究重点是为每个任务设计专门的结构。
作者提出了一种能够处理任何图像分割任务(全景、实例或语义)的新结构——Masked-attention Mask Transformer(Mask2Former)。它的关键组成部分包括掩蔽注意力(masked attention),它通过在预测的mask区域内约束交叉注意力来提取局部特征。除了将研究工作量减少至少三倍外,它在四个流行数据集上的表现也大大优于最好的任务特定的结构。
最值得注意的是,Mask2Former为全景分割(COCO上为57.8 PQ)、实例分割(COCO上为50.1 AP)和语义分割(ADE20K上为57.7 mIoU)任务上达到新的SOTA水平。
02
Motivation
图像分割研究像素分组问题。像素分组的不同语义(例如类别或实例)导致了不同类型的分割任务,例如全景、实例或语义分割。虽然这些任务仅在语义上有所不同,但当前的方法为每个任务开发专门的结构。基于全卷积网络(FCN)的逐像素分类体系结构用于语义分割,而预测一组二进制掩码的掩码分类结构则主导了实例分割。尽管这种专门的结构改进了每个单独的任务,但它们缺乏推广到其他任务的灵活性。例如,基于FCN的结构在实例分割方面存在困难。因此,重复的研究和硬件优化工作花费在每个针对任务的专用结构。
为了解决这种分割问题,最近的工作试图设计通用架构,能够用相同的架构处理所有分割任务(即通用图像分割)。这些结构通常基于端到端集预测目标(例如,DETR),并在不修改结构、损失或训练过程的情况下成功地处理多个任务。注意,尽管具有相同的体系结构,但通用结构仍然针对不同的任务和数据集分别进行训练。除了灵活之外,通用结构最近在语义和全景分割方面显示了最先进的结果。然而,最近的工作仍然集中在推进专用结构上,这就提出了一个问题:为什么通用结构没有取代专用结构?

尽管现有的通用结构足够灵活,可以处理任何细分任务,如上图所示,但在实践中,它们的性能落后于最好的专业结构。除了性能较差之外,通用结构也更难训练。他们通常需要更先进的硬件和更长的训练时间。例如,训练MaskFormer需要300个epoch才能达到40.1 AP,而且它只能在一个32G内存的GPU中容纳一个图像。相比之下,专门的 Swin-HTC++ 仅在72个epoch内获得了更好的性能。性能和训练效率问题都阻碍了通用结构的部署。
在这项工作中,作者提出了一种通用的图像分割体系结构,名为Masked attention Mask Transformer(Mask2Former),它在不同的分割任务中都优于专门的结构,同时在每个任务上都很容易训练。模型建立在一个简单的元架构之上,该架构由主干特征提取器、像素解码器和Transformer解码器组成。作者提出了关键改进,以实现更好的结果和有效的训练。
首先,作者在Transformer解码器中使用掩蔽注意力(masked attention),将注意力限制在以预测片段为中心的局部特征上,这些预测片段可以是对象,也可以是区域,具体取决于分组的特定语义。与标准Transformer解码器中使用的交叉注意力相比,本文的掩蔽注意力可以更快地收敛,并提高性能。
其次,作者使用多尺度高分辨率特征来帮助模型分割小对象/区域。
第三,作者提出了一些优化改进,如切换自注意力和交叉注意力的顺序,使查询特征可学习,以及消除遗漏;所有这些都可以在无需额外计算的情况下提高性能。最后,在不影响性能的情况下,通过计算随机采样点上的掩码损失,节省了3×训练显存。这些改进不仅提高了模型的性能,而且使训练变得非常容易,使通用结构更容易为计算能力有限的用户所使用。
作者使用四个流行的数据集(COCO、Cityscapes、ADE20K和Mapillary Vistas)评估了Mask2Former在三种图像分割任务(全景、实例和语义分割)上的表现。在所有这些基准上,本文的单一结构的性能首次达到或优于专门结构。Mask2Former采用完全相同的结构,在COCO全景分割上达到了57.8 PQ的SOTA水平,在COCO实例分割上达到了50.1 AP,在ADE20K语义分割上达到了57.7 mIoU。
03
方法
3.1. Mask classification preliminaries
掩码分类结构通过预测N个二进制掩码以及N个相应的类别标签,将像素分组为N个片段。掩码分类具有足够的通用性,可以通过为不同的片段(segment)分配不同的语义(例如类别或实例)来解决任何分割任务。然而,挑战在于为每个分割任务找到良好的表现。例如,Mask RCNN使用边界框作为表示,这限制了其应用于语义分割。
受DETR的启发,图像中的每个片段都可以表示为C维特征向量(“对象查询”),并可以由Transformer解码器进行处理,使用设定的预测目标进行训练。一个简单的元结构将由三个组件组成:从图像中提取低分辨率特征的主干网络;从主干输出中逐渐向上采样低分辨率特征,以生成高分辨率的每像素嵌入的像素解码器;对图像特征进行操作以处理对象查询的Transformer解码器。最终的二进制掩码预测是通过对象查询从每像素嵌入解码的。这种元结构的一个成功实例是MaskFormer。
3.2. Transformer decoder with masked attention
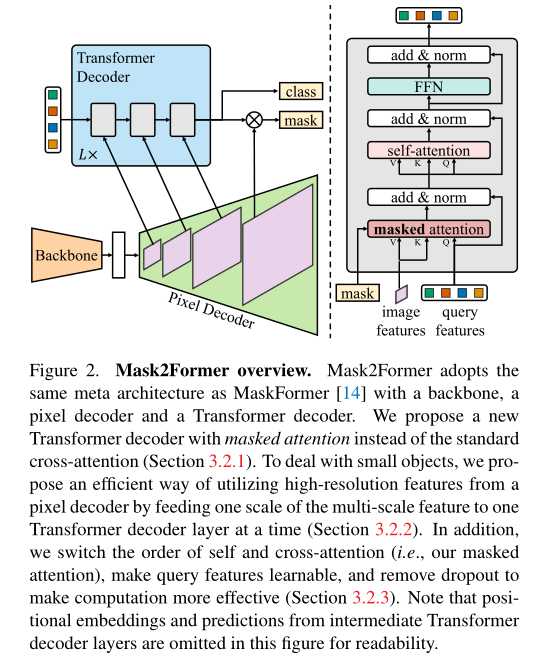
Mask2Former采用上述元结构,本文提出的Transformer解码器(上图右)取代了标准解码器。Transformer解码器的关键组件包括一个masked attention算子,该算子通过将交叉注意力限制在每个查询的预测mask的前景区域内来提取局部特征,而不是attend完整的特征映射。为了处理小对象,作者提出了一种有效的多尺度策略来利用高分辨率特征。它以循环方式将像素解码器的特征金字塔中的连续特征映射馈送到连续的Transformer解码器层中。最后,作者加入了优化改进,在不引入额外计算的情况下提高了模型性能。
3.2.1 Masked attention
上下文特征对于图像分割非常重要。然而,最近的研究表明,基于Transformer的模型收敛缓慢是由于交叉注意力层中的全局环境,因为交叉注意力需要训练许多epoch才能学会关注局部对象区域。作者认为局部特征足以更新查询特征,并且上下文信息可以通过自注意收集。为此,作者提出了掩蔽注意力(masked attention),这是交叉注意力的一种变体,只出现在每个查询的预测mask的前景区域内。
标准交叉注意力(带残差路径)计算为:

这里,l是层下标,表示第l层的N个C维查询特性,。表示Transformer解码器的输入查询特征。分别是和变换下的图像特征,和是图像特征的空间分辨率。,和是线性变换。
本文的mask注意力通过以下方式调节注意力矩阵:

此外,attention mask在特征位置(x,y)处的值为:
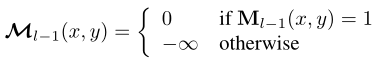
其中,是l-1层Transformer解码器层的二进制输出(阈值为0.5)。它的大小调整为与相同的分辨率。
3.2.2 High-resolution features
高分辨率特征提高了模型性能,尤其是对于小对象而言。然而,这在计算上要求很高。因此,作者提出了一种有效的多尺度策略来引入高分辨率特征,同时控制计算量的增加。作者不总是使用高分辨率的特征映射,而是使用由低分辨率和高分辨率特征组成的特征金字塔,并将多尺度特征的一个分辨率一次送给一个Transformer解码器层。
具体来说,作者使用像素解码器生成的特征金字塔,分辨率为原始图像的1/32、1/16和1/8。对于每个分辨率,作者都添加了正弦位置嵌入,以及可学习的scale-level嵌入。从最低分辨率到最高分辨率,用于对应的Transformer解码器层,如上图左所示。重复这个三层Transformer解码器L次。因此,最终的Transformer解码器具有3L层。
更具体地说,前三层接收分辨率为
402 Payment Required
和 的特征图,其中H和W是原始图像分辨率。对于下面的所有层,此模式以循环方式重复。3.2.3 Optimization improvements
标准Transformer解码器层由三个模块组成,按以下顺序处理查询特征:自注意力模块、交叉注意力和前馈网络(FFN)。此外,查询特征()在被送入Transformer解码器之前是零初始化的,并且与可学习的位置嵌入相关联。此外,dropout应用于残差连接和attention map。
为了优化Transformer解码器的设计,作者进行了以下三项改进。首先,切换自注意力和交叉注意力的顺序(即masked attention)以提高计算效率:第一个自注意层的查询特征还不依赖于图像特征,因此应用自注意不会生成任何有意义的特征。
其次,使查询特征()也可学习(仍然保留可学习的查询位置嵌入),并且可学习的查询特征在用于Transformer解码器预测mask()之前直接被监督。作者发现这些可学习的查询特征的功能类似于region proposal网络,并且能够生成mask proposal。最后,作者发现dropout是不必要的,通常会降低性能。因此,作者完全消除了解码器中的dropout。
3.3. Improving training efficiency
训练通用架构的一个限制是,由于高分辨率mask预测,显存消耗很大,使得它们比显存友好的专用架构更难使用。例如,MaskFormer只能在具有32G显存的GPU中放单个图像。受PointRend和Implicit PointRend的启发,作者在匹配和最终损失计算中都使用采样点计算mask损失。
具体地说,在为二部匹配构建cost矩阵的匹配损失中,作者为所有预测和ground truth mask统一采样相同的K点集。在预测与其匹配的ground truth之间的最终损失中,作者使用重要性抽样对不同预测和ground truth的不同K个点集进行抽样。其中,设置K=12544,即112×112点。这种新的训练策略有效地将训练显存减少了3倍,从每幅图像18GB减少到6GB。
04
实验

在上表中,作者将Mask2Former与COCO全景分割数据集上最先进的全景分割模型进行了比较。Mask2Former在不同的主干上始终比MaskFormer高出5个PQ以上,同时收敛速度快6倍。
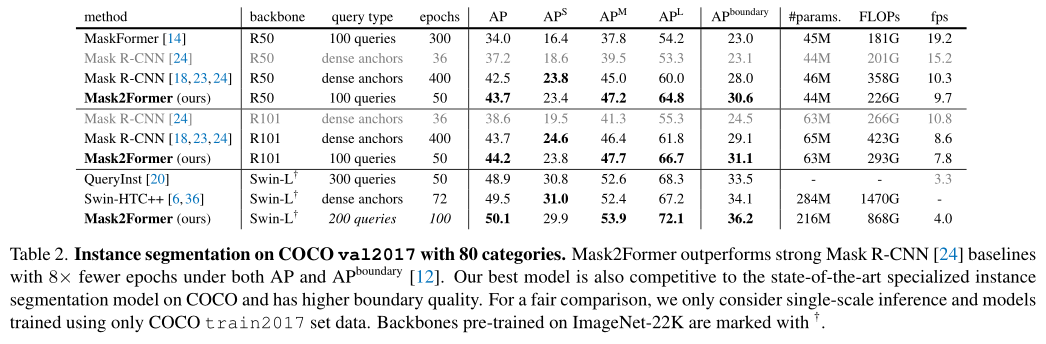
在上表中,作者将Mask2Former与COCO实例分割数据集上的最新模型进行了比较。借助ResNet主干网络,Mask2Former在使用large-scale jittering(LSJ)增强的情况下,性能优于Mask R-CNN,同时需要8×更少的训练迭代。凭借Swin-L主干网络,Mask2Former的性能优于最先进的HTC++。
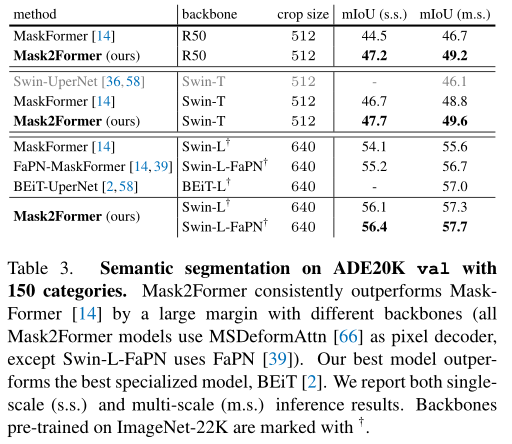
上表中,作者将Mask2Former与ADE20K数据集上最先进的语义分割模型进行了比较。Mask2Former在不同主干上的表现都优于MaskFormer,这表明所提出的改进甚至提高了语义分割的结果。
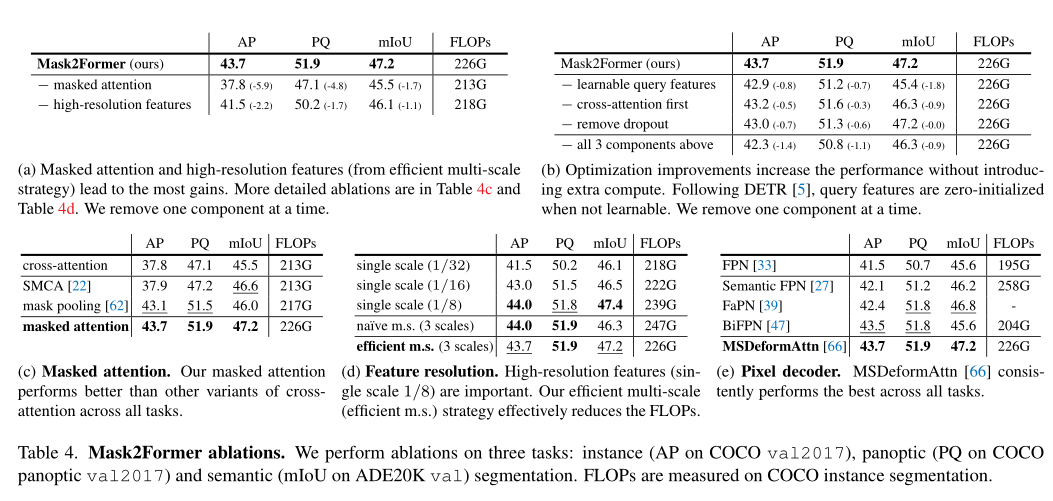
上表展示了本文提出模块的消融实验结果,可以看出,本文中提出的模块对于分割的准确率和效率都有促进作用。

作者在上表中研究了基于掩码或采样点计算损失对性能和训练显存的影响。使用采样点计算最终的训练损失,可以在不影响性能的情况下将训练显存减少3倍。此外,使用采样点计算匹配损失可以提高所有三个任务的性能。
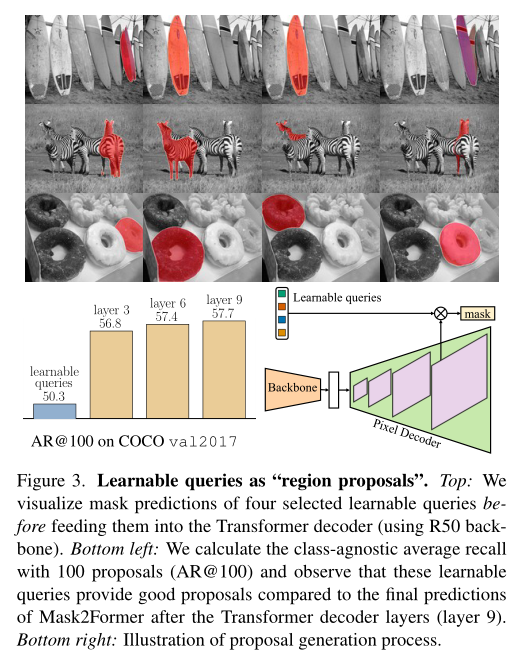
在上图中,作者将选定的可学习查询的掩码预测可视化,然后再将其输入Transformer解码器。通过计算COCO val2017上100个预测的类不可知平均recall,进一步对这些proposal的质量进行了定量分析。可以看出,这些可学习的查询已经达到了非常好的效果。

为了证明本文的Mask2Former可以推广到COCO数据集之外,作者进一步在其他流行的图像分割数据集上进行了实验。在上表中,作者显示了Cityscapes的结果。
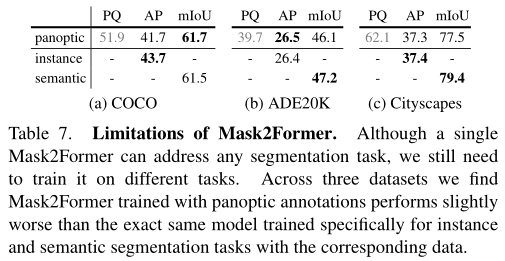
本文的最终目标是为所有图像分割任务训练一个单一模型。在上表中,作者发现在全景分割上训练的Mask2Former只比在三个数据集上使用相应标注训练的完全相同的模型表现稍差,例如语义分割任务。这表明,尽管Mask2Former可以推广到不同的任务,但仍需要针对这些特定任务进行训练。
05
总结
作者提出了用于通用图像分割的Mask2Former。Mask2Former建立在一个简单的元框架的基础上,使用了一个新的Transformer解码器,该解码器使用了提议的masked attention,在四个流行的数据集上,在所有三个主要的图像分割任务(全景、实例和语义)中都取得了最好的结果,甚至超过了为每个基准设计的最好的专门模型,同时保持了易于训练的性能。与为每个任务设计专用模型相比,Mask2Former节省了3倍的研究工作量,并且用户可以使用有限的计算资源使用它。
参考资料
[1]https://arxiv.org/abs/2112.01527
[2]https://bowenc0221.github.io/mask2former/

END
欢迎加入「图像分割」交流群👇备注:分割















 6638
6638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









